 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelation-Aware Pyramid Network (RapNet) for temporal action proposal
Aug 09, 2019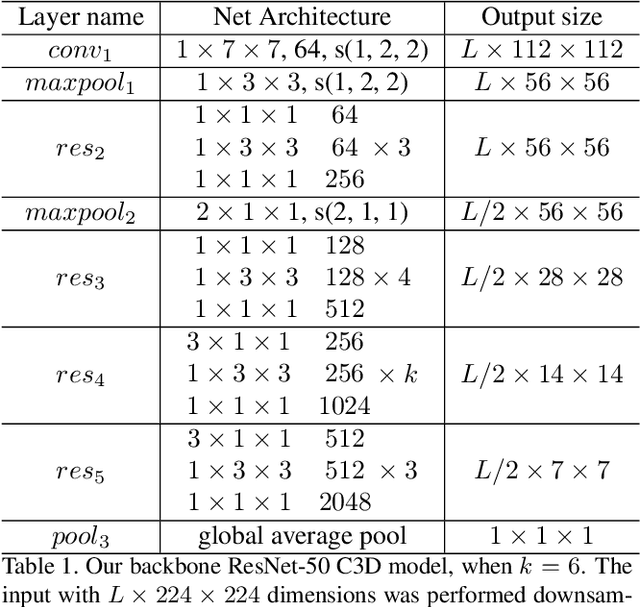
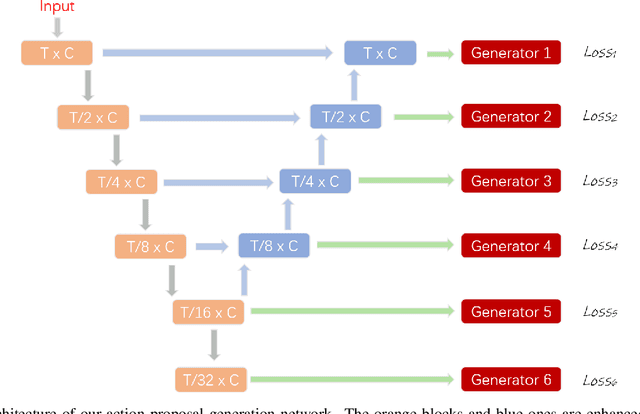
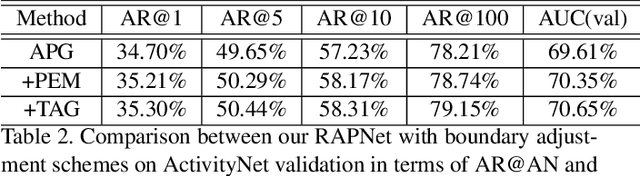
In this technical report, we describe our solution to temporal action proposal (task 1) in ActivityNet Challenge 2019. First, we fine-tune a ResNet-50-C3D CNN on ActivityNet v1.3 based on Kinetics pretrained model to extract snippet-level video representations and then we design a Relation-Aware Pyramid Network (RapNet) to generate temporal multiscale proposals with confidence score. After that, we employ a two-stage snippet-level boundary adjustment scheme to re-rank the order of generated proposals. Ensemble methods are also been used to improve the performance of our solution, which helps us achieve 2nd place.
DSReg: Using Distant Supervision as a Regularizer
May 30, 2019
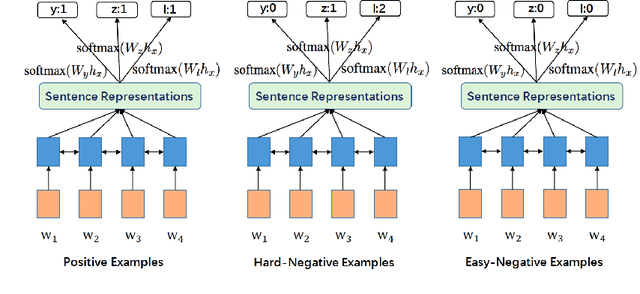
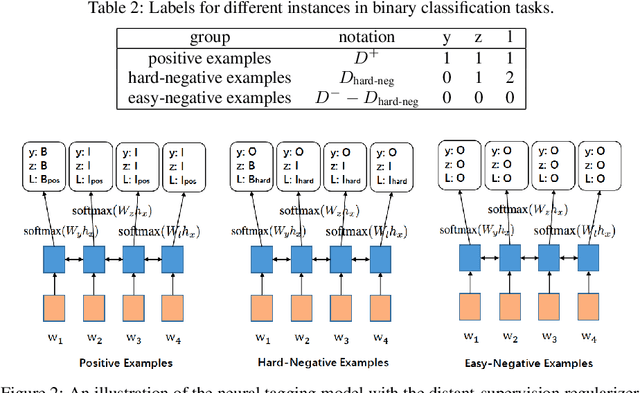
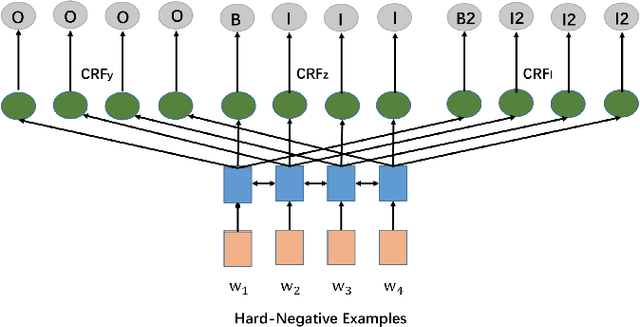
In this paper, we aim at tackling a general issue in NLP tasks where some of the negative examples are highly similar to the positive examples, i.e., hard-negative examples. We propose the distant supervision as a regularizer (DSReg) approach to tackle this issue. The original task is converted to a multi-task learning problem, in which distant supervision is used to retrieve hard-negative examples. The obtained hard-negative examples are then used as a regularizer. The original target objective of distinguishing positive examples from negative examples is jointly optimized with the auxiliary task objective of distinguishing softened positive (i.e., hard-negative examples plus positive examples) from easy-negative examples. In the neural context, this can be done by outputting the same representation from the last neural layer to different $softmax$ functions. Using this strategy, we can improve the performance of baseline models in a range of different NLP tasks, including text classification, sequence labeling and reading comprehension.
Entity-Relation Extraction as Multi-Turn Question Answering
May 24, 2019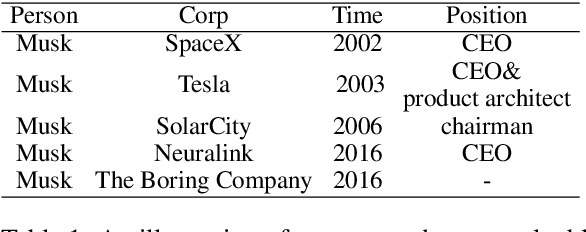
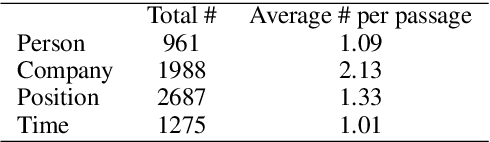
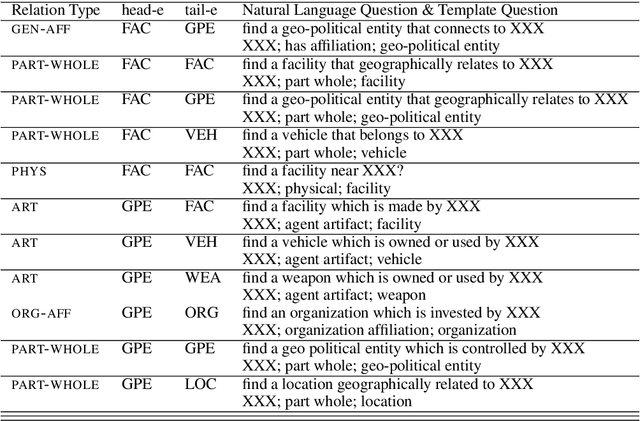

In this paper, we propose a new paradigm for the task of entity-relation extraction. We cast the task as a multi-turn question answering problem, i.e., the extraction of entities and relations is transformed to the task of identifying answer spans from the context. This multi-turn QA formalization comes with several key advantages: firstly, the question query encodes important information for the entity/relation class we want to identify; secondly, QA provides a natural way of jointly modeling entity and relation; and thirdly, it allows us to exploit the well developed machine reading comprehension (MRC) models. Experiments on the ACE and the CoNLL04 corpora demonstrate that the proposed paradigm significantly outperforms previous best models. We are able to obtain the state-of-the-art results on all of the ACE04, ACE05 and CoNLL04 datasets, increasing the SOTA results on the three datasets to 49.4 (+1.0), 60.2 (+0.6) and 68.9 (+2.1), respectively. Additionally, we construct a newly developed dataset RESUME in Chinese, which requires multi-step reasoning to construct entity dependencies, as opposed to the single-step dependency extraction in the triplet exaction in previous datasets. The proposed multi-turn QA model also achieves the best performance on the RESUME dataset.
Is Word Segmentation Necessary for Deep Learning of Chinese Representations?
May 14, 2019
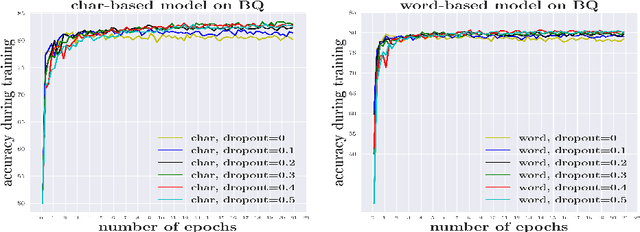

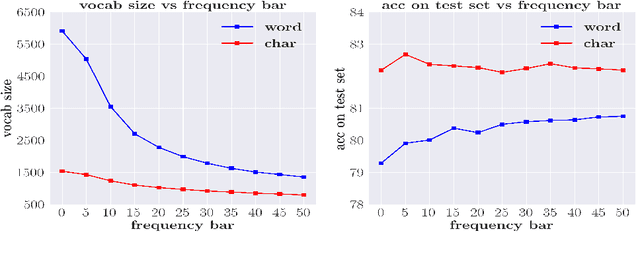
Segmenting a chunk of text into words is usually the first step of processing Chinese text, but its necessity has rarely been explored. In this paper, we ask the fundamental question of whether Chinese word segmentation (CWS) is necessary for deep learning-based Chinese Natural Language Processing. We benchmark neural word-based models which rely on word segmentation against neural char-based models which do not involve word segmentation in four end-to-end NLP benchmark tasks: language modeling, machine translation, sentence matching/paraphrase and text classification. Through direct comparisons between these two types of models, we find that char-based models consistently outperform word-based models. Based on these observations, we conduct comprehensive experiments to study why word-based models underperform char-based models in these deep learning-based NLP tasks. We show that it is because word-based models are more vulnerable to data sparsity and the presence of out-of-vocabulary (OOV) words, and thus more prone to overfitting. We hope this paper could encourage researchers in the community to rethink the necessity of word segmentation in deep learning-based Chinese Natural Language Processing. \footnote{Yuxian Meng and Xiaoya Li contributed equally to this paper.}
DenseBody: Directly Regressing Dense 3D Human Pose and Shape From a Single Color Image
Mar 28, 2019
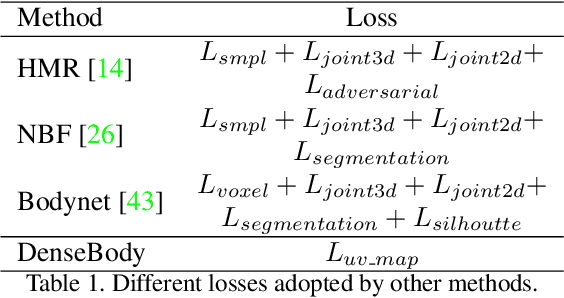
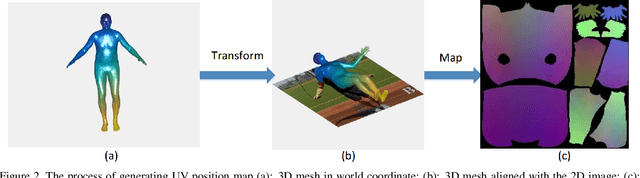
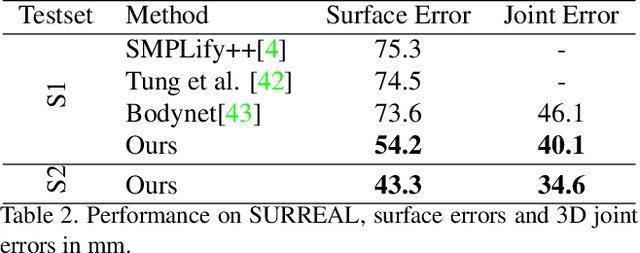
Recovering 3D human body shape and pose from 2D images is a challenging task due to high complexity and flexibility of human body, and relatively less 3D labeled data. Previous methods addressing these issues typically rely on predicting intermediate results such as body part segmentation, 2D/3D joints, silhouette mask to decompose the problem into multiple sub-tasks in order to utilize more 2D labels. Most previous works incorporated parametric body shape model in their methods and predict parameters in low-dimensional space to represent human body. In this paper, we propose to directly regress the 3D human mesh from a single color image using Convolutional Neural Network(CNN). We use an efficient representation of 3D human shape and pose which can be predicted through an encoder-decoder neural network. The proposed method achieves state-of-the-art performance on several 3D human body datasets including Human3.6M, SURREAL and UP-3D with even faster running speed.
Glyce: Glyph-vectors for Chinese Character Representations
Jan 29, 2019

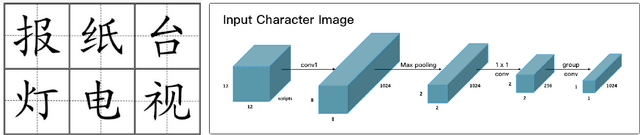
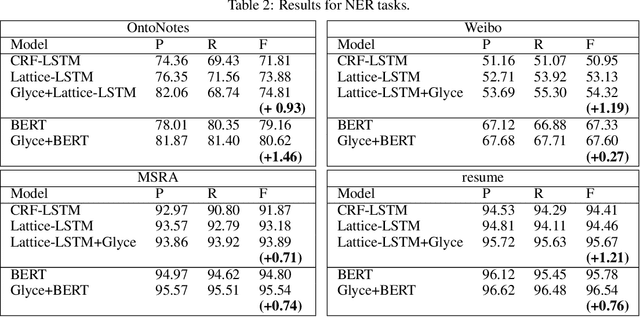
It is intuitive that NLP tasks for logographic languages like Chinese should benefit from the use of the glyph information in those languages. However, due to the lack of rich pictographic evidence in glyphs and the weak generalization ability of standard computer vision models on character data, an effective way to utilize the glyph information remains to be found. In this paper, we address this gap by presenting the Glyce, the glyph-vectors for Chinese character representations. We make three major innovations: (1) We use historical Chinese scripts (e.g., bronzeware script, seal script, traditional Chinese, etc) to enrich the pictographic evidence in characters; (2) We design CNN structures tailored to Chinese character image processing; and (3) We use image-classification as an auxiliary task in a multi-task learning setup to increase the model's ability to generalize. For the first time, we show that glyph-based models are able to consistently outperform word/char ID-based models in a wide range of Chinese NLP tasks. Using Glyce, we are able to achieve the state-of-the-art performances on 13 (almost all) Chinese NLP tasks, including (1) character-Level language modeling, (2) word-Level language modeling, (3) Chinese word segmentation, (4) name entity recognition, (5) part-of-speech tagging, (6) dependency parsing, (7) semantic role labeling, (8) sentence semantic similarity, (9) sentence intention identification, (10) Chinese-English machine translation, (11) sentiment analysis, (12) document classification and (13) discourse parsing
One Shot Domain Adaptation for Person Re-Identification
Nov 26, 2018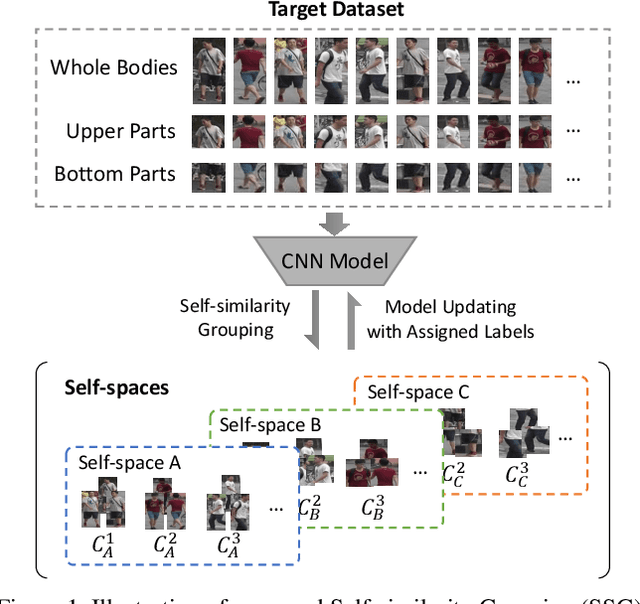
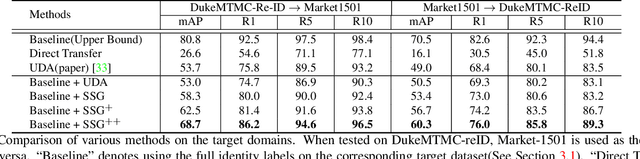
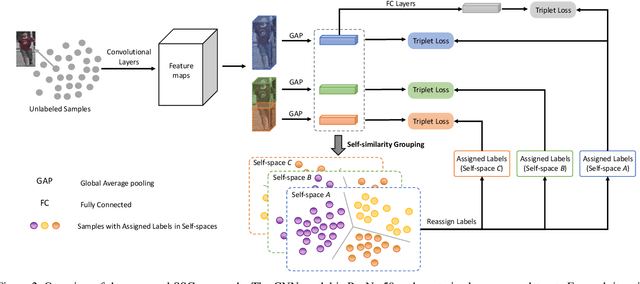
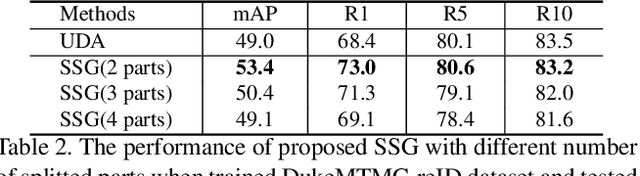
How to effectively address the domain adaptation problem is a challenging task for person re-identification (reID). In this work, we make the first endeavour to tackle this issue according to one shot learning. Given an annotated source training set and a target training set that only one instance for each category is annotated, we aim to achieve competitive re-ID performance on the testing set of the target domain. To this end, we introduce a similarity-guided strategy to progressively assign pseudo labels to unlabeled instances with different confidence scores, which are in turn leveraged as weights to guide the optimization as training goes on. Collaborating with a simple self-mining operation, we make significant improvement in the domain adaptation tasks of re-ID. In particular, we achieve the mAP of 71.5% in the adaptation task of DukeMTMC-reID to Market1501 with one shot setting, which outperforms the state-of-arts of unsupervised domain adaptation more than 17.8%. Under the five shots setting, we achieve competitive accuracy of the fully supervised setting on Market-1501. Code will be made available.
Pixel-Anchor: A Fast Oriented Scene Text Detector with Combined Networks
Nov 19, 2018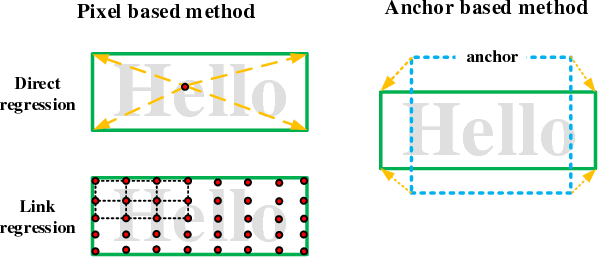
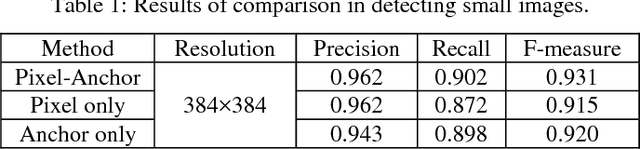

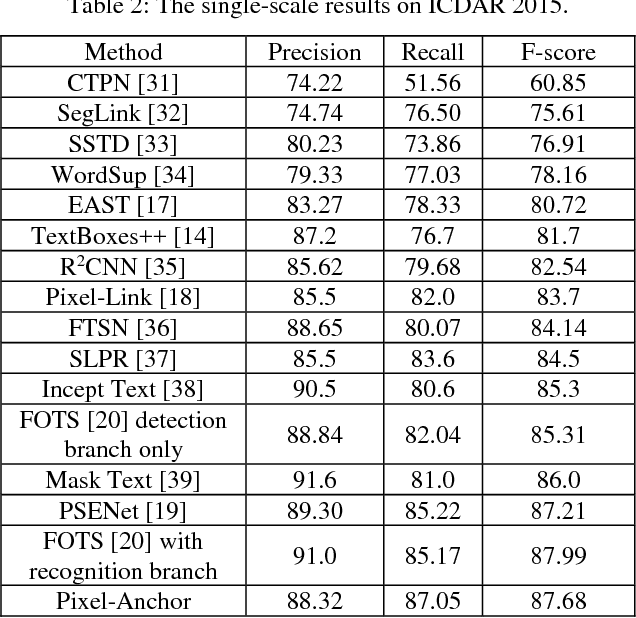
Recently, semantic segmentation and general object detection frameworks have been widely adopted by scene text detecting tasks. However, both of them alone have obvious shortcomings in practice. In this paper, we propose a novel end-to-end trainable deep neural network framework, named Pixel-Anchor, which combines semantic segmentation and SSD in one network by feature sharing and anchor-level attention mechanism to detect oriented scene text. To deal with scene text which has large variances in size and aspect ratio, we combine FPN and ASPP operation as our encoder-decoder structure in the semantic segmentation part, and propose a novel Adaptive Predictor Layer in the SSD. Pixel-Anchor detects scene text in a single network forward pass, no complex post-processing other than an efficient fusion Non-Maximum Suppression is involved. We have benchmarked the proposed Pixel-Anchor on the public datasets. Pixel-Anchor outperforms the competing methods in terms of text localization accuracy and run speed, more specifically, on the ICDAR 2015 dataset, the proposed algorithm achieves an F-score of 0.8768 at 10 FPS for 960 x 1728 resolution images.
Cascaded CNN-resBiLSTM-CTC: An End-to-End Acoustic Model For Speech Recognition
Oct 30, 2018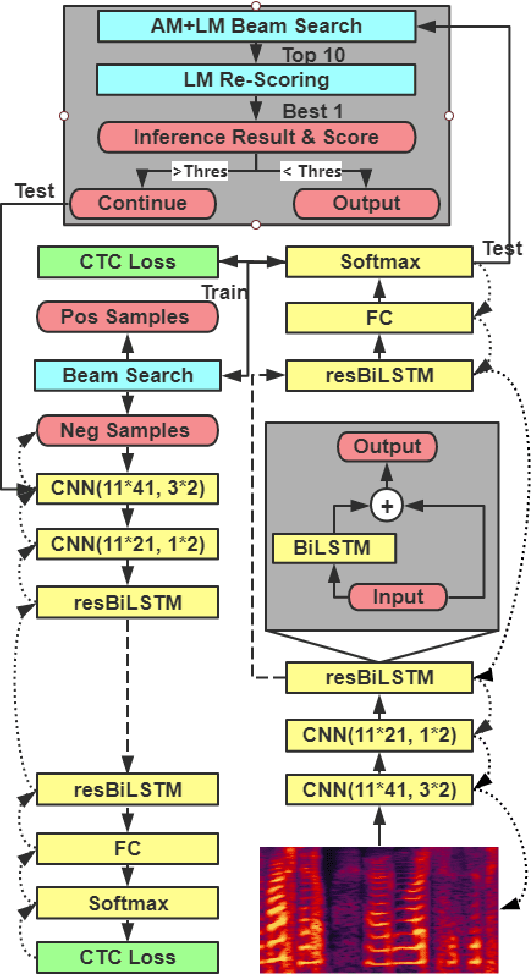
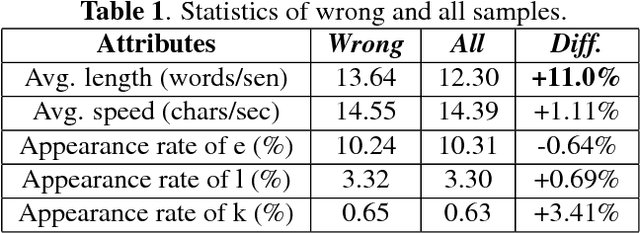
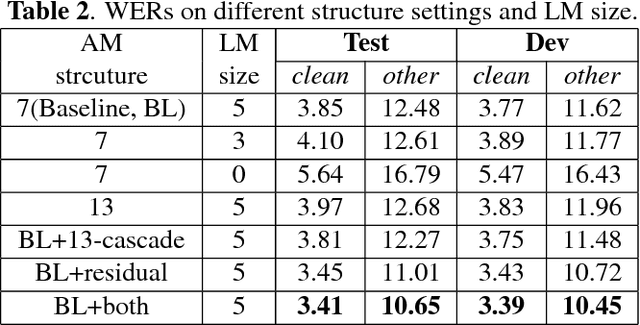
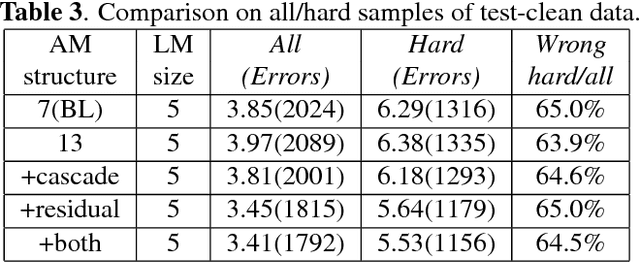
Automatic speech recognition (ASR) tasks are resolved by end-to-end deep learning models, which benefits us by less preparation of raw data, and easier transformation between languages. We propose a novel end-to-end deep learning model architecture namely cascaded CNN-resBiLSTM-CTC. In the proposed model, we add residual blocks in BiLSTM layers to extract sophisticated phoneme and semantic information together, and apply cascaded structure to pay more attention mining information of hard negative samples. By applying both simple Fast Fourier Transform (FFT) technique and n-gram language model (LM) rescoring method, we manage to achieve word error rate (WER) of 3.41% on LibriSpeech test clean corpora. Furthermore, we propose a new batch-varied method to speed up the training process in length-varied tasks, which result in 25% less training time.
Generating More Interesting Responses in Neural Conversation Models with Distributional Constraints
Sep 04, 2018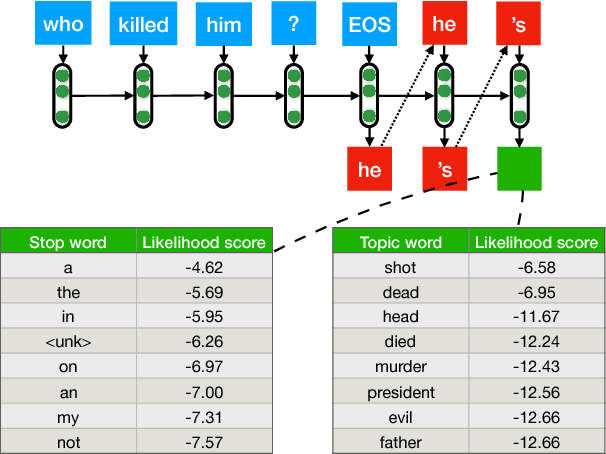
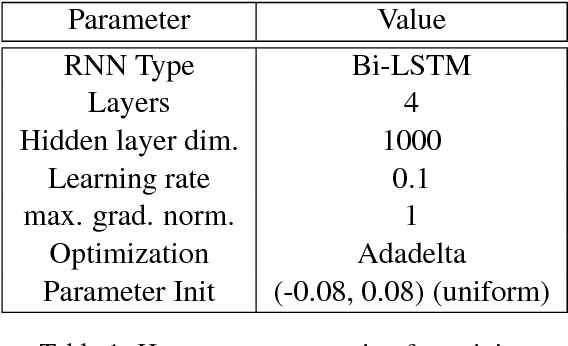
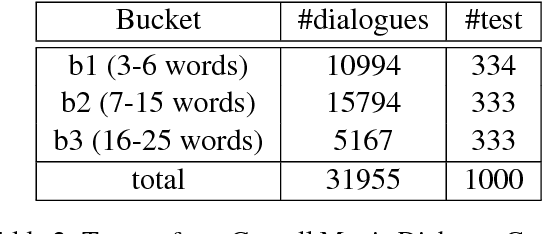
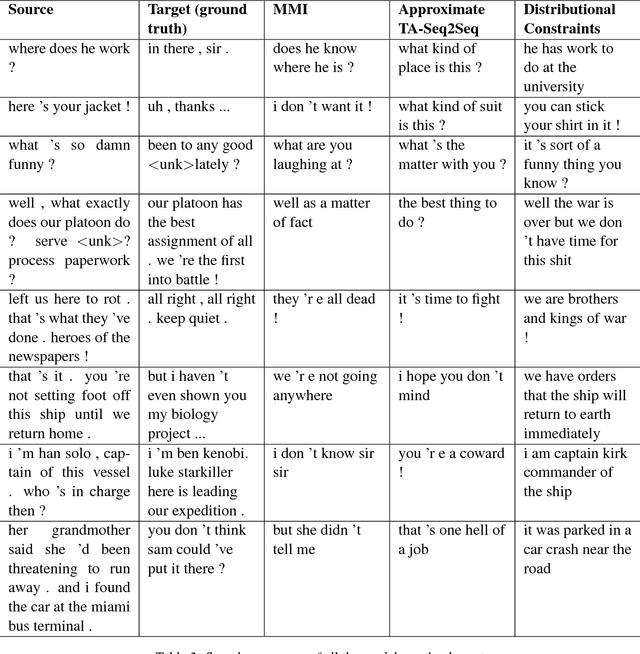
Neural conversation models tend to generate safe, generic responses for most inputs. This is due to the limitations of likelihood-based decoding objectives in generation tasks with diverse outputs, such as conversation. To address this challenge, we propose a simple yet effective approach for incorporating side information in the form of distributional constraints over the generated responses. We propose two constraints that help generate more content rich responses that are based on a model of syntax and topics (Griffiths et al., 2005) and semantic similarity (Arora et al., 2016). We evaluate our approach against a variety of competitive baselines, using both automatic metrics and human judgments, showing that our proposed approach generates responses that are much less generic without sacrificing plausibility. A working demo of our code can be found at https://github.com/abaheti95/DC-NeuralConversation.