 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCascaded CNN-resBiLSTM-CTC: An End-to-End Acoustic Model For Speech Recognition
Oct 30, 2018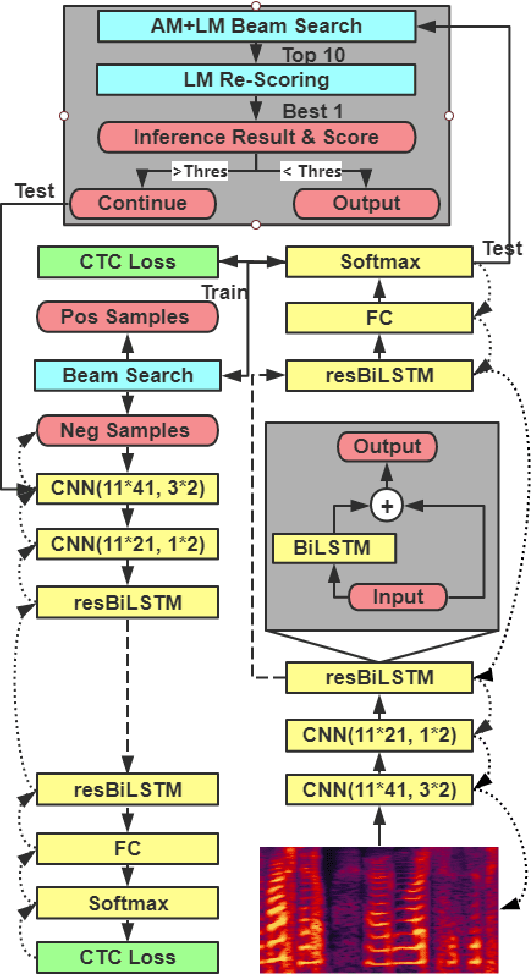
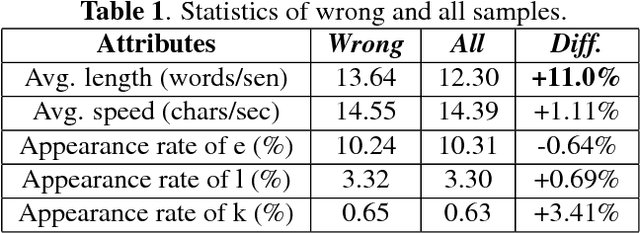
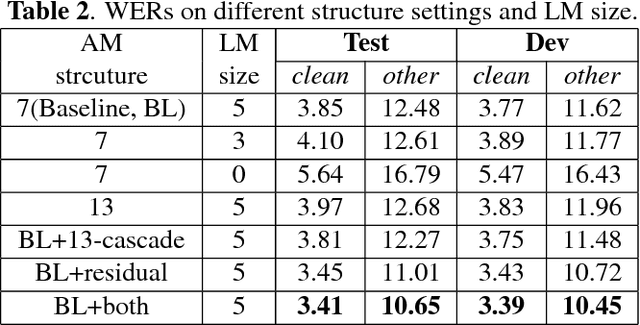
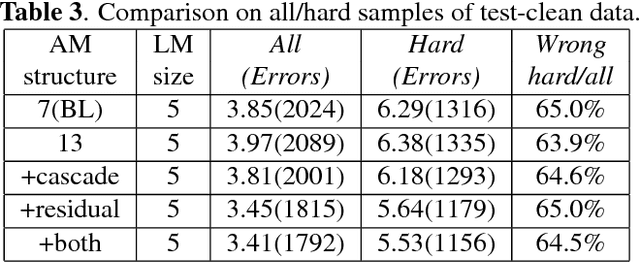
Automatic speech recognition (ASR) tasks are resolved by end-to-end deep learning models, which benefits us by less preparation of raw data, and easier transformation between languages. We propose a novel end-to-end deep learning model architecture namely cascaded CNN-resBiLSTM-CTC. In the proposed model, we add residual blocks in BiLSTM layers to extract sophisticated phoneme and semantic information together, and apply cascaded structure to pay more attention mining information of hard negative samples. By applying both simple Fast Fourier Transform (FFT) technique and n-gram language model (LM) rescoring method, we manage to achieve word error rate (WER) of 3.41% on LibriSpeech test clean corpora. Furthermore, we propose a new batch-varied method to speed up the training process in length-varied tasks, which result in 25% less training time.