 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate and Stable Test-Time Adaptation with Differential Privacy
Jun 01, 2026Test-time adaptation (TTA) can reduce error on new and different data by updating the model on these inputs during inference. However, these updates raise the issue of privacy w.r.t. the testing data, because the model parameters now depend on all past inputs. To control this privacy risk, we cast multiple popular TTA methods (Tent, EATA, SAR, DeYO, and COME) into differential privacy (DP) forms that apply per-sample gradient clipping and Gaussian noise for all updates. On ImageNet-C, our DP-TTA methods provide adequate privacy at small cost to accuracy, and in the low-privacy regime the clipping mechanism of DP can even improve the accuracy and stability of adaptation in the continual setting. These improvements to privacy and accuracy come at only modest computational overhead. These first results on private TTA raise awareness of the issue, inform the development of more private test-time updates, and identify per-sample clipping as an effective technique for improving the accuracy and stability of adaptation.
A Closer Look at In-Distribution vs. Out-of-Distribution Accuracy for Open-Set Test-time Adaptation
Jun 01, 2026Open-set test-time adaptation (TTA) updates models on new data in the presence of input shifts and unknown output classes. While recent methods have made progress on improving in-distribution (InD) accuracy for known classes, their ability to accurately detect out-of-distribution (OOD) unknown classes remains underexplored. We benchmark robust and open-set TTA methods (SAR, OSTTA, UniEnt, and SoTTA) on the standard corruption benchmarks of CIFAR-10-C at the small scale and ImageNet-C at the large scale. For CIFAR-10-C, we use OOD data from SVHN and CIFAR-100 in their respective corrupted forms of SVHN-C and CIFAR-100-C. For ImageNet-C, we use OOD data from ImageNet-O and Textures in their respective corrupted forms of ImageNet-O-C and Textures-C. ImageNet-O is nearer to ImageNet, as unknown but related object classes (like ''garlic bread'' vs. ''hot dog'' for food, or ''highway'' vs. ''dam'' for infrastructure), while Textures is farther from ImageNet, as non-object patterns (like ''cracked'' mud, ''porous'' sponge, ''veined'' leaves). We evaluate the accuracy and confidence of TTA methods for InD vs. OOD recognition on CIFAR-10-C and ImageNet-C. We verify the accuracy of each method's own OOD detection technique on CIFAR-10-C. We also evaluate on ImageNet-C and report both accuracy and standard OOD detection metrics. We further examine more realistic settings, in which the proportions and rates of OOD data can vary. To explore the trade-off between InD recognition and OOD rejection, we propose a new baseline that replaces softmax/multi-class output with sigmoid/multi-label output. Our analysis shows for the first time that current open-set TTA methods struggle to balance InD and OOD accuracy and that they only imperfectly filter OOD data for their own adaptation updates.
Masked Generative Transformer Is What You Need for Image Editing
May 11, 2026Diffusion models dominate image editing, yet their global denoising mechanism entangles edited regions with surrounding context, causing modifications to propagate into areas that should remain intact. We propose a fundamentally different approach by leveraging Masked Generative Transformers (MGTs), whose localized token-prediction paradigm naturally confines changes to intended regions. We present EditMGT, an MGT-based editing framework that is the first of its kind. Our approach employs multi-layer attention consolidation to aggregate cross-attention maps into precise edit localization signals, and region-hold sampling to explicitly prevent token flipping in non-target areas. To support training, we construct CrispEdit-2M, a 2M-sample high-resolution (>1024) editing dataset spanning seven categories. With only 960M parameters, EditMGT achieves state-of-the-art image similarity on multiple benchmarks while delivering 6x faster editing, demonstrating that MGTs offer a compelling alternative to diffusion-based editing.
TRACE: A Multi-Agent System for Autonomous Physical Reasoning in Seismological Science
Mar 22, 2026Inferring the physical mechanisms that govern earthquake sequences from indirect geophysical observations remains difficult, particularly across tectonically distinct environments where similar seismic patterns can reflect different underlying processes. Current interpretations rely heavily on the expert synthesis of catalogs, spatiotemporal statistics, and candidate physical models, limiting reproducibility and the systematic transfer of insight across settings. Here we present TRACE (Trans-perspective Reasoning and Automated Comprehensive Evaluator), a multi-agent system that combines large language model planning with formal seismological constraints to derive auditable, physically grounded mechanistic inference from raw observations. Applied to the 2019 Ridgecrest sequence, TRACE autonomously identifies stress-perturbation-induced delayed triggering, resolving the cascading interaction between the Mw 6.4 and Mw 7.1 mainshocks; in the Santorini-Kolumbo case, the system identifies a structurally guided intrusion model, distinguishing fault-channeled episodic migration from the continuous propagation expected in homogeneous crustal failure. By providing a generalizable logical infrastructure for interpreting heterogeneous seismic phenomena, TRACE advances the field from expert-dependent analysis toward knowledge-guided autonomous discovery in Earth sciences.
UniDWM: Towards a Unified Driving World Model via Multifaceted Representation Learning
Feb 02, 2026Achieving reliable and efficient planning in complex driving environments requires a model that can reason over the scene's geometry, appearance, and dynamics. We present UniDWM, a unified driving world model that advances autonomous driving through multifaceted representation learning. UniDWM constructs a structure- and dynamic-aware latent world representation that serves as a physically grounded state space, enabling consistent reasoning across perception, prediction, and planning. Specifically, a joint reconstruction pathway learns to recover the scene's structure, including geometry and visual texture, while a collaborative generation framework leverages a conditional diffusion transformer to forecast future world evolution within the latent space. Furthermore, we show that our UniDWM can be deemed as a variation of VAE, which provides theoretical guidance for the multifaceted representation learning. Extensive experiments demonstrate the effectiveness of UniDWM in trajectory planning, 4D reconstruction and generation, highlighting the potential of multifaceted world representations as a foundation for unified driving intelligence. The code will be publicly available at https://github.com/Say2L/UniDWM.
EditMGT: Unleashing Potentials of Masked Generative Transformers in Image Editing
Dec 12, 2025Recent advances in diffusion models (DMs) have achieved exceptional visual quality in image editing tasks. However, the global denoising dynamics of DMs inherently conflate local editing targets with the full-image context, leading to unintended modifications in non-target regions. In this paper, we shift our attention beyond DMs and turn to Masked Generative Transformers (MGTs) as an alternative approach to tackle this challenge. By predicting multiple masked tokens rather than holistic refinement, MGTs exhibit a localized decoding paradigm that endows them with the inherent capacity to explicitly preserve non-relevant regions during the editing process. Building upon this insight, we introduce the first MGT-based image editing framework, termed EditMGT. We first demonstrate that MGT's cross-attention maps provide informative localization signals for localizing edit-relevant regions and devise a multi-layer attention consolidation scheme that refines these maps to achieve fine-grained and precise localization. On top of these adaptive localization results, we introduce region-hold sampling, which restricts token flipping within low-attention areas to suppress spurious edits, thereby confining modifications to the intended target regions and preserving the integrity of surrounding non-target areas. To train EditMGT, we construct CrispEdit-2M, a high-resolution dataset spanning seven diverse editing categories. Without introducing additional parameters, we adapt a pre-trained text-to-image MGT into an image editing model through attention injection. Extensive experiments across four standard benchmarks demonstrate that, with fewer than 1B parameters, our model achieves similarity performance while enabling 6 times faster editing. Moreover, it delivers comparable or superior editing quality, with improvements of 3.6% and 17.6% on style change and style transfer tasks, respectively.
Denoised Recommendation Model with Collaborative Signal Decoupling
Nov 06, 2025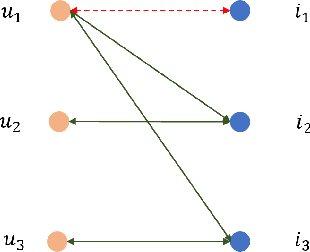
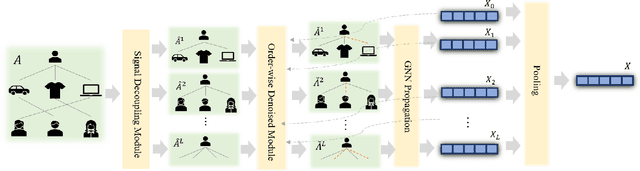
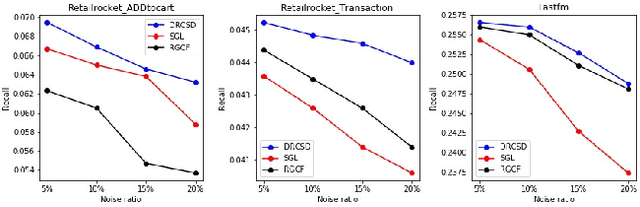
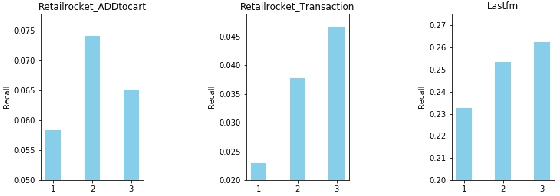
Although the collaborative filtering (CF) algorithm has achieved remarkable performance in recommendation systems, it suffers from suboptimal recommendation performance due to noise in the user-item interaction matrix. Numerous noise-removal studies have improved recommendation models, but most existing approaches conduct denoising on a single graph. This may cause attenuation of collaborative signals: removing edges between two nodes can interrupt paths between other nodes, weakening path-dependent collaborative information. To address these limitations, this study proposes a novel GNN-based CF model called DRCSD for denoising unstable interactions. DRCSD includes two core modules: a collaborative signal decoupling module (decomposes signals into distinct orders by structural characteristics) and an order-wise denoising module (performs targeted denoising on each order). Additionally, the information aggregation mechanism of traditional GNN-based CF models is modified to avoid cross-order signal interference until the final pooling operation. Extensive experiments on three public real-world datasets show that DRCSD has superior robustness against unstable interactions and achieves statistically significant performance improvements in recommendation accuracy metrics compared to state-of-the-art baseline models.
GroundingGPT:Language Enhanced Multi-modal Grounding Model
Jan 30, 2024



Multi-modal large language models have demonstrated impressive performance across various tasks in different modalities. However, existing multi-modal models primarily emphasize capturing global information within each modality while neglecting the importance of perceiving local information across modalities. Consequently, these models lack the ability to effectively understand the fine-grained details of input data, limiting their performance in tasks that require a more nuanced understanding. To address this limitation, there is a compelling need to develop models that enable fine-grained understanding across multiple modalities, thereby enhancing their applicability to a wide range of tasks. In this paper, we propose GroundingGPT, a language enhanced multi-modal grounding model. Beyond capturing global information like other multi-modal models, our proposed model excels at tasks demanding a detailed understanding of local information within the input. It demonstrates precise identification and localization of specific regions in images or moments in videos. To achieve this objective, we design a diversified dataset construction pipeline, resulting in a multi-modal, multi-granularity dataset for model training. The code, dataset, and demo of our model can be found at https: //github.com/lzw-lzw/GroundingGPT.
SeisCLIP: A seismology foundation model pre-trained by multi-modal data for multi-purpose seismic feature extraction
Sep 05, 2023



Training specific deep learning models for particular tasks is common across various domains within seismology. However, this approach encounters two limitations: inadequate labeled data for certain tasks and limited generalization across regions. To address these challenges, we develop SeisCLIP, a seismology foundation model trained through contrastive learning from multi-modal data. It consists of a transformer encoder for extracting crucial features from time-frequency seismic spectrum and an MLP encoder for integrating the phase and source information of the same event. These encoders are jointly pre-trained on a vast dataset and the spectrum encoder is subsequently fine-tuned on smaller datasets for various downstream tasks. Notably, SeisCLIP's performance surpasses that of baseline methods in event classification, localization, and focal mechanism analysis tasks, employing distinct datasets from different regions. In conclusion, SeisCLIP holds significant potential as a foundational model in the field of seismology, paving the way for innovative directions in foundation-model-based seismology research.
Multi-task multi-station earthquake monitoring: An all-in-one seismic Phase picking, Location, and Association Network (PLAN)
Jun 24, 2023



Earthquake monitoring is vital for understanding the physics of earthquakes and assessing seismic hazards. A standard monitoring workflow includes the interrelated and interdependent tasks of phase picking, association, and location. Although deep learning methods have been successfully applied to earthquake monitoring, they mostly address the tasks separately and ignore the geographic relationships among stations. Here, we propose a graph neural network that operates directly on multi-station seismic data and achieves simultaneous phase picking, association, and location. Particularly, the inter-station and inter-task physical relationships are informed in the network architecture to promote accuracy, interpretability, and physical consistency among cross-station and cross-task predictions. When applied to data from the Ridgecrest region and Japan regions, this method showed superior performance over previous deep learning-based phase-picking and localization methods. Overall, our study provides for the first time a prototype self-consistent all-in-one system of simultaneous seismic phase picking, association, and location, which has the potential for next-generation autonomous earthquake monitoring.