 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomaton-Guided Curriculum Generation for Reinforcement Learning Agents
Apr 11, 2023


Despite advances in Reinforcement Learning, many sequential decision making tasks remain prohibitively expensive and impractical to learn. Recently, approaches that automatically generate reward functions from logical task specifications have been proposed to mitigate this issue; however, they scale poorly on long-horizon tasks (i.e., tasks where the agent needs to perform a series of correct actions to reach the goal state, considering future transitions while choosing an action). Employing a curriculum (a sequence of increasingly complex tasks) further improves the learning speed of the agent by sequencing intermediate tasks suited to the learning capacity of the agent. However, generating curricula from the logical specification still remains an unsolved problem. To this end, we propose AGCL, Automaton-guided Curriculum Learning, a novel method for automatically generating curricula for the target task in the form of Directed Acyclic Graphs (DAGs). AGCL encodes the specification in the form of a deterministic finite automaton (DFA), and then uses the DFA along with the Object-Oriented MDP (OOMDP) representation to generate a curriculum as a DAG, where the vertices correspond to tasks, and edges correspond to the direction of knowledge transfer. Experiments in gridworld and physics-based simulated robotics domains show that the curricula produced by AGCL achieve improved time-to-threshold performance on a complex sequential decision-making problem relative to state-of-the-art curriculum learning (e.g, teacher-student, self-play) and automaton-guided reinforcement learning baselines (e.g, Q-Learning for Reward Machines). Further, we demonstrate that AGCL performs well even in the presence of noise in the task's OOMDP description, and also when distractor objects are present that are not modeled in the logical specification of the tasks' objectives.
Cross-Tool and Cross-Behavior Perceptual Knowledge Transfer for Grounded Object Recognition
Mar 07, 2023Humans learn about objects via interaction and using multiple perceptions, such as vision, sound, and touch. While vision can provide information about an object's appearance, non-visual sensors, such as audio and haptics, can provide information about its intrinsic properties, such as weight, temperature, hardness, and the object's sound. Using tools to interact with objects can reveal additional object properties that are otherwise hidden (e.g., knives and spoons can be used to examine the properties of food, including its texture and consistency). Robots can use tools to interact with objects and gather information about their implicit properties via non-visual sensors. However, a robot's model for recognizing objects using a tool-mediated behavior does not generalize to a new tool or behavior due to differing observed data distributions. To address this challenge, we propose a framework to enable robots to transfer implicit knowledge about granular objects across different tools and behaviors. The proposed approach learns a shared latent space from multiple robots' contexts produced by respective sensory data while interacting with objects using tools. We collected a dataset using a UR5 robot that performed 5,400 interactions using 6 tools and 6 behaviors on 15 granular objects and tested our method on cross-tool and cross-behavioral transfer tasks. Our results show the less experienced target robot can benefit from the experience gained from the source robot and perform recognition on a set of novel objects. We have released the code, datasets, and additional results: https://github.com/gtatiya/Tool-Knowledge-Transfer.
Methods and Mechanisms for Interactive Novelty Handling in Adversarial Environments
Mar 06, 2023



Learning to detect, characterize and accommodate novelties is a challenge that agents operating in open-world domains need to address to be able to guarantee satisfactory task performance. Certain novelties (e.g., changes in environment dynamics) can interfere with the performance or prevent agents from accomplishing task goals altogether. In this paper, we introduce general methods and architectural mechanisms for detecting and characterizing different types of novelties, and for building an appropriate adaptive model to accommodate them utilizing logical representations and reasoning methods. We demonstrate the effectiveness of the proposed methods in evaluations performed by a third party in the adversarial multi-agent board game Monopoly. The results show high novelty detection and accommodation rates across a variety of novelty types, including changes to the rules of the game, as well as changes to the agent's action capabilities.
Knowledge-driven Scene Priors for Semantic Audio-Visual Embodied Navigation
Dec 21, 2022



Generalisation to unseen contexts remains a challenge for embodied navigation agents. In the context of semantic audio-visual navigation (SAVi) tasks, the notion of generalisation should include both generalising to unseen indoor visual scenes as well as generalising to unheard sounding objects. However, previous SAVi task definitions do not include evaluation conditions on truly novel sounding objects, resorting instead to evaluating agents on unheard sound clips of known objects; meanwhile, previous SAVi methods do not include explicit mechanisms for incorporating domain knowledge about object and region semantics. These weaknesses limit the development and assessment of models' abilities to generalise their learned experience. In this work, we introduce the use of knowledge-driven scene priors in the semantic audio-visual embodied navigation task: we combine semantic information from our novel knowledge graph that encodes object-region relations, spatial knowledge from dual Graph Encoder Networks, and background knowledge from a series of pre-training tasks -- all within a reinforcement learning framework for audio-visual navigation. We also define a new audio-visual navigation sub-task, where agents are evaluated on novel sounding objects, as opposed to unheard clips of known objects. We show improvements over strong baselines in generalisation to unseen regions and novel sounding objects, within the Habitat-Matterport3D simulation environment, under the SoundSpaces task.
Transferring Implicit Knowledge of Non-Visual Object Properties Across Heterogeneous Robot Morphologies
Sep 14, 2022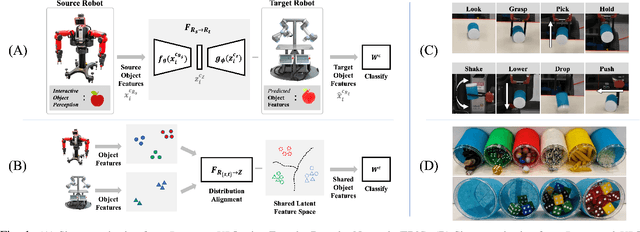

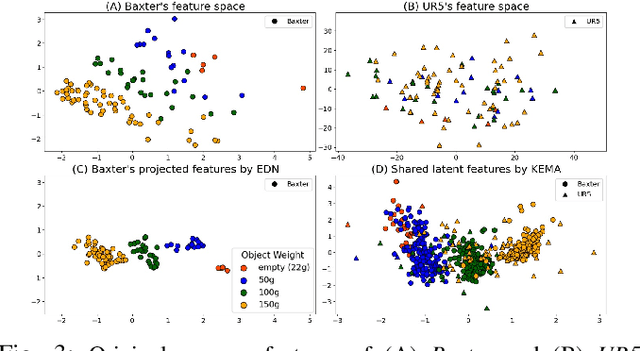
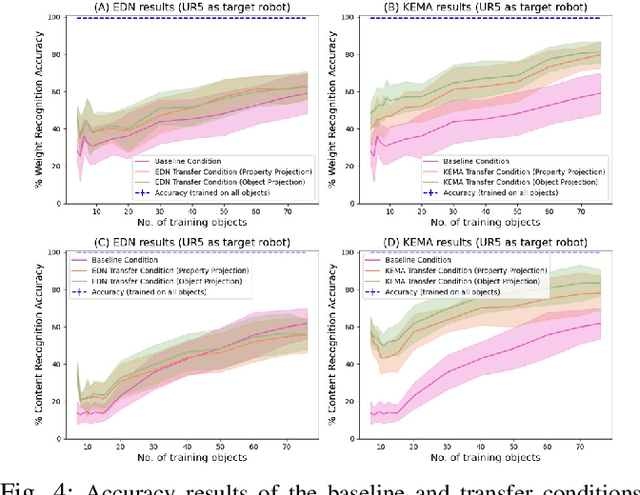
Humans leverage multiple sensor modalities when interacting with objects and discovering their intrinsic properties. Using the visual modality alone is insufficient for deriving intuition behind object properties (e.g., which of two boxes is heavier), making it essential to consider non-visual modalities as well, such as the tactile and auditory. Whereas robots may leverage various modalities to obtain object property understanding via learned exploratory interactions with objects (e.g., grasping, lifting, and shaking behaviors), challenges remain: the implicit knowledge acquired by one robot via object exploration cannot be directly leveraged by another robot with different morphology, because the sensor models, observed data distributions, and interaction capabilities are different across these different robot configurations. To avoid the costly process of learning interactive object perception tasks from scratch, we propose a multi-stage projection framework for each new robot for transferring implicit knowledge of object properties across heterogeneous robot morphologies. We evaluate our approach on the object-property recognition and object-identity recognition tasks, using a dataset containing two heterogeneous robots that perform 7,600 object interactions. Results indicate that knowledge can be transferred across robots, such that a newly-deployed robot can bootstrap its recognition models without exhaustively exploring all objects. We also propose a data augmentation technique and show that this technique improves the generalization of models. We release our code and datasets, here: https://github.com/gtatiya/Implicit-Knowledge-Transfer.
RAPid-Learn: A Framework for Learning to Recover for Handling Novelties in Open-World Environments
Jun 24, 2022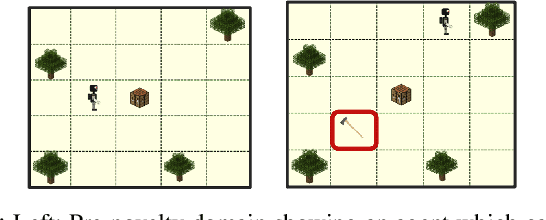
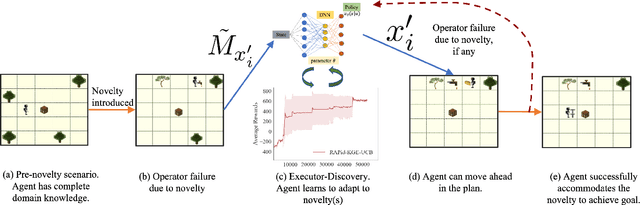
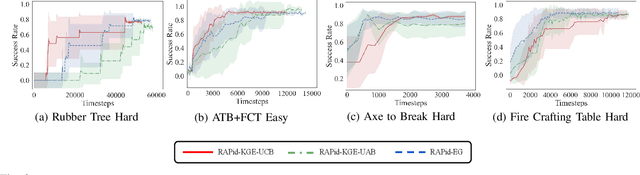

We propose RAPid-Learn: Learning to Recover and Plan Again, a hybrid planning and learning method, to tackle the problem of adapting to sudden and unexpected changes in an agent's environment (i.e., novelties). RAPid-Learn is designed to formulate and solve modifications to a task's Markov Decision Process (MDPs) on-the-fly and is capable of exploiting domain knowledge to learn any new dynamics caused by the environmental changes. It is capable of exploiting the domain knowledge to learn action executors which can be further used to resolve execution impasses, leading to a successful plan execution. This novelty information is reflected in its updated domain model. We demonstrate its efficacy by introducing a wide variety of novelties in a gridworld environment inspired by Minecraft, and compare our algorithm with transfer learning baselines from the literature. Our method is (1) effective even in the presence of multiple novelties, (2) more sample efficient than transfer learning RL baselines, and (3) robust to incomplete model information, as opposed to pure symbolic planning approaches.
Creative Problem Solving in Artificially Intelligent Agents: A Survey and Framework
Apr 21, 2022


Creative Problem Solving (CPS) is a sub-area within Artificial Intelligence (AI) that focuses on methods for solving off-nominal, or anomalous problems in autonomous systems. Despite many advancements in planning and learning, resolving novel problems or adapting existing knowledge to a new context, especially in cases where the environment may change in unpredictable ways post deployment, remains a limiting factor in the safe and useful integration of intelligent systems. The emergence of increasingly autonomous systems dictates the necessity for AI agents to deal with environmental uncertainty through creativity. To stimulate further research in CPS, we present a definition and a framework of CPS, which we adopt to categorize existing AI methods in this field. Our framework consists of four main components of a CPS problem, namely, 1) problem formulation, 2) knowledge representation, 3) method of knowledge manipulation, and 4) method of evaluation. We conclude our survey with open research questions, and suggested directions for the future.
ACuTE: Automatic Curriculum Transfer from Simple to Complex Environments
Apr 11, 2022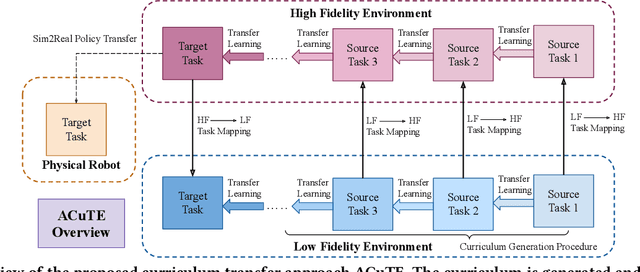
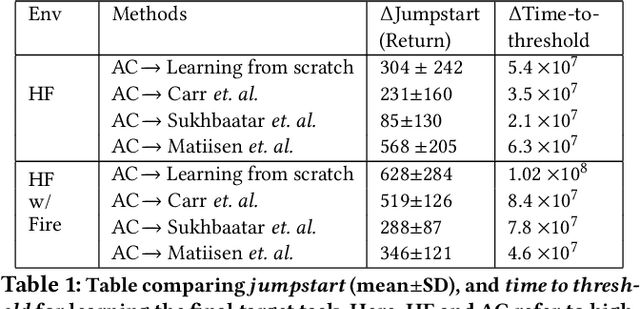
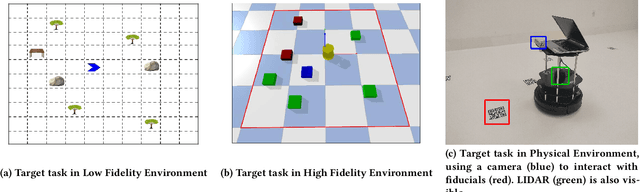
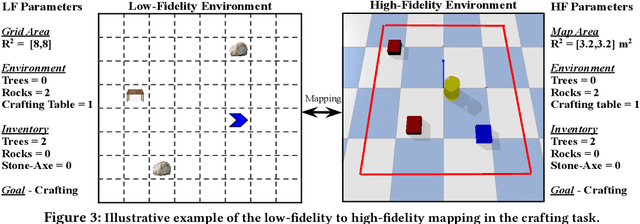
Despite recent advances in Reinforcement Learning (RL), many problems, especially real-world tasks, remain prohibitively expensive to learn. To address this issue, several lines of research have explored how tasks, or data samples themselves, can be sequenced into a curriculum to learn a problem that may otherwise be too difficult to learn from scratch. However, generating and optimizing a curriculum in a realistic scenario still requires extensive interactions with the environment. To address this challenge, we formulate the curriculum transfer problem, in which the schema of a curriculum optimized in a simpler, easy-to-solve environment (e.g., a grid world) is transferred to a complex, realistic scenario (e.g., a physics-based robotics simulation or the real world). We present "ACuTE", Automatic Curriculum Transfer from Simple to Complex Environments, a novel framework to solve this problem, and evaluate our proposed method by comparing it to other baseline approaches (e.g., domain adaptation) designed to speed up learning. We observe that our approach produces improved jumpstart and time-to-threshold performance even when adding task elements that further increase the difficulty of the realistic scenario. Finally, we demonstrate that our approach is independent of the learning algorithm used for curriculum generation, and is Sim2Real transferable to a real world scenario using a physical robot.
An Augmented Reality Platform for Introducing Reinforcement Learning to K-12 Students with Robots
Oct 10, 2021
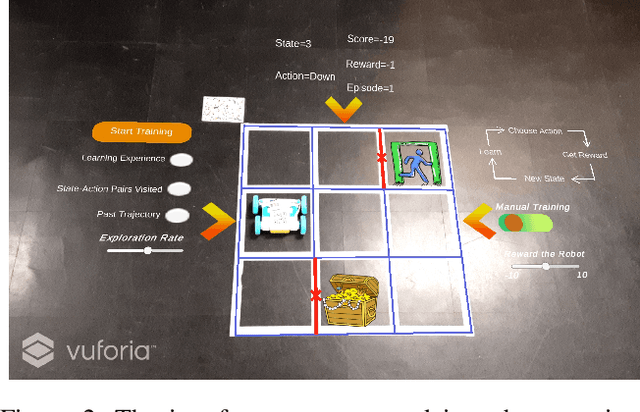
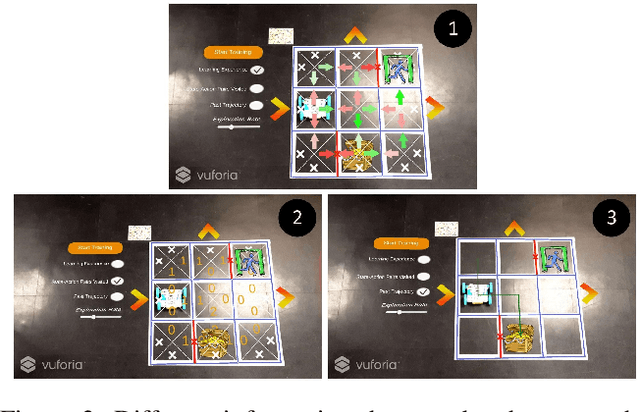
Interactive reinforcement learning, where humans actively assist during an agent's learning process, has the promise to alleviate the sample complexity challenges of practical algorithms. However, the inner workings and state of the robot are typically hidden from the teacher when humans provide feedback. To create a common ground between the human and the learning robot, in this paper, we propose an Augmented Reality (AR) system that reveals the hidden state of the learning to the human users. This paper describes our system's design and implementation and concludes with a discussion on two directions for future work which we are pursuing: 1) use of our system in AI education activities at the K-12 level; and 2) development of a framework for an AR-based human-in-the-loop reinforcement learning, where the human teacher can see sensory and cognitive representations of the robot overlaid in the real world.
AI-HRI 2021 Proceedings
Sep 23, 2021The Artificial Intelligence (AI) for Human-Robot Interaction (HRI) Symposium has been a successful venue of discussion and collaboration since 2014. During that time, these symposia provided a fertile ground for numerous collaborations and pioneered many discussions revolving trust in HRI, XAI for HRI, service robots, interactive learning, and more. This year, we aim to review the achievements of the AI-HRI community in the last decade, identify the challenges facing ahead, and welcome new researchers who wish to take part in this growing community. Taking this wide perspective, this year there will be no single theme to lead the symposium and we encourage AI-HRI submissions from across disciplines and research interests. Moreover, with the rising interest in AR and VR as part of an interaction and following the difficulties in running physical experiments during the pandemic, this year we specifically encourage researchers to submit works that do not include a physical robot in their evaluation, but promote HRI research in general. In addition, acknowledging that ethics is an inherent part of the human-robot interaction, we encourage submissions of works on ethics for HRI. Over the course of the two-day meeting, we will host a collaborative forum for discussion of current efforts in AI-HRI, with additional talks focused on the topics of ethics in HRI and ubiquitous HRI.