 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOSAIC: Learning Unified Multi-Sensory Object Property Representations for Robot Perception
Sep 15, 2023A holistic understanding of object properties across diverse sensory modalities (e.g., visual, audio, and haptic) is essential for tasks ranging from object categorization to complex manipulation. Drawing inspiration from cognitive science studies that emphasize the significance of multi-sensory integration in human perception, we introduce MOSAIC (Multi-modal Object property learning with Self-Attention and Integrated Comprehension), a novel framework designed to facilitate the learning of unified multi-sensory object property representations. While it is undeniable that visual information plays a prominent role, we acknowledge that many fundamental object properties extend beyond the visual domain to encompass attributes like texture, mass distribution, or sounds, which significantly influence how we interact with objects. In MOSAIC, we leverage this profound insight by distilling knowledge from the extensive pre-trained Contrastive Language-Image Pre-training (CLIP) model, aligning these representations not only across vision but also haptic and auditory sensory modalities. Through extensive experiments on a dataset where a humanoid robot interacts with 100 objects across 10 exploratory behaviors, we demonstrate the versatility of MOSAIC in two task families: object categorization and object-fetching tasks. Our results underscore the efficacy of MOSAIC's unified representations, showing competitive performance in category recognition through a simple linear probe setup and excelling in the fetch object task under zero-shot transfer conditions. This work pioneers the application of CLIP-based sensory grounding in robotics, promising a significant leap in multi-sensory perception capabilities for autonomous systems. We have released the code, datasets, and additional results: https://github.com/gtatiya/MOSAIC.
Cross-Tool and Cross-Behavior Perceptual Knowledge Transfer for Grounded Object Recognition
Mar 07, 2023Humans learn about objects via interaction and using multiple perceptions, such as vision, sound, and touch. While vision can provide information about an object's appearance, non-visual sensors, such as audio and haptics, can provide information about its intrinsic properties, such as weight, temperature, hardness, and the object's sound. Using tools to interact with objects can reveal additional object properties that are otherwise hidden (e.g., knives and spoons can be used to examine the properties of food, including its texture and consistency). Robots can use tools to interact with objects and gather information about their implicit properties via non-visual sensors. However, a robot's model for recognizing objects using a tool-mediated behavior does not generalize to a new tool or behavior due to differing observed data distributions. To address this challenge, we propose a framework to enable robots to transfer implicit knowledge about granular objects across different tools and behaviors. The proposed approach learns a shared latent space from multiple robots' contexts produced by respective sensory data while interacting with objects using tools. We collected a dataset using a UR5 robot that performed 5,400 interactions using 6 tools and 6 behaviors on 15 granular objects and tested our method on cross-tool and cross-behavioral transfer tasks. Our results show the less experienced target robot can benefit from the experience gained from the source robot and perform recognition on a set of novel objects. We have released the code, datasets, and additional results: https://github.com/gtatiya/Tool-Knowledge-Transfer.
Knowledge-driven Scene Priors for Semantic Audio-Visual Embodied Navigation
Dec 21, 2022



Generalisation to unseen contexts remains a challenge for embodied navigation agents. In the context of semantic audio-visual navigation (SAVi) tasks, the notion of generalisation should include both generalising to unseen indoor visual scenes as well as generalising to unheard sounding objects. However, previous SAVi task definitions do not include evaluation conditions on truly novel sounding objects, resorting instead to evaluating agents on unheard sound clips of known objects; meanwhile, previous SAVi methods do not include explicit mechanisms for incorporating domain knowledge about object and region semantics. These weaknesses limit the development and assessment of models' abilities to generalise their learned experience. In this work, we introduce the use of knowledge-driven scene priors in the semantic audio-visual embodied navigation task: we combine semantic information from our novel knowledge graph that encodes object-region relations, spatial knowledge from dual Graph Encoder Networks, and background knowledge from a series of pre-training tasks -- all within a reinforcement learning framework for audio-visual navigation. We also define a new audio-visual navigation sub-task, where agents are evaluated on novel sounding objects, as opposed to unheard clips of known objects. We show improvements over strong baselines in generalisation to unseen regions and novel sounding objects, within the Habitat-Matterport3D simulation environment, under the SoundSpaces task.
Transferring Implicit Knowledge of Non-Visual Object Properties Across Heterogeneous Robot Morphologies
Sep 14, 2022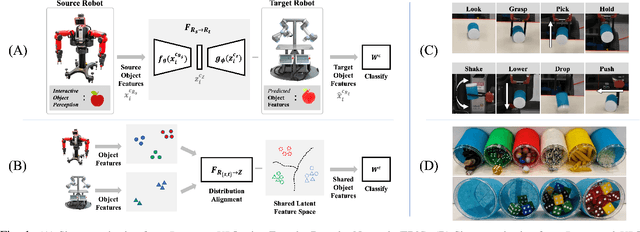

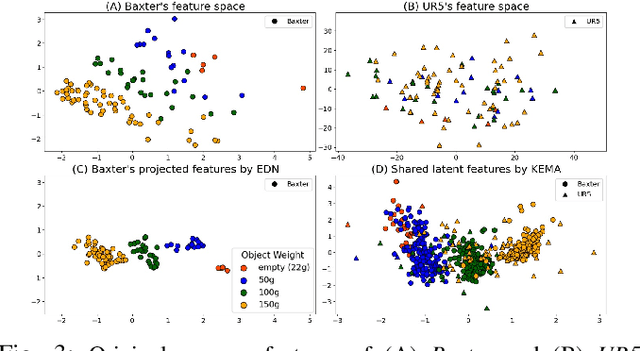
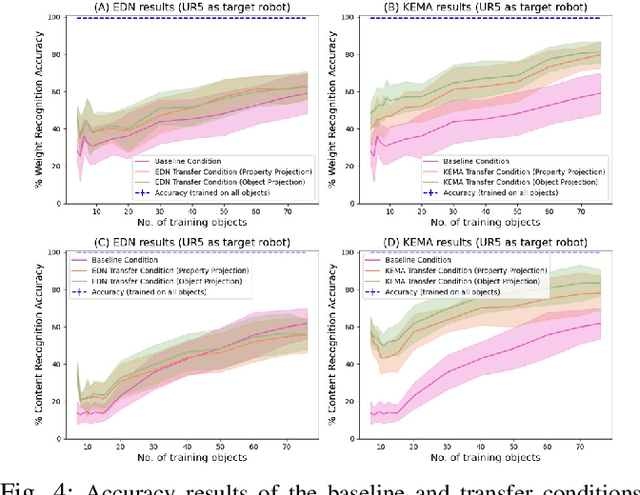
Humans leverage multiple sensor modalities when interacting with objects and discovering their intrinsic properties. Using the visual modality alone is insufficient for deriving intuition behind object properties (e.g., which of two boxes is heavier), making it essential to consider non-visual modalities as well, such as the tactile and auditory. Whereas robots may leverage various modalities to obtain object property understanding via learned exploratory interactions with objects (e.g., grasping, lifting, and shaking behaviors), challenges remain: the implicit knowledge acquired by one robot via object exploration cannot be directly leveraged by another robot with different morphology, because the sensor models, observed data distributions, and interaction capabilities are different across these different robot configurations. To avoid the costly process of learning interactive object perception tasks from scratch, we propose a multi-stage projection framework for each new robot for transferring implicit knowledge of object properties across heterogeneous robot morphologies. We evaluate our approach on the object-property recognition and object-identity recognition tasks, using a dataset containing two heterogeneous robots that perform 7,600 object interactions. Results indicate that knowledge can be transferred across robots, such that a newly-deployed robot can bootstrap its recognition models without exhaustively exploring all objects. We also propose a data augmentation technique and show that this technique improves the generalization of models. We release our code and datasets, here: https://github.com/gtatiya/Implicit-Knowledge-Transfer.
ACuTE: Automatic Curriculum Transfer from Simple to Complex Environments
Apr 11, 2022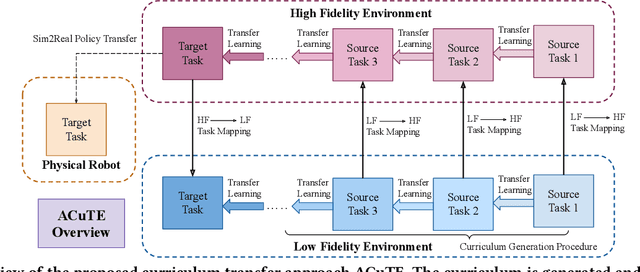
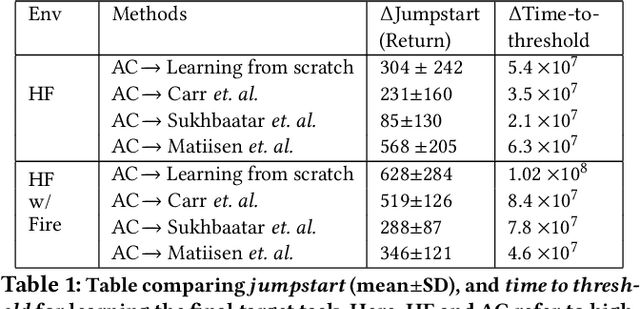
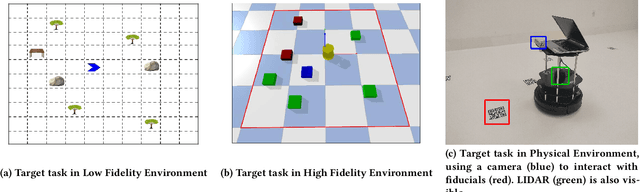
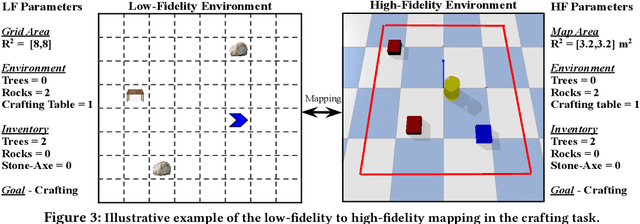
Despite recent advances in Reinforcement Learning (RL), many problems, especially real-world tasks, remain prohibitively expensive to learn. To address this issue, several lines of research have explored how tasks, or data samples themselves, can be sequenced into a curriculum to learn a problem that may otherwise be too difficult to learn from scratch. However, generating and optimizing a curriculum in a realistic scenario still requires extensive interactions with the environment. To address this challenge, we formulate the curriculum transfer problem, in which the schema of a curriculum optimized in a simpler, easy-to-solve environment (e.g., a grid world) is transferred to a complex, realistic scenario (e.g., a physics-based robotics simulation or the real world). We present "ACuTE", Automatic Curriculum Transfer from Simple to Complex Environments, a novel framework to solve this problem, and evaluate our proposed method by comparing it to other baseline approaches (e.g., domain adaptation) designed to speed up learning. We observe that our approach produces improved jumpstart and time-to-threshold performance even when adding task elements that further increase the difficulty of the realistic scenario. Finally, we demonstrate that our approach is independent of the learning algorithm used for curriculum generation, and is Sim2Real transferable to a real world scenario using a physical robot.