 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLEX: A Framework for Learning Robot-Agnostic Force-based Skills Involving Sustained Contact Object Manipulation
Mar 17, 2025



Learning to manipulate objects efficiently, particularly those involving sustained contact (e.g., pushing, sliding) and articulated parts (e.g., drawers, doors), presents significant challenges. Traditional methods, such as robot-centric reinforcement learning (RL), imitation learning, and hybrid techniques, require massive training and often struggle to generalize across different objects and robot platforms. We propose a novel framework for learning object-centric manipulation policies in force space, decoupling the robot from the object. By directly applying forces to selected regions of the object, our method simplifies the action space, reduces unnecessary exploration, and decreases simulation overhead. This approach, trained in simulation on a small set of representative objects, captures object dynamics -- such as joint configurations -- allowing policies to generalize effectively to new, unseen objects. Decoupling these policies from robot-specific dynamics enables direct transfer to different robotic platforms (e.g., Kinova, Panda, UR5) without retraining. Our evaluations demonstrate that the method significantly outperforms baselines, achieving over an order of magnitude improvement in training efficiency compared to other state-of-the-art methods. Additionally, operating in force space enhances policy transferability across diverse robot platforms and object types. We further showcase the applicability of our method in a real-world robotic setting. For supplementary materials and videos, please visit: https://tufts-ai-robotics-group.github.io/FLEX/
NovelGym: A Flexible Ecosystem for Hybrid Planning and Learning Agents Designed for Open Worlds
Jan 07, 2024



As AI agents leave the lab and venture into the real world as autonomous vehicles, delivery robots, and cooking robots, it is increasingly necessary to design and comprehensively evaluate algorithms that tackle the ``open-world''. To this end, we introduce NovelGym, a flexible and adaptable ecosystem designed to simulate gridworld environments, serving as a robust platform for benchmarking reinforcement learning (RL) and hybrid planning and learning agents in open-world contexts. The modular architecture of NovelGym facilitates rapid creation and modification of task environments, including multi-agent scenarios, with multiple environment transformations, thus providing a dynamic testbed for researchers to develop open-world AI agents.
A Framework for Few-Shot Policy Transfer through Observation Mapping and Behavior Cloning
Oct 13, 2023



Despite recent progress in Reinforcement Learning for robotics applications, many tasks remain prohibitively difficult to solve because of the expensive interaction cost. Transfer learning helps reduce the training time in the target domain by transferring knowledge learned in a source domain. Sim2Real transfer helps transfer knowledge from a simulated robotic domain to a physical target domain. Knowledge transfer reduces the time required to train a task in the physical world, where the cost of interactions is high. However, most existing approaches assume exact correspondence in the task structure and the physical properties of the two domains. This work proposes a framework for Few-Shot Policy Transfer between two domains through Observation Mapping and Behavior Cloning. We use Generative Adversarial Networks (GANs) along with a cycle-consistency loss to map the observations between the source and target domains and later use this learned mapping to clone the successful source task behavior policy to the target domain. We observe successful behavior policy transfer with limited target task interactions and in cases where the source and target task are semantically dissimilar.
RAPid-Learn: A Framework for Learning to Recover for Handling Novelties in Open-World Environments
Jun 24, 2022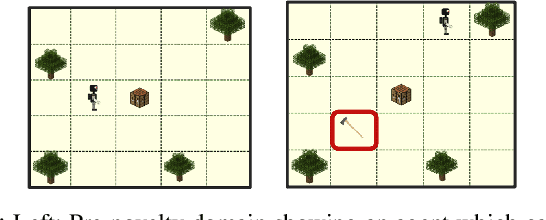
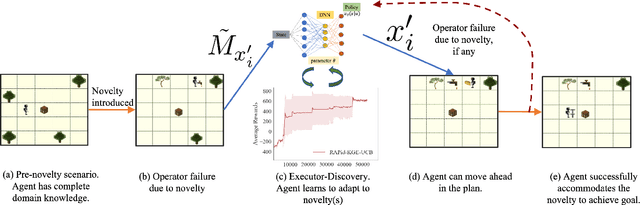
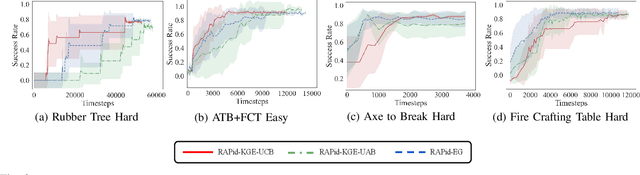

We propose RAPid-Learn: Learning to Recover and Plan Again, a hybrid planning and learning method, to tackle the problem of adapting to sudden and unexpected changes in an agent's environment (i.e., novelties). RAPid-Learn is designed to formulate and solve modifications to a task's Markov Decision Process (MDPs) on-the-fly and is capable of exploiting domain knowledge to learn any new dynamics caused by the environmental changes. It is capable of exploiting the domain knowledge to learn action executors which can be further used to resolve execution impasses, leading to a successful plan execution. This novelty information is reflected in its updated domain model. We demonstrate its efficacy by introducing a wide variety of novelties in a gridworld environment inspired by Minecraft, and compare our algorithm with transfer learning baselines from the literature. Our method is (1) effective even in the presence of multiple novelties, (2) more sample efficient than transfer learning RL baselines, and (3) robust to incomplete model information, as opposed to pure symbolic planning approaches.
SPOTTER: Extending Symbolic Planning Operators through Targeted Reinforcement Learning
Dec 24, 2020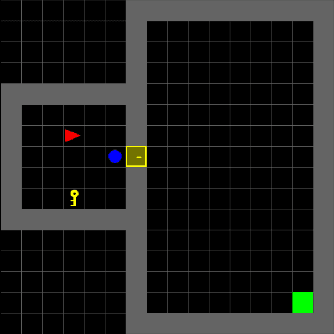
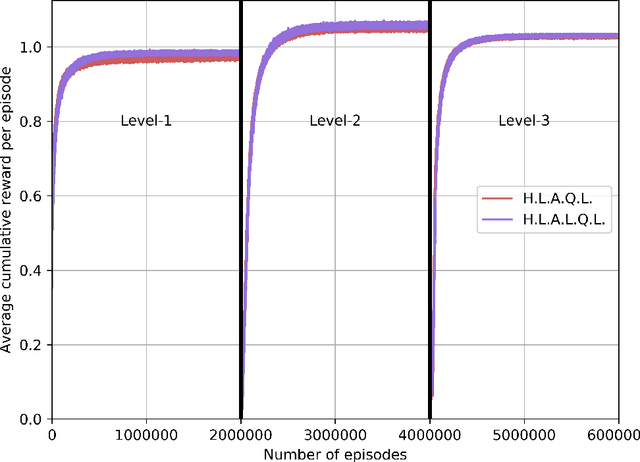
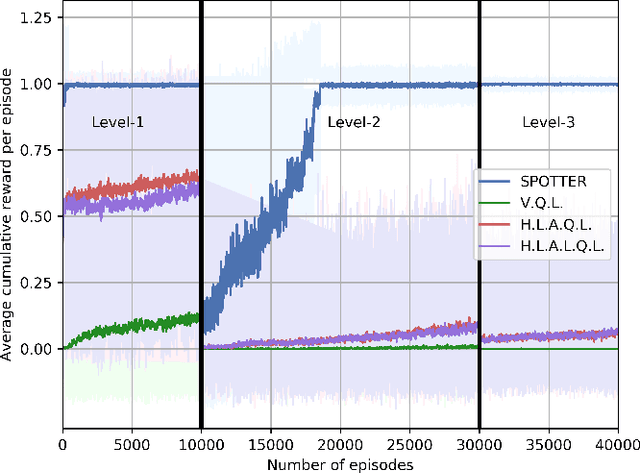
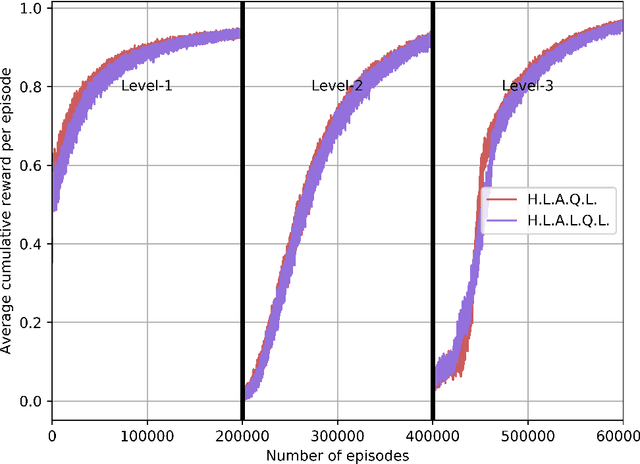
Symbolic planning models allow decision-making agents to sequence actions in arbitrary ways to achieve a variety of goals in dynamic domains. However, they are typically handcrafted and tend to require precise formulations that are not robust to human error. Reinforcement learning (RL) approaches do not require such models, and instead learn domain dynamics by exploring the environment and collecting rewards. However, RL approaches tend to require millions of episodes of experience and often learn policies that are not easily transferable to other tasks. In this paper, we address one aspect of the open problem of integrating these approaches: how can decision-making agents resolve discrepancies in their symbolic planning models while attempting to accomplish goals? We propose an integrated framework named SPOTTER that uses RL to augment and support ("spot") a planning agent by discovering new operators needed by the agent to accomplish goals that are initially unreachable for the agent. SPOTTER outperforms pure-RL approaches while also discovering transferable symbolic knowledge and does not require supervision, successful plan traces or any a priori knowledge about the missing planning operator.