 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemEye: A Visual-Centric Evaluation Framework for Multimodal Agent Memory
May 14, 2026Long-term agent memory is increasingly multimodal, yet existing evaluations rarely test whether agents preserve the visual evidence needed for later reasoning. In prior work, many visually grounded questions can be answered using only captions or textual traces, allowing answers to be inferred without preserving the fine-grained visual evidence. Meanwhile, harder cases that require reasoning over changing visual states are largely absent. Therefore, we introduce MemEye, a framework that evaluates memory capabilities from two dimensions: one measures the granularity of decisive visual evidence (from scene-level to pixel-level evidence), and the other measures how retrieved evidence must be used (from single evidence to evolutionary synthesis). Under this framework, we construct a new benchmark across 8 life-scenario tasks, with ablation-driven validation gates for assessing answerability, shortcut resistance, visual necessity, and reasoning structure. By evaluating 13 memory methods across 4 VLM backbones, we show that current architectures still struggle to preserve fine-grained visual details and reason about state changes over time. Our findings show that long-term multimodal memory depends on evidence routing, temporal tracking, and detail extraction.
Counting Circuits: Mechanistic Interpretability of Visual Reasoning in Large Vision-Language Models
Mar 19, 2026Counting serves as a simple but powerful test of a Large Vision-Language Model's (LVLM's) reasoning; it forces the model to identify each individual object and then add them all up. In this study, we investigate how LVLMs implement counting using controlled synthetic and real-world benchmarks, combined with mechanistic analyses. Our results show that LVLMs display a human-like counting behavior, with precise performance on small numerosities and noisy estimation for larger quantities. We introduce two novel interpretability methods, Visual Activation Patching and HeadLens, and use them to uncover a structured "counting circuit" that is largely shared across a variety of visual reasoning tasks. Building on these insights, we propose a lightweight intervention strategy that exploits simple and abundantly available synthetic images to fine-tune arbitrary pretrained LVLMs exclusively on counting. Despite the narrow scope of this fine-tuning, the intervention not only enhances counting accuracy on in-distribution synthetic data, but also yields an average improvement of +8.36% on out-of-distribution counting benchmarks and an average gain of +1.54% on complex, general visual reasoning tasks for Qwen2.5-VL. These findings highlight the central, influential role of counting in visual reasoning and suggest a potential pathway for improving overall visual reasoning capabilities through targeted enhancement of counting mechanisms.
EAZY: Eliminating Hallucinations in LVLMs by Zeroing out Hallucinatory Image Tokens
Mar 10, 2025



Despite their remarkable potential, Large Vision-Language Models (LVLMs) still face challenges with object hallucination, a problem where their generated outputs mistakenly incorporate objects that do not actually exist. Although most works focus on addressing this issue within the language-model backbone, our work shifts the focus to the image input source, investigating how specific image tokens contribute to hallucinations. Our analysis reveals a striking finding: a small subset of image tokens with high attention scores are the primary drivers of object hallucination. By removing these hallucinatory image tokens (only 1.5% of all image tokens), the issue can be effectively mitigated. This finding holds consistently across different models and datasets. Building on this insight, we introduce EAZY, a novel, training-free method that automatically identifies and Eliminates hAllucinations by Zeroing out hallucinatorY image tokens. We utilize EAZY for unsupervised object hallucination detection, achieving 15% improvement compared to previous methods. Additionally, EAZY demonstrates remarkable effectiveness in mitigating hallucinations while preserving model utility and seamlessly adapting to various LVLM architectures.
Leveraging Foundation Models for Multi-modal Federated Learning with Incomplete Modality
Jun 16, 2024



Federated learning (FL) has obtained tremendous progress in providing collaborative training solutions for distributed data silos with privacy guarantees. However, few existing works explore a more realistic scenario where the clients hold multiple data modalities. In this paper, we aim to solve a novel challenge in multi-modal federated learning (MFL) -- modality missing -- the clients may lose part of the modalities in their local data sets. To tackle the problems, we propose a novel multi-modal federated learning method, Federated Multi-modal contrastiVe training with Pre-trained completion (FedMVP), which integrates the large-scale pre-trained models to enhance the federated training. In the proposed FedMVP framework, each client deploys a large-scale pre-trained model with frozen parameters for modality completion and representation knowledge transfer, enabling efficient and robust local training. On the server side, we utilize generated data to uniformly measure the representation similarity among the uploaded client models and construct a graph perspective to aggregate them according to their importance in the system. We demonstrate that the model achieves superior performance over two real-world image-text classification datasets and is robust to the performance degradation caused by missing modality.
Towards Personalized Federated Learning via Heterogeneous Model Reassembly
Sep 06, 2023This paper focuses on addressing the practical yet challenging problem of model heterogeneity in federated learning, where clients possess models with different network structures. To track this problem, we propose a novel framework called pFedHR, which leverages heterogeneous model reassembly to achieve personalized federated learning. In particular, we approach the problem of heterogeneous model personalization as a model-matching optimization task on the server side. Moreover, pFedHR automatically and dynamically generates informative and diverse personalized candidates with minimal human intervention. Furthermore, our proposed heterogeneous model reassembly technique mitigates the adverse impact introduced by using public data with different distributions from the client data to a certain extent. Experimental results demonstrate that pFedHR outperforms baselines on three datasets under both IID and Non-IID settings. Additionally, pFedHR effectively reduces the adverse impact of using different public data and dynamically generates diverse personalized models in an automated manner.
FedTriNet: A Pseudo Labeling Method with Three Players for Federated Semi-supervised Learning
Sep 12, 2021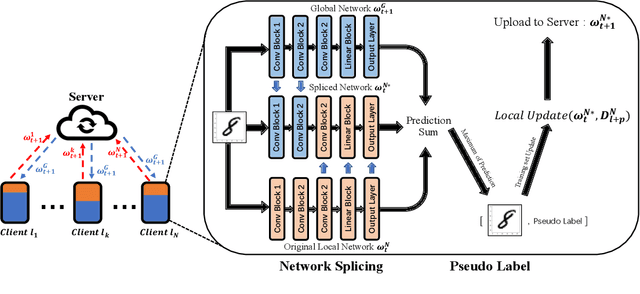
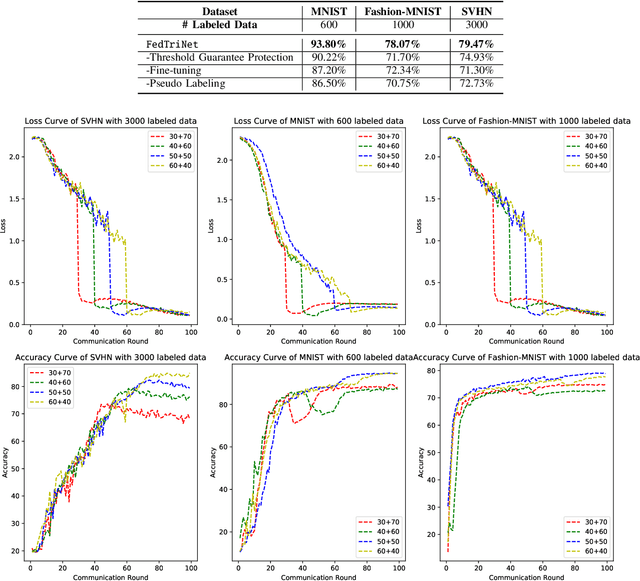
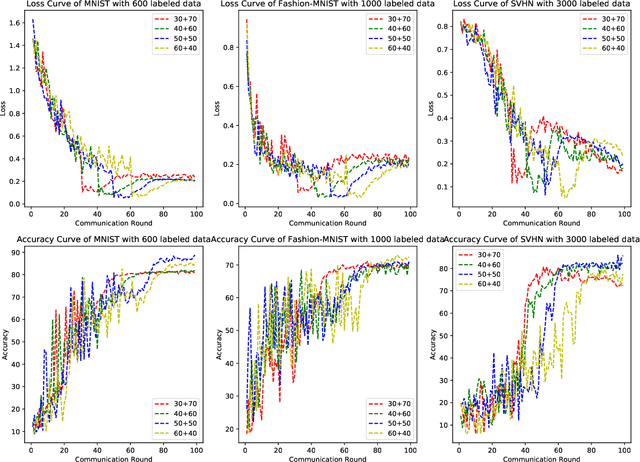

Federated Learning has shown great potentials for the distributed data utilization and privacy protection. Most existing federated learning approaches focus on the supervised setting, which means all the data stored in each client has labels. However, in real-world applications, the client data are impossible to be fully labeled. Thus, how to exploit the unlabeled data should be a new challenge for federated learning. Although a few studies are attempting to overcome this challenge, they may suffer from information leakage or misleading information usage problems. To tackle these issues, in this paper, we propose a novel federated semi-supervised learning method named FedTriNet, which consists of two learning phases. In the first phase, we pre-train FedTriNet using labeled data with FedAvg. In the second phase, we aim to make most of the unlabeled data to help model learning. In particular, we propose to use three networks and a dynamic quality control mechanism to generate high-quality pseudo labels for unlabeled data, which are added to the training set. Finally, FedTriNet uses the new training set to retrain the model. Experimental results on three publicly available datasets show that the proposed FedTriNet outperforms state-of-the-art baselines under both IID and Non-IID settings.
FedSemi: An Adaptive Federated Semi-Supervised Learning Framework
Dec 06, 2020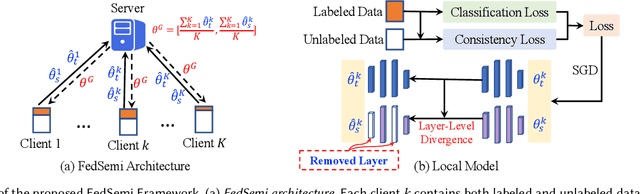
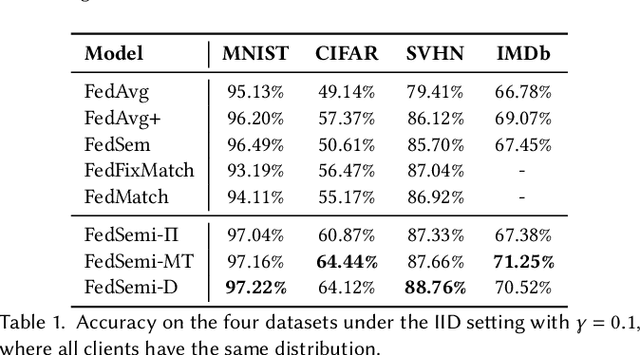
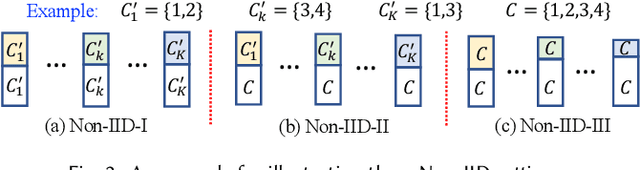
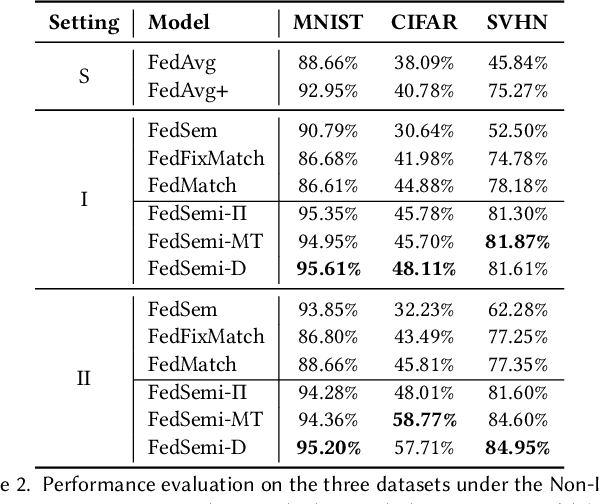
Federated learning (FL) has emerged as an effective technique to co-training machine learning models without actually sharing data and leaking privacy. However, most existing FL methods focus on the supervised setting and ignore the utilization of unlabeled data. Although there are a few existing studies trying to incorporate unlabeled data into FL, they all fail to maintain performance guarantees or generalization ability in various settings. In this paper, we tackle the federated semi-supervised learning problem from the insight of data regularization and analyze the new-raised difficulties. We propose FedSemi, a novel, adaptive, and general framework, which firstly introduces the consistency regularization into FL using a teacher-student model. We further propose a new metric to measure the divergence of local model layers. Based on the divergence, FedSemi can automatically select layer-level parameters to be uploaded to the server in an adaptive manner. Through extensive experimental validation of our method in four datasets, we show that our method achieves performance gain under the IID setting and three Non-IID settings compared to state-of-the-art baselines.