 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Pre-Training with Speech and Bilingual Text for Direct Speech to Speech Translation
Oct 31, 2022Direct speech-to-speech translation (S2ST) is an attractive research topic with many advantages compared to cascaded S2ST. However, direct S2ST suffers from the data scarcity problem because the corpora from speech of the source language to speech of the target language are very rare. To address this issue, we propose in this paper a Speech2S model, which is jointly pre-trained with unpaired speech and bilingual text data for direct speech-to-speech translation tasks. By effectively leveraging the paired text data, Speech2S is capable of modeling the cross-lingual speech conversion from source to target language. We verify the performance of the proposed Speech2S on Europarl-ST and VoxPopuli datasets. Experimental results demonstrate that Speech2S gets an improvement of about 5 BLEU scores compared to encoder-only pre-training models, and achieves a competitive or even better performance than existing state-of-the-art models1.
CTCBERT: Advancing Hidden-unit BERT with CTC Objectives
Oct 16, 2022
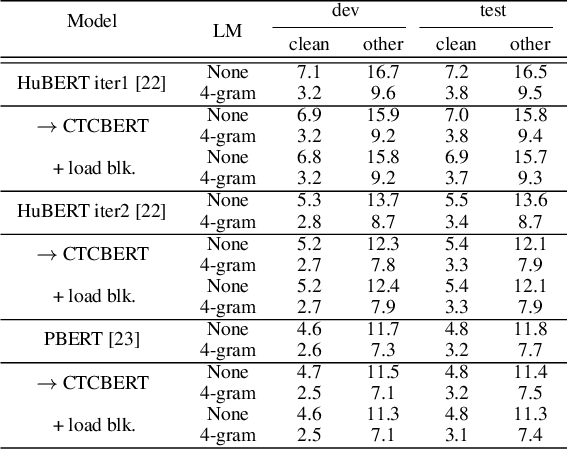
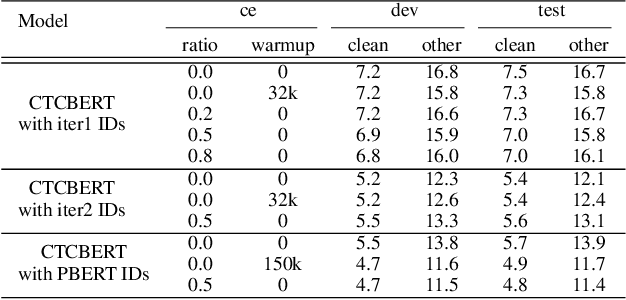
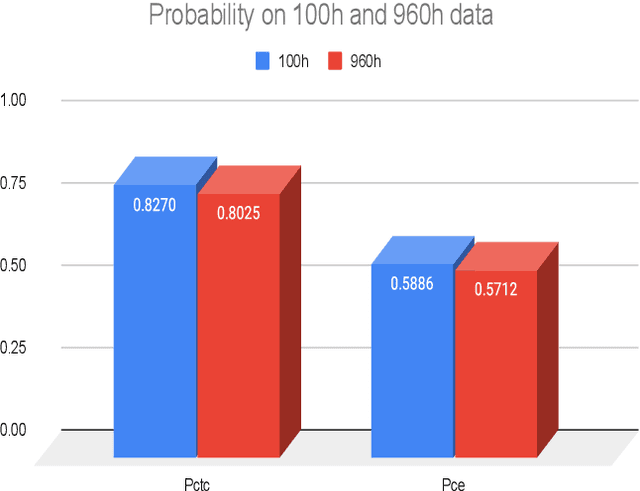
In this work, we present a simple but effective method, CTCBERT, for advancing hidden-unit BERT (HuBERT). HuBERT applies a frame-level cross-entropy (CE) loss, which is similar to most acoustic model training. However, CTCBERT performs the model training with the Connectionist Temporal Classification (CTC) objective after removing duplicated IDs in each masked region. The idea stems from the observation that there can be significant errors in alignments when using clustered or aligned IDs. CTC learns alignments implicitly, indicating that learning with CTC can be more flexible when misalignment exists. We examine CTCBERT on IDs from HuBERT Iter1, HuBERT Iter2, and PBERT. The CTC training brings consistent improvements compared to the CE training. Furthermore, when loading blank-related parameters during finetuning, slight improvements are observed. Evaluated on the Librispeech 960-100h setting, the relative WER improvements of CTCBERT are 2%-11% over HuBERT and PERT on test-other data.
Acoustic-aware Non-autoregressive Spell Correction with Mask Sample Decoding
Oct 16, 2022
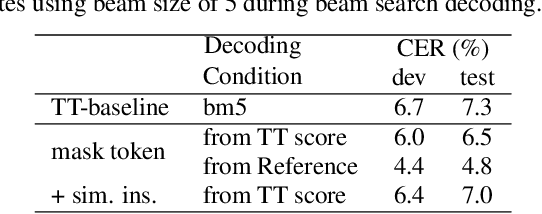

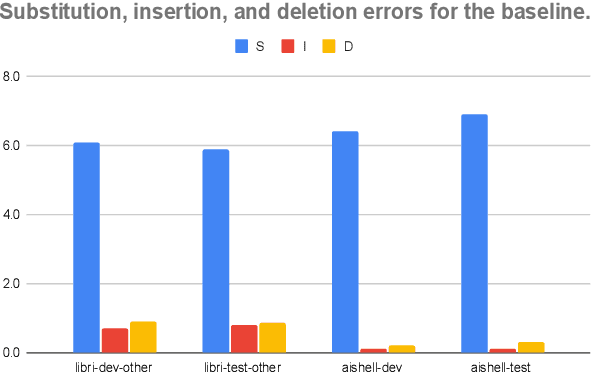
Masked language model (MLM) has been widely used for understanding tasks, e.g. BERT. Recently, MLM has also been used for generation tasks. The most popular one in speech is using Mask-CTC for non-autoregressive speech recognition. In this paper, we take one step further, and explore the possibility of using MLM as a non-autoregressive spell correction (SC) model for transformer-transducer (TT), denoted as MLM-SC. Our initial experiments show that MLM-SC provides no improvements on Librispeech data. The problem might be the choice of modeling units (word pieces) and the inaccuracy of the TT confidence scores for English data. To solve the problem, we propose a mask sample decoding (MS-decode) method where the masked tokens can have the choice of being masked or not to compensate for the inaccuracy. As a result, we reduce the WER of a streaming TT from 7.6% to 6.5% on the Librispeech test-other data and the CER from 7.3% to 6.1% on the Aishell test data, respectively.
SpeechUT: Bridging Speech and Text with Hidden-Unit for Encoder-Decoder Based Speech-Text Pre-training
Oct 07, 2022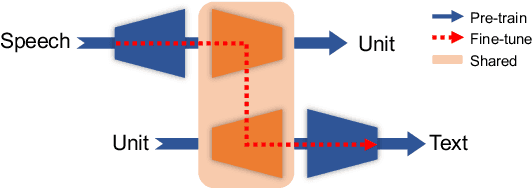
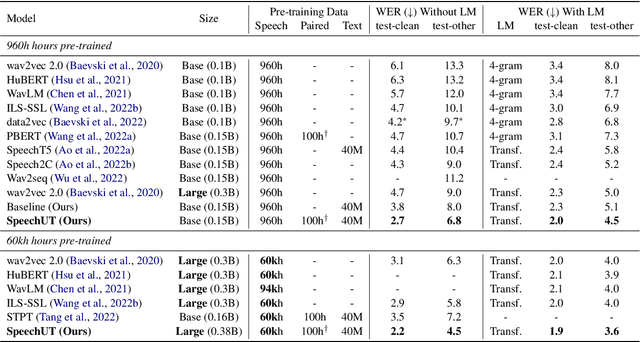
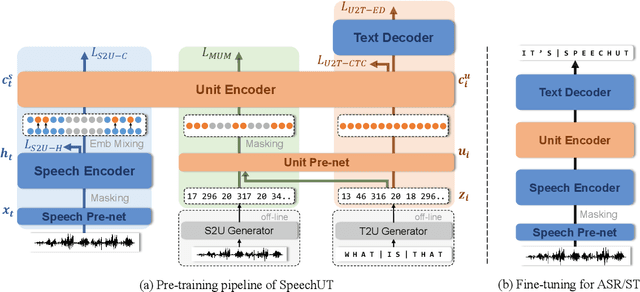
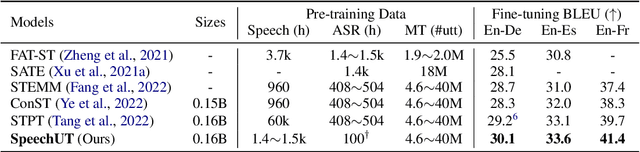
The rapid development of single-modal pre-training has prompted researchers to pay more attention to cross-modal pre-training methods. In this paper, we propose a unified-modal speech-unit-text pre-training model, SpeechUT, to connect the representations of a speech encoder and a text decoder with a shared unit encoder. Leveraging hidden-unit as an interface to align speech and text, we can decompose the speech-to-text model into a speech-to-unit model and a unit-to-text model, which can be jointly pre-trained with unpaired speech and text data respectively. Our proposed SpeechUT is fine-tuned and evaluated on automatic speech recognition (ASR) and speech translation (ST) tasks. Experimental results show that SpeechUT gets substantial improvements over strong baselines, and achieves state-of-the-art performance on both the LibriSpeech ASR and MuST-C ST tasks. To better understand the proposed SpeechUT, detailed analyses are conducted. The code and pre-trained models are available at https://aka.ms/SpeechUT.
SpeechLM: Enhanced Speech Pre-Training with Unpaired Textual Data
Sep 30, 2022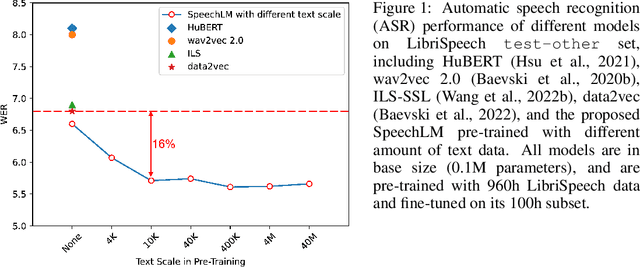
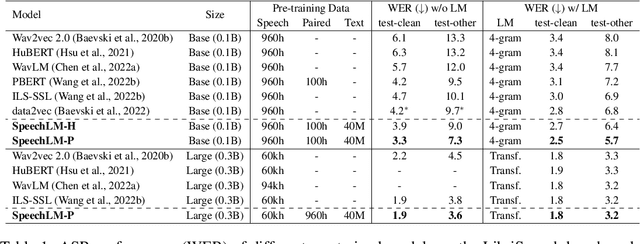
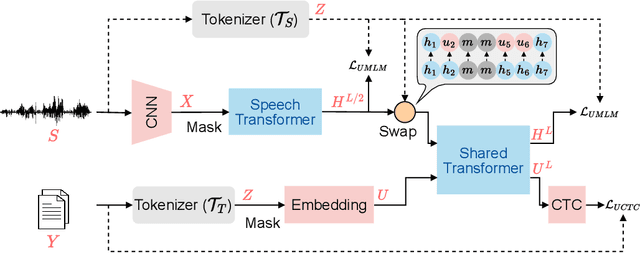
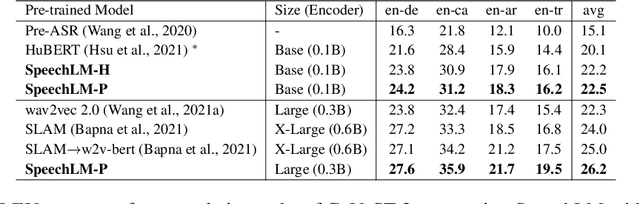
How to boost speech pre-training with textual data is an unsolved problem due to the fact that speech and text are very different modalities with distinct characteristics. In this paper, we propose a cross-modal Speech and Language Model (SpeechLM) to explicitly align speech and text pre-training with a pre-defined unified discrete representation. Specifically, we introduce two alternative discrete tokenizers to bridge the speech and text modalities, including phoneme-unit and hidden-unit tokenizers, which can be trained using a small amount of paired speech-text data. Based on the trained tokenizers, we convert the unlabeled speech and text data into tokens of phoneme units or hidden units. The pre-training objective is designed to unify the speech and the text into the same discrete semantic space with a unified Transformer network. Leveraging only 10K text sentences, our SpeechLM gets a 16\% relative WER reduction over the best base model performance (from 6.8 to 5.7) on the public LibriSpeech ASR benchmark. Moreover, SpeechLM with fewer parameters even outperforms previous SOTA models on CoVoST-2 speech translation tasks. We also evaluate our SpeechLM on various spoken language processing tasks under the universal representation evaluation framework SUPERB, demonstrating significant improvements on content-related tasks. Our code and models are available at https://aka.ms/SpeechLM.
VarArray Meets t-SOT: Advancing the State of the Art of Streaming Distant Conversational Speech Recognition
Sep 12, 2022
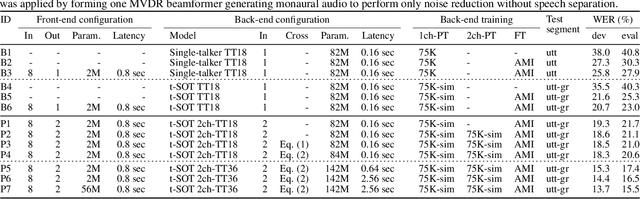
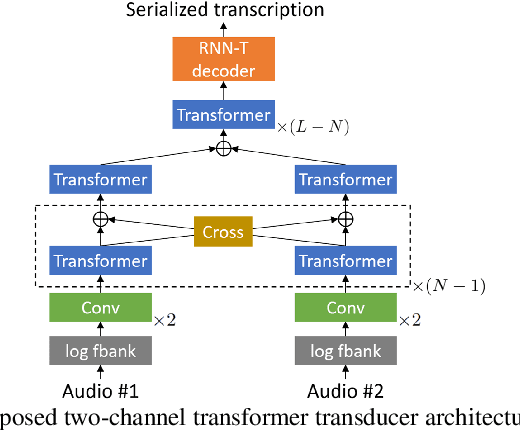

This paper presents a novel streaming automatic speech recognition (ASR) framework for multi-talker overlapping speech captured by a distant microphone array with an arbitrary geometry. Our framework, named t-SOT-VA, capitalizes on independently developed two recent technologies; array-geometry-agnostic continuous speech separation, or VarArray, and streaming multi-talker ASR based on token-level serialized output training (t-SOT). To combine the best of both technologies, we newly design a t-SOT-based ASR model that generates a serialized multi-talker transcription based on two separated speech signals from VarArray. We also propose a pre-training scheme for such an ASR model where we simulate VarArray's output signals based on monaural single-talker ASR training data. Conversation transcription experiments using the AMI meeting corpus show that the system based on the proposed framework significantly outperforms conventional ones. Our system achieves the state-of-the-art word error rates of 13.7% and 15.5% for the AMI development and evaluation sets, respectively, in the multiple-distant-microphone setting while retaining the streaming inference capability.
DeFlowSLAM: Self-Supervised Scene Motion Decomposition for Dynamic Dense SLAM
Jul 18, 2022

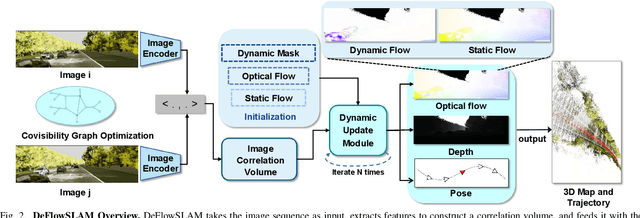
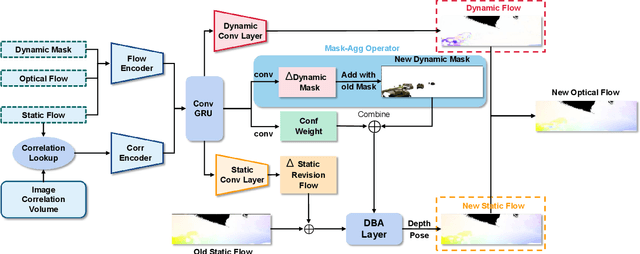
We present a novel dual-flow representation of scene motion that decomposes the optical flow into a static flow field caused by the camera motion and another dynamic flow field caused by the objects' movements in the scene. Based on this representation, we present a dynamic SLAM, dubbed DeFlowSLAM, that exploits both static and dynamic pixels in the images to solve the camera poses, rather than simply using static background pixels as other dynamic SLAM systems do. We propose a dynamic update module to train our DeFlowSLAM in a self-supervised manner, where a dense bundle adjustment layer takes in estimated static flow fields and the weights controlled by the dynamic mask and outputs the residual of the optimized static flow fields, camera poses, and inverse depths. The static and dynamic flow fields are estimated by warping the current image to the neighboring images, and the optical flow can be obtained by summing the two fields. Extensive experiments demonstrate that DeFlowSLAM generalizes well to both static and dynamic scenes as it exhibits comparable performance to the state-of-the-art DROID-SLAM in static and less dynamic scenes while significantly outperforming DROID-SLAM in highly dynamic environments. Code and data are available on the project webpage: \urlstyle{tt} \textcolor{url_color}{\url{https://zju3dv.github.io/deflowslam/}}.
Supervision-Guided Codebooks for Masked Prediction in Speech Pre-training
Jun 21, 2022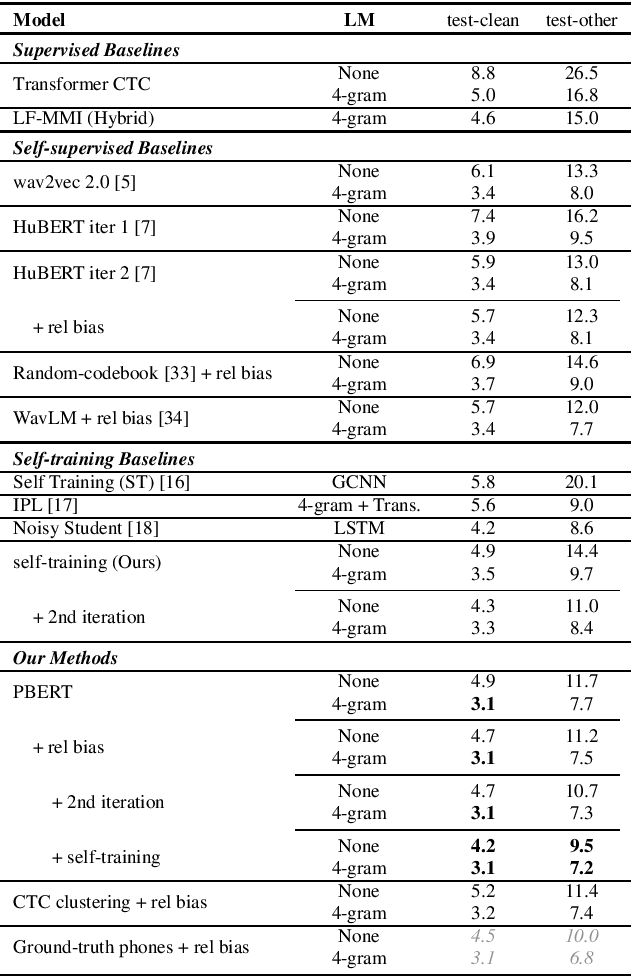
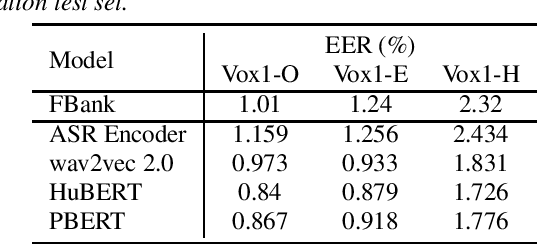
Recently, masked prediction pre-training has seen remarkable progress in self-supervised learning (SSL) for speech recognition. It usually requires a codebook obtained in an unsupervised way, making it less accurate and difficult to interpret. We propose two supervision-guided codebook generation approaches to improve automatic speech recognition (ASR) performance and also the pre-training efficiency, either through decoding with a hybrid ASR system to generate phoneme-level alignments (named PBERT), or performing clustering on the supervised speech features extracted from an end-to-end CTC model (named CTC clustering). Both the hybrid and CTC models are trained on the same small amount of labeled speech as used in fine-tuning. Experiments demonstrate significant superiority of our methods to various SSL and self-training baselines, with up to 17.0% relative WER reduction. Our pre-trained models also show good transferability in a non-ASR speech task.
The YiTrans End-to-End Speech Translation System for IWSLT 2022 Offline Shared Task
Jun 14, 2022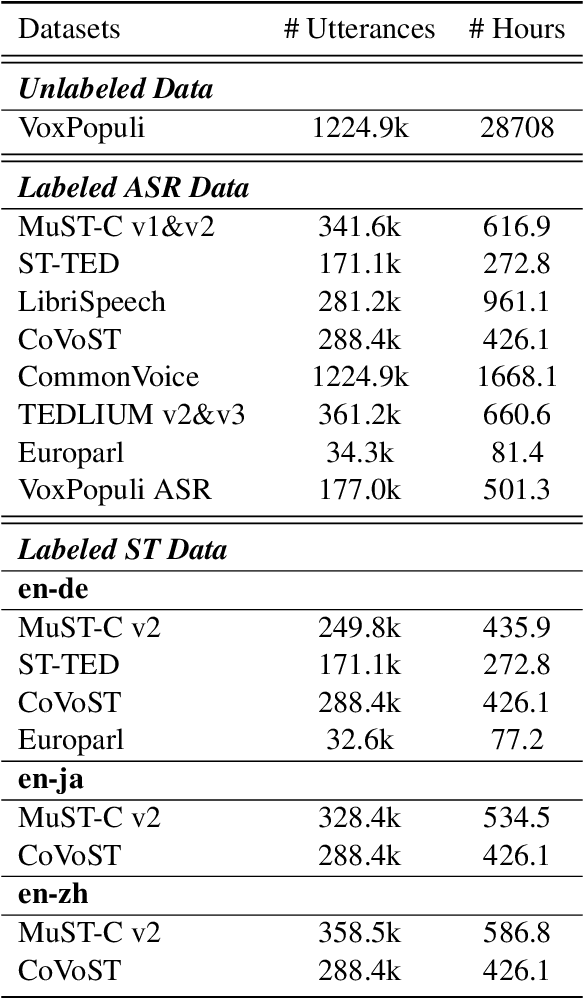
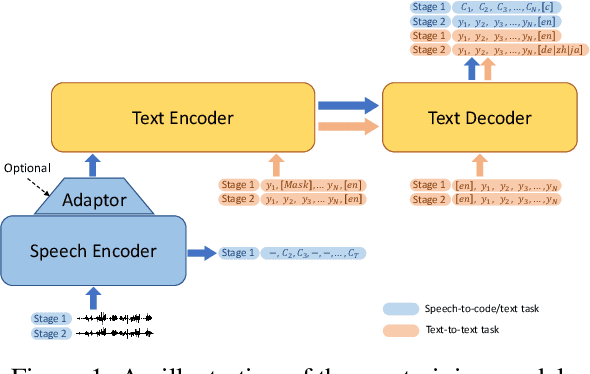
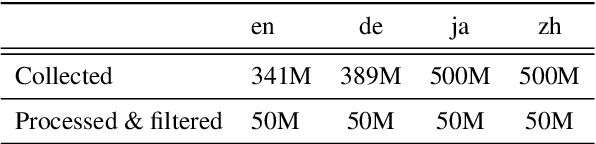
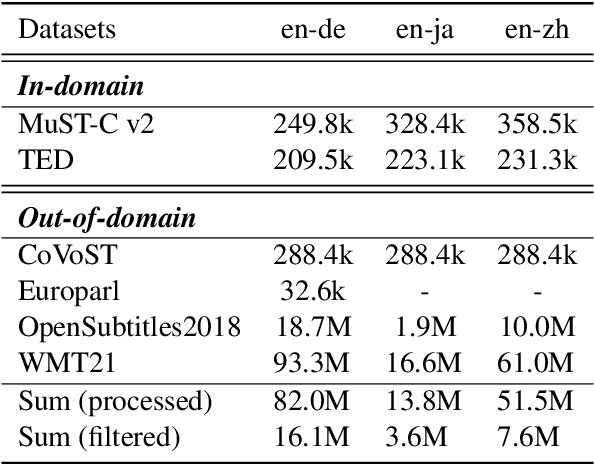
This paper describes the submission of our end-to-end YiTrans speech translation system for the IWSLT 2022 offline task, which translates from English audio to German, Chinese, and Japanese. The YiTrans system is built on large-scale pre-trained encoder-decoder models. More specifically, we first design a multi-stage pre-training strategy to build a multi-modality model with a large amount of labeled and unlabeled data. We then fine-tune the corresponding components of the model for the downstream speech translation tasks. Moreover, we make various efforts to improve performance, such as data filtering, data augmentation, speech segmentation, model ensemble, and so on. Experimental results show that our YiTrans system obtains a significant improvement than the strong baseline on three translation directions, and it achieves +5.2 BLEU improvements over last year's optimal end-to-end system on tst2021 English-German. Our final submissions rank first on English-German and English-Chinese end-to-end systems in terms of the automatic evaluation metric. We make our code and models publicly available.
Ultra Fast Speech Separation Model with Teacher Student Learning
Apr 27, 2022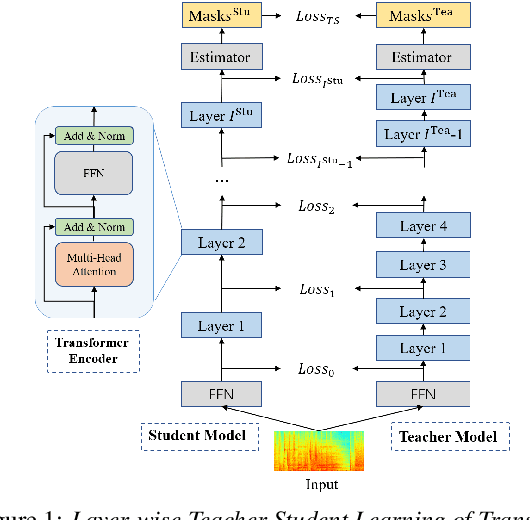
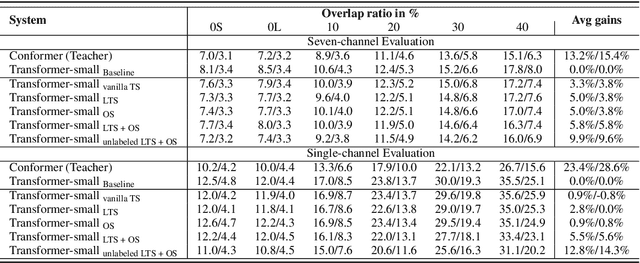
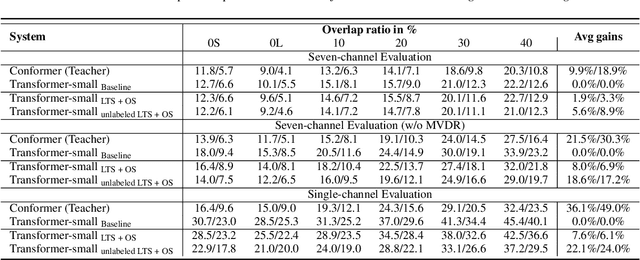
Transformer has been successfully applied to speech separation recently with its strong long-dependency modeling capacity using a self-attention mechanism. However, Transformer tends to have heavy run-time costs due to the deep encoder layers, which hinders its deployment on edge devices. A small Transformer model with fewer encoder layers is preferred for computational efficiency, but it is prone to performance degradation. In this paper, an ultra fast speech separation Transformer model is proposed to achieve both better performance and efficiency with teacher student learning (T-S learning). We introduce layer-wise T-S learning and objective shifting mechanisms to guide the small student model to learn intermediate representations from the large teacher model. Compared with the small Transformer model trained from scratch, the proposed T-S learning method reduces the word error rate (WER) by more than 5% for both multi-channel and single-channel speech separation on LibriCSS dataset. Utilizing more unlabeled speech data, our ultra fast speech separation models achieve more than 10% relative WER reduction.