 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Quantum Computers Learn Like Classical Computers? A Co-Design Framework for Machine Learning and Quantum Circuits
Jun 26, 2020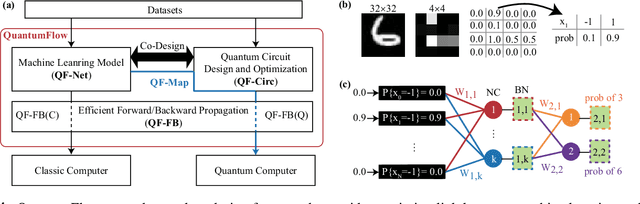
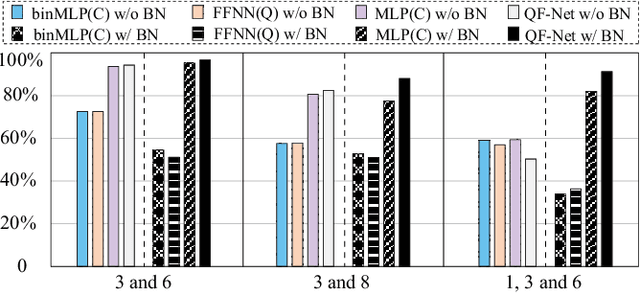
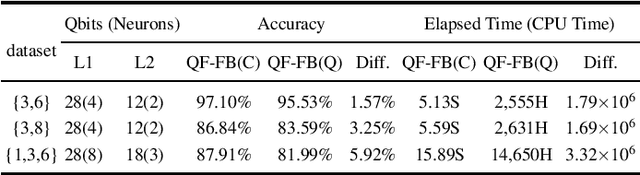
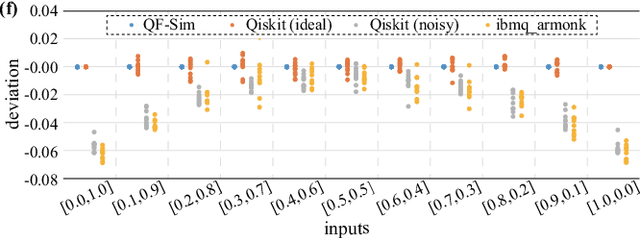
Despite the pursuit of quantum supremacy in various applications, the power of quantum computers in machine learning (such as neural network models) has mostly remained unknown, primarily due to a missing link that effectively designs a neural network model suitable for quantum circuit implementation. In this article, we present the first co-design framework, namely QuantumFlow, to fixed the missing link. QuantumFlow consists of a novel quantum-friendly neural network (QF-Net) design, an automatic tool (QF-Map) to generate the quantum circuit (QF-Circ) for QF-Net, and a theoretic-based execution engine (QF-FB) to efficiently support the training of QF-Net on a classical computer. We discover that, in order to make full use of the strength of quantum representation, data in QF-Net is best modeled as random variables rather than real numbers. Moreover, instead of using the classical batch normalization (which is key to achieve high accuracy for deep neural networks), a quantum-aware batch normalization method is proposed for QF-Net. Evaluation results show that QF-Net can achieve 97.01% accuracy in distinguishing digits 3 and 6 in the widely used MNIST dataset, which is 14.55% higher than the state-of-the-art quantum-aware implementation. A case study on a binary classification application is conducted. Running on IBM Quantum processor's "ibmq_essex" backend, a neural network designed by QuantumFlow can achieve 82% accuracy. To the best of our knowledge, QuantumFlow is the first framework that co-designs both the machine learning model and its quantum circuit.
Fast Learning of Graph Neural Networks with Guaranteed Generalizability: One-hidden-layer Case
Jun 25, 2020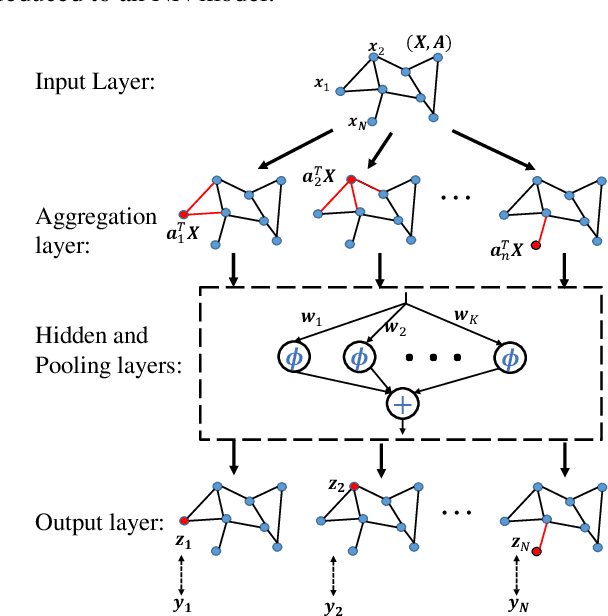
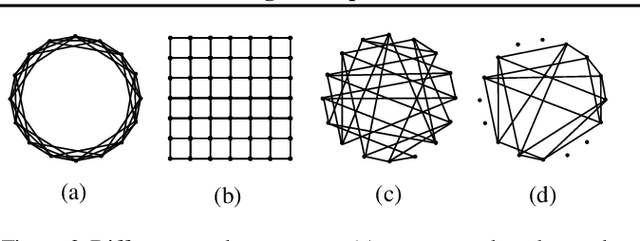
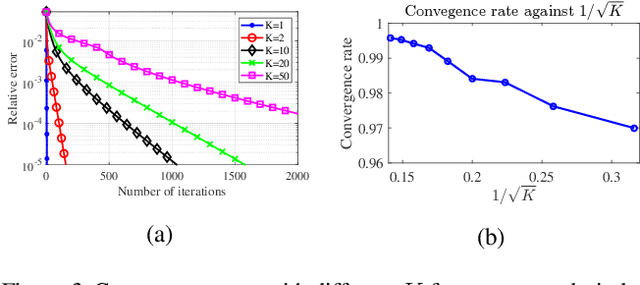
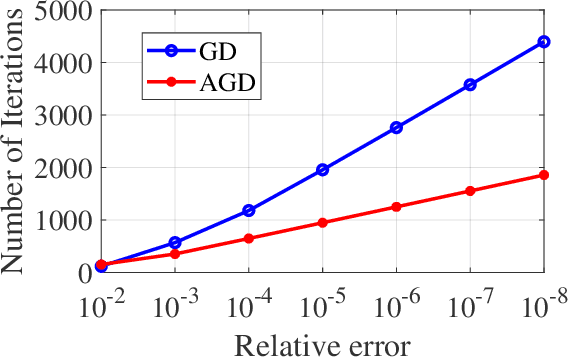
Although graph neural networks (GNNs) have made great progress recently on learning from graph-structured data in practice, their theoretical guarantee on generalizability remains elusive in the literature. In this paper, we provide a theoretically-grounded generalizability analysis of GNNs with one hidden layer for both regression and binary classification problems. Under the assumption that there exists a ground-truth GNN model (with zero generalization error), the objective of GNN learning is to estimate the ground-truth GNN parameters from the training data. To achieve this objective, we propose a learning algorithm that is built on tensor initialization and accelerated gradient descent. We then show that the proposed learning algorithm converges to the ground-truth GNN model for the regression problem, and to a model sufficiently close to the ground-truth for the binary classification problem. Moreover, for both cases, the convergence rate of the proposed learning algorithm is proven to be linear and faster than the vanilla gradient descent algorithm. We further explore the relationship between the sample complexity of GNNs and their underlying graph properties. Lastly, we provide numerical experiments to demonstrate the validity of our analysis and the effectiveness of the proposed learning algorithm for GNNs.
A Multi-Perspective Architecture for Semantic Code Search
May 06, 2020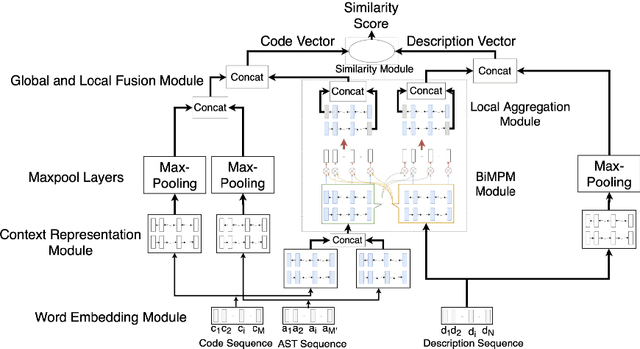
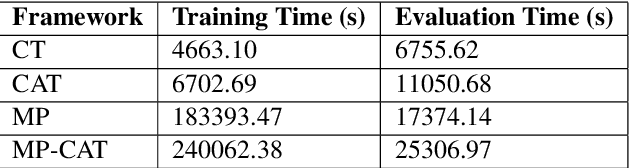
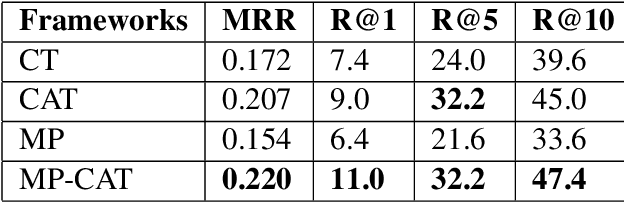

The ability to match pieces of code to their corresponding natural language descriptions and vice versa is fundamental for natural language search interfaces to software repositories. In this paper, we propose a novel multi-perspective cross-lingual neural framework for code--text matching, inspired in part by a previous model for monolingual text-to-text matching, to capture both global and local similarities. Our experiments on the CoNaLa dataset show that our proposed model yields better performance on this cross-lingual text-to-code matching task than previous approaches that map code and text to a single joint embedding space.
EDD: Efficient Differentiable DNN Architecture and Implementation Co-search for Embedded AI Solutions
May 06, 2020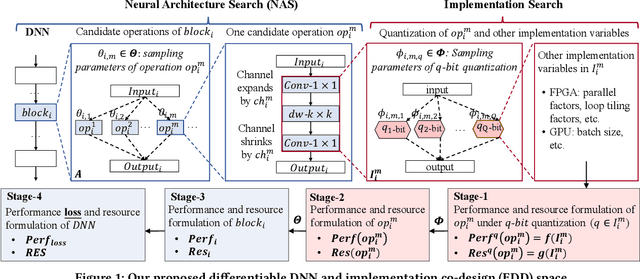
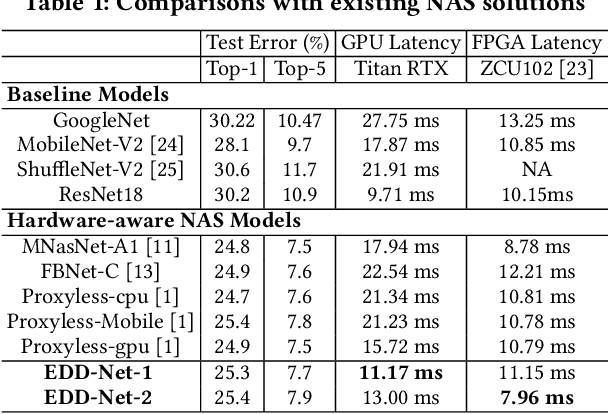
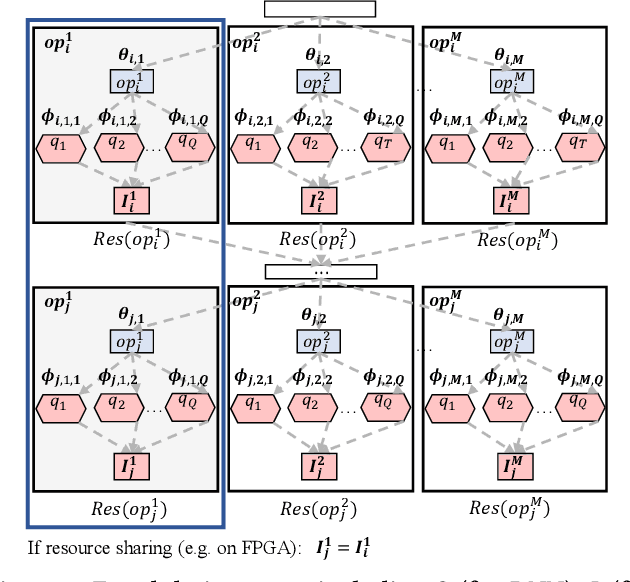
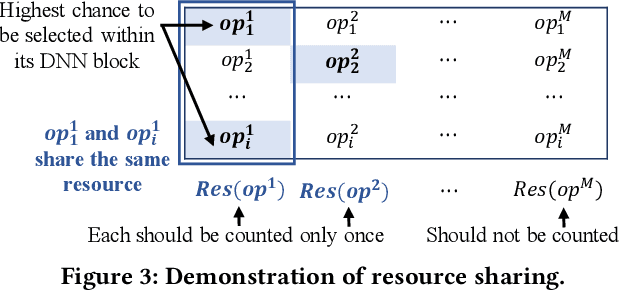
High quality AI solutions require joint optimization of AI algorithms and their hardware implementations. In this work, we are the first to propose a fully simultaneous, efficient differentiable DNN architecture and implementation co-search (EDD) methodology. We formulate the co-search problem by fusing DNN search variables and hardware implementation variables into one solution space, and maximize both algorithm accuracy and hardware implementation quality. The formulation is differentiable with respect to the fused variables, so that gradient descent algorithm can be applied to greatly reduce the search time. The formulation is also applicable for various devices with different objectives. In the experiments, we demonstrate the effectiveness of our EDD methodology by searching for three representative DNNs, targeting low-latency GPU implementation and FPGA implementations with both recursive and pipelined architectures. Each model produced by EDD achieves similar accuracy as the best existing DNN models searched by neural architecture search (NAS) methods on ImageNet, but with superior performance obtained within 12 GPU-hour searches. Our DNN targeting GPU is 1.40x faster than the state-of-the-art solution reported in Proxyless, and our DNN targeting FPGA delivers 1.45x higher throughput than the state-of-the-art solution reported in DNNBuilder.
Differential Treatment for Stuff and Things: A Simple Unsupervised Domain Adaptation Method for Semantic Segmentation
Apr 22, 2020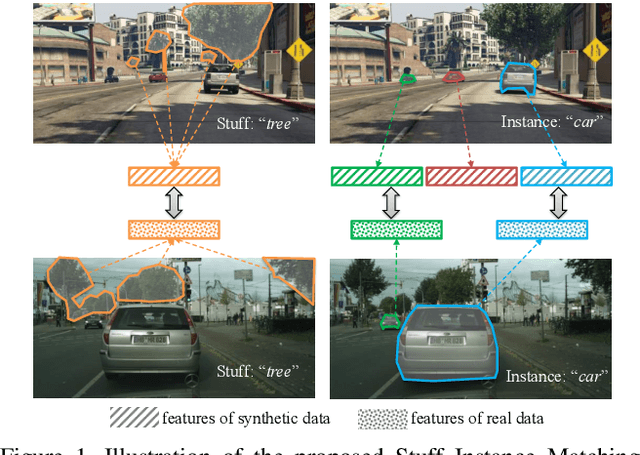
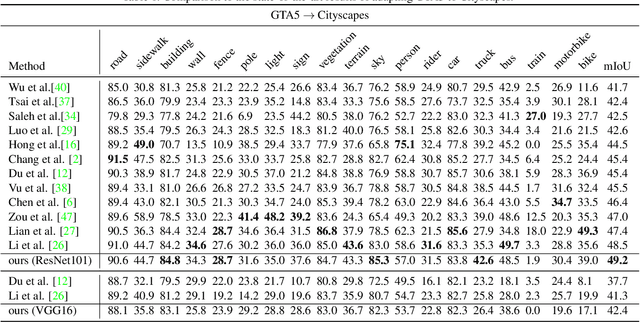
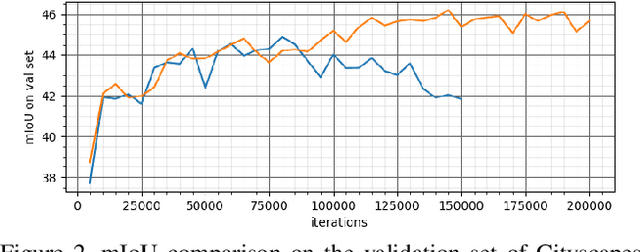
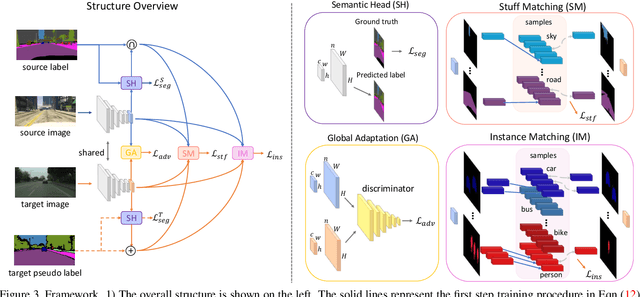
We consider the problem of unsupervised domain adaptation for semantic segmentation by easing the domain shift between the source domain (synthetic data) and the target domain (real data) in this work. State-of-the-art approaches prove that performing semantic-level alignment is helpful in tackling the domain shift issue. Based on the observation that stuff categories usually share similar appearances across images of different domains while things (i.e. object instances) have much larger differences, we propose to improve the semantic-level alignment with different strategies for stuff regions and for things: 1) for the stuff categories, we generate feature representation for each class and conduct the alignment operation from the target domain to the source domain; 2) for the thing categories, we generate feature representation for each individual instance and encourage the instance in the target domain to align with the most similar one in the source domain. In this way, the individual differences within thing categories will also be considered to alleviate over-alignment. In addition to our proposed method, we further reveal the reason why the current adversarial loss is often unstable in minimizing the distribution discrepancy and show that our method can help ease this issue by minimizing the most similar stuff and instance features between the source and the target domains. We conduct extensive experiments in two unsupervised domain adaptation tasks, i.e. GTA5 to Cityscapes and SYNTHIA to Cityscapes, and achieve the new state-of-the-art segmentation accuracy.
Alleviating Semantic-level Shift: A Semi-supervised Domain Adaptation Method for Semantic Segmentation
Apr 02, 2020
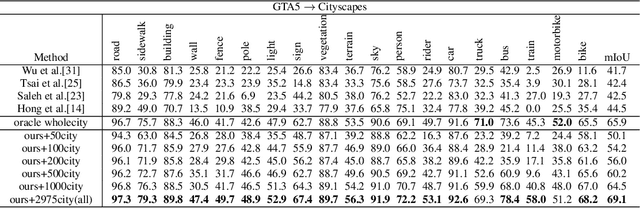
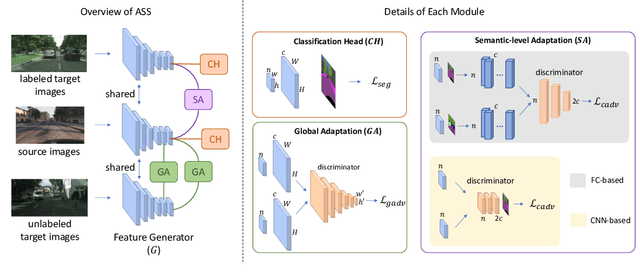
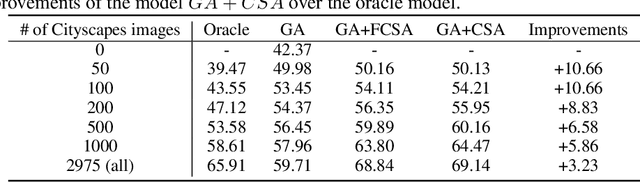
Learning segmentation from synthetic data and adapting to real data can significantly relieve human efforts in labelling pixel-level masks. A key challenge of this task is how to alleviate the data distribution discrepancy between the source and target domains, i.e. reducing domain shift. The common approach to this problem is to minimize the discrepancy between feature distributions from different domains through adversarial training. However, directly aligning the feature distribution globally cannot guarantee consistency from a local view (i.e. semantic-level), which prevents certain semantic knowledge learned on the source domain from being applied to the target domain. To tackle this issue, we propose a semi-supervised approach named Alleviating Semantic-level Shift (ASS), which can successfully promote the distribution consistency from both global and local views. Specifically, leveraging a small number of labeled data from the target domain, we directly extract semantic-level feature representations from both the source and the target domains by averaging the features corresponding to same categories advised by pixel-level masks. We then feed the produced features to the discriminator to conduct semantic-level adversarial learning, which collaborates with the adversarial learning from the global view to better alleviate the domain shift. We apply our ASS to two domain adaptation tasks, from GTA5 to Cityscapes and from Synthia to Cityscapes. Extensive experiments demonstrate that: (1) ASS can significantly outperform the current unsupervised state-of-the-arts by employing a small number of annotated samples from the target domain; (2) ASS can beat the oracle model trained on the whole target dataset by over 3 points by augmenting the synthetic source data with annotated samples from the target domain without suffering from the prevalent problem of overfitting to the source domain.
Multi-Cycle-Consistent Adversarial Networks for CT Image Denoising
Feb 27, 2020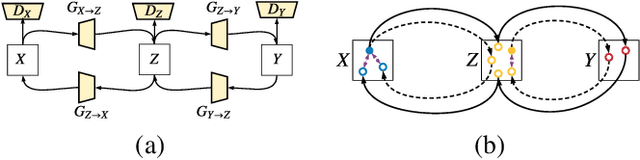
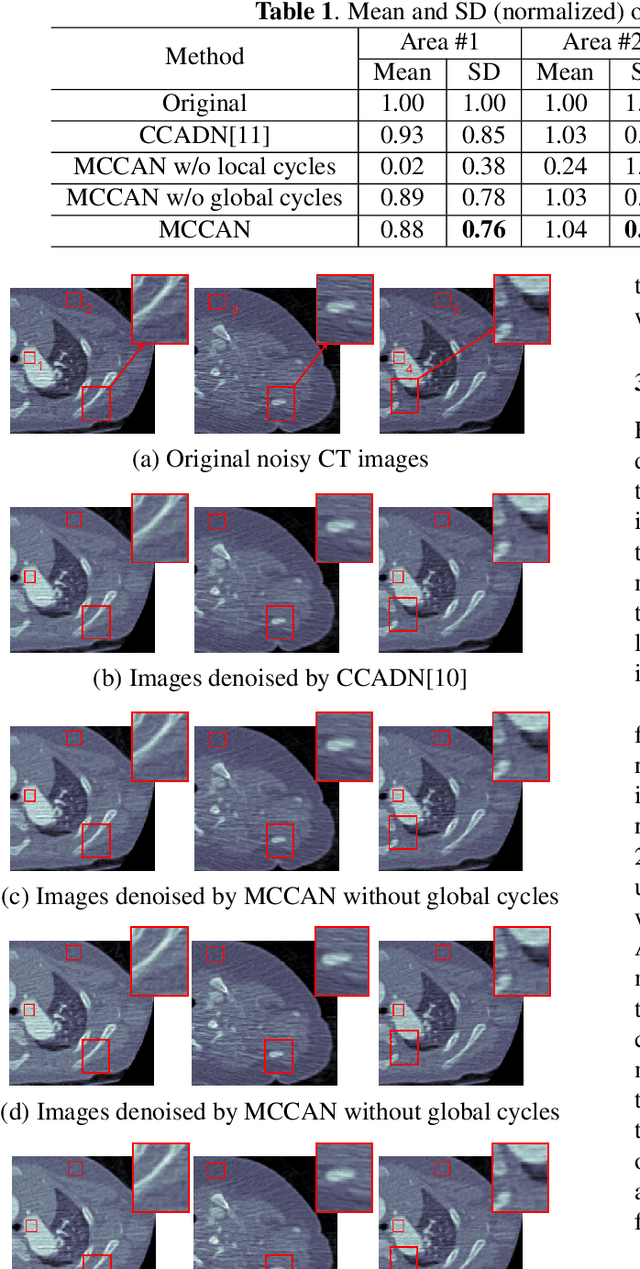
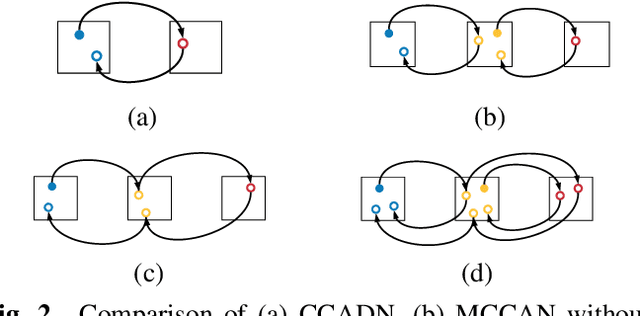
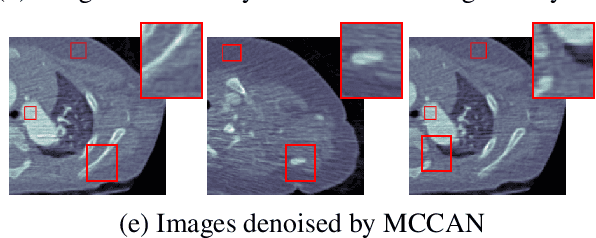
CT image denoising can be treated as an image-to-image translation task where the goal is to learn the transform between a source domain $X$ (noisy images) and a target domain $Y$ (clean images). Recently, cycle-consistent adversarial denoising network (CCADN) has achieved state-of-the-art results by enforcing cycle-consistent loss without the need of paired training data. Our detailed analysis of CCADN raises a number of interesting questions. For example, if the noise is large leading to significant difference between domain $X$ and domain $Y$, can we bridge $X$ and $Y$ with an intermediate domain $Z$ such that both the denoising process between $X$ and $Z$ and that between $Z$ and $Y$ are easier to learn? As such intermediate domains lead to multiple cycles, how do we best enforce cycle-consistency? Driven by these questions, we propose a multi-cycle-consistent adversarial network (MCCAN) that builds intermediate domains and enforces both local and global cycle-consistency. The global cycle-consistency couples all generators together to model the whole denoising process, while the local cycle-consistency imposes effective supervision on the process between adjacent domains. Experiments show that both local and global cycle-consistency are important for the success of MCCAN, which outperforms the state-of-the-art.
DLSpec: A Deep Learning Task Exchange Specification
Feb 26, 2020
Deep Learning (DL) innovations are being introduced at a rapid pace. However, the current lack of standard specification of DL tasks makes sharing, running, reproducing, and comparing these innovations difficult. To address this problem, we propose DLSpec, a model-, dataset-, software-, and hardware-agnostic DL specification that captures the different aspects of DL tasks. DLSpec has been tested by specifying and running hundreds of DL tasks.
MLModelScope: A Distributed Platform for Model Evaluation and Benchmarking at Scale
Feb 19, 2020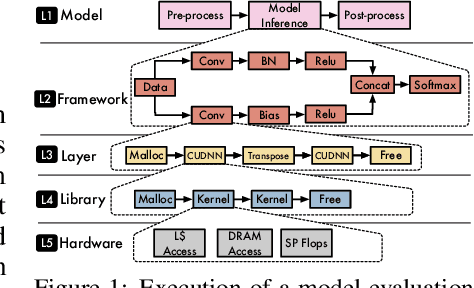
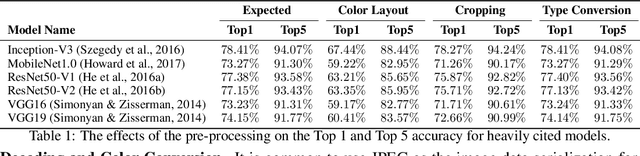
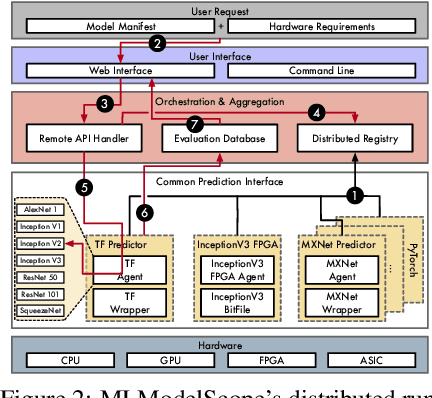

Machine Learning (ML) and Deep Learning (DL) innovations are being introduced at such a rapid pace that researchers are hard-pressed to analyze and study them. The complicated procedures for evaluating innovations, along with the lack of standard and efficient ways of specifying and provisioning ML/DL evaluation, is a major "pain point" for the community. This paper proposes MLModelScope, an open-source, framework/hardware agnostic, extensible and customizable design that enables repeatable, fair, and scalable model evaluation and benchmarking. We implement the distributed design with support for all major frameworks and hardware, and equip it with web, command-line, and library interfaces. To demonstrate MLModelScope's capabilities we perform parallel evaluation and show how subtle changes to model evaluation pipeline affects the accuracy and HW/SW stack choices affect performance.
On Interpretability of Artificial Neural Networks
Jan 08, 2020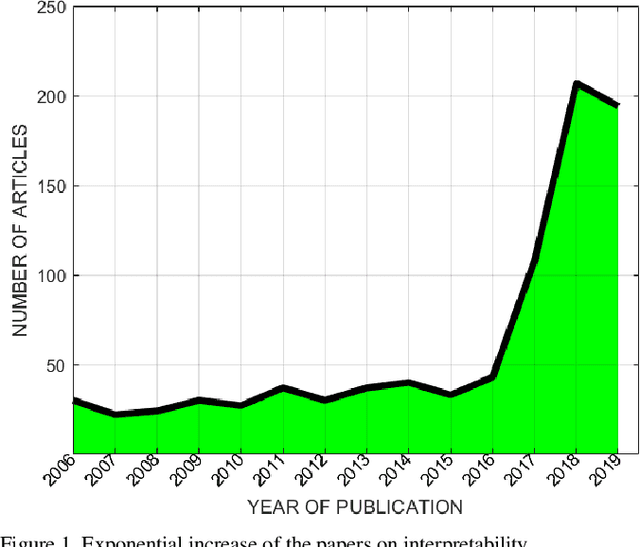
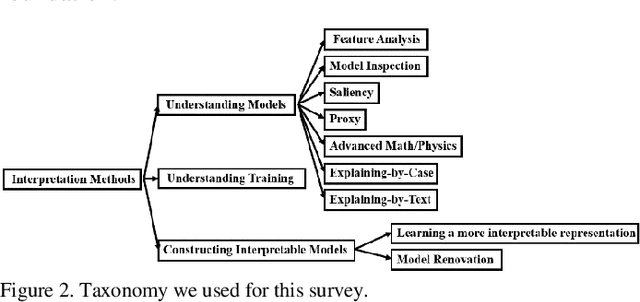

Deep learning has achieved great successes in many important areas to dealing with text, images, video, graphs, and so on. However, the black-box nature of deep artificial neural networks has become the primary obstacle to their public acceptance and wide popularity in critical applications such as diagnosis and therapy. Due to the huge potential of deep learning, interpreting neural networks has become one of the most critical research directions. In this paper, we systematically review recent studies in understanding the mechanism of neural networks and shed light on some future directions of interpretability research (This work is still in progress).