 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDivergence Meets Consensus: A Multi-Source Negative Sampling Framework for Sequential Recommendation
May 19, 2026Negative sampling is significant for training sequential recommendation models under implicit feedback. The predominant strategy, self-guided hard negative sampling, selects negatives based on the model's current state but suffers from three limitations: (1) the coupling between sampling and model updates triggers a vicious cycle that drives the model into local optima; (2) relying on current model parameters narrows sampling to a small region of the item space, reducing diversity and harming generalization; (3) identifying a hard negative requires scoring the entire candidate pool, causing substantial computational overhead with minimal information gain. To address these challenges, we propose MDCNS (Multi-source Divergence-Consensus for Negative Sampling), a novel "Teacher-Peer-Self" framework inspired by Vygotsky's Zone of Proximal Development (ZPD) theory. The proposed method comprises three components, including multi-source scoring, divergence re-ranking, and consensus distillation. Firstly, multi-source scoring incorporates peer and ensemble teacher models to inject external negative signals and break the self-reinforcement loop. Then, divergence re-ranking exploits prediction discrepancy between self and peer models to enhance sampling diversity. Finally, consensus distillation aligns the self model with the teacher via KL divergence, simultaneously improving computational cost utilization. Extensive experiments on six real-world datasets and five backbone models show that MDCNS consistently outperforms state-of-the-art negative sampling methods, demonstrating strong effectiveness and generalization.
PaMoSplat: Part-Aware Motion-Guided Gaussian Splatting for Dynamic Scene Reconstruction
May 11, 2026Dynamic scene reconstruction represents a fundamental yet demanding challenge in computer vision and robotics. While recent progress in 3DGS-based methods has advanced dynamic scene modeling, obtaining high-fidelity rendering and accurate tracking in scenarios with substantial, intricate motions remains significantly challenging. To address these challenges, we propose PaMoSplat, a novel dynamic Gaussian splatting framework incorporating part awareness and motion priors. Our approach is grounded in two key observations: 1) Parts serve as primitives for scene deformation, and 2) Motion cues from optical flow can effectively guide part motion. Specifically, PaMoSplat initializes by lifting multi-view segmentation masks into 3D space via graph clustering, establishing coherent Gaussian parts. For subsequent timestamps, we leverage a differential evolutionary algorithm to estimate the rigid motion of these parts using multi-view optical flow cues, providing a robust warm-start for further optimization. Additionally, PaMoSplat introduces an adaptive iteration count mechanism, internal learnable rigidity, and flow-supervised rendering loss to accelerate and optimize the training process. Comprehensive evaluations across diverse scenes, including real-world environments, demonstrate that PaMoSplat delivers superior rendering quality, improved tracking precision, and faster convergence compared to existing methods. Furthermore, it enables multiple part-level downstream applications, such as 4D scene editing.
OmniMap: A General Mapping Framework Integrating Optics, Geometry, and Semantics
Sep 09, 2025Robotic systems demand accurate and comprehensive 3D environment perception, requiring simultaneous capture of photo-realistic appearance (optical), precise layout shape (geometric), and open-vocabulary scene understanding (semantic). Existing methods typically achieve only partial fulfillment of these requirements while exhibiting optical blurring, geometric irregularities, and semantic ambiguities. To address these challenges, we propose OmniMap. Overall, OmniMap represents the first online mapping framework that simultaneously captures optical, geometric, and semantic scene attributes while maintaining real-time performance and model compactness. At the architectural level, OmniMap employs a tightly coupled 3DGS-Voxel hybrid representation that combines fine-grained modeling with structural stability. At the implementation level, OmniMap identifies key challenges across different modalities and introduces several innovations: adaptive camera modeling for motion blur and exposure compensation, hybrid incremental representation with normal constraints, and probabilistic fusion for robust instance-level understanding. Extensive experiments show OmniMap's superior performance in rendering fidelity, geometric accuracy, and zero-shot semantic segmentation compared to state-of-the-art methods across diverse scenes. The framework's versatility is further evidenced through a variety of downstream applications, including multi-domain scene Q&A, interactive editing, perception-guided manipulation, and map-assisted navigation.
Homophily Enhanced Graph Domain Adaptation
May 26, 2025



Graph Domain Adaptation (GDA) transfers knowledge from labeled source graphs to unlabeled target graphs, addressing the challenge of label scarcity. In this paper, we highlight the significance of graph homophily, a pivotal factor for graph domain alignment, which, however, has long been overlooked in existing approaches. Specifically, our analysis first reveals that homophily discrepancies exist in benchmarks. Moreover, we also show that homophily discrepancies degrade GDA performance from both empirical and theoretical aspects, which further underscores the importance of homophily alignment in GDA. Inspired by this finding, we propose a novel homophily alignment algorithm that employs mixed filters to smooth graph signals, thereby effectively capturing and mitigating homophily discrepancies between graphs. Experimental results on a variety of benchmarks verify the effectiveness of our method.
OpenObj: Open-Vocabulary Object-Level Neural Radiance Fields with Fine-Grained Understanding
Jun 12, 2024In recent years, there has been a surge of interest in open-vocabulary 3D scene reconstruction facilitated by visual language models (VLMs), which showcase remarkable capabilities in open-set retrieval. However, existing methods face some limitations: they either focus on learning point-wise features, resulting in blurry semantic understanding, or solely tackle object-level reconstruction, thereby overlooking the intricate details of the object's interior. To address these challenges, we introduce OpenObj, an innovative approach to build open-vocabulary object-level Neural Radiance Fields (NeRF) with fine-grained understanding. In essence, OpenObj establishes a robust framework for efficient and watertight scene modeling and comprehension at the object-level. Moreover, we incorporate part-level features into the neural fields, enabling a nuanced representation of object interiors. This approach captures object-level instances while maintaining a fine-grained understanding. The results on multiple datasets demonstrate that OpenObj achieves superior performance in zero-shot semantic segmentation and retrieval tasks. Additionally, OpenObj supports real-world robotics tasks at multiple scales, including global movement and local manipulation.
OpenGraph: Open-Vocabulary Hierarchical 3D Graph Representation in Large-Scale Outdoor Environments
Mar 28, 2024



Environment representations endowed with sophisticated semantics are pivotal for facilitating seamless interaction between robots and humans, enabling them to effectively carry out various tasks. Open-vocabulary maps, powered by Visual-Language models (VLMs), possess inherent advantages, including zero-shot learning and support for open-set classes. However, existing open-vocabulary maps are primarily designed for small-scale environments, such as desktops or rooms, and are typically geared towards limited-area tasks involving robotic indoor navigation or in-place manipulation. They face challenges in direct generalization to outdoor environments characterized by numerous objects and complex tasks, owing to limitations in both understanding level and map structure. In this work, we propose OpenGraph, the first open-vocabulary hierarchical graph representation designed for large-scale outdoor environments. OpenGraph initially extracts instances and their captions from visual images, enhancing textual reasoning by encoding them. Subsequently, it achieves 3D incremental object-centric mapping with feature embedding by projecting images onto LiDAR point clouds. Finally, the environment is segmented based on lane graph connectivity to construct a hierarchical graph. Validation results from public dataset SemanticKITTI demonstrate that OpenGraph achieves the highest segmentation and query accuracy. The source code of OpenGraph is publicly available at https://github.com/BIT-DYN/OpenGraph.
Uncovering Selective State Space Model's Capabilities in Lifelong Sequential Recommendation
Mar 25, 2024



Sequential Recommenders have been widely applied in various online services, aiming to model users' dynamic interests from their sequential interactions. With users increasingly engaging with online platforms, vast amounts of lifelong user behavioral sequences have been generated. However, existing sequential recommender models often struggle to handle such lifelong sequences. The primary challenges stem from computational complexity and the ability to capture long-range dependencies within the sequence. Recently, a state space model featuring a selective mechanism (i.e., Mamba) has emerged. In this work, we investigate the performance of Mamba for lifelong sequential recommendation (i.e., length>=2k). More specifically, we leverage the Mamba block to model lifelong user sequences selectively. We conduct extensive experiments to evaluate the performance of representative sequential recommendation models in the setting of lifelong sequences. Experiments on two real-world datasets demonstrate the superiority of Mamba. We found that RecMamba achieves performance comparable to the representative model while significantly reducing training duration by approximately 70% and memory costs by 80%. Codes and data are available at \url{https://github.com/nancheng58/RecMamba}.
Non-volatile Reconfigurable Digital Optical Diffractive Neural Network Based on Phase Change Material
May 18, 2023



Optical diffractive neural networks have triggered extensive research with their low power consumption and high speed in image processing. In this work, we propose a reconfigurable digital all-optical diffractive neural network (R-ODNN) structure. The optical neurons are built with Sb2Se3 phase-change material, making our network reconfigurable, digital, and non-volatile. Using three digital diffractive layers with 14,400 neurons on each and 10 photodetectors connected to a resistor network, our model achieves 94.46% accuracy for handwritten digit recognition. We also performed full-vector simulations and discussed the impact of errors to demonstrate the feasibility and robustness of the R-ODNN.
Cross-Layer Retrospective Retrieving via Layer Attention
Feb 28, 2023



More and more evidence has shown that strengthening layer interactions can enhance the representation power of a deep neural network, while self-attention excels at learning interdependencies by retrieving query-activated information. Motivated by this, we devise a cross-layer attention mechanism, called multi-head recurrent layer attention (MRLA), that sends a query representation of the current layer to all previous layers to retrieve query-related information from different levels of receptive fields. A light-weighted version of MRLA is also proposed to reduce the quadratic computation cost. The proposed layer attention mechanism can enrich the representation power of many state-of-the-art vision networks, including CNNs and vision transformers. Its effectiveness has been extensively evaluated in image classification, object detection and instance segmentation tasks, where improvements can be consistently observed. For example, our MRLA can improve 1.6% Top-1 accuracy on ResNet-50, while only introducing 0.16M parameters and 0.07B FLOPs. Surprisingly, it can boost the performances by a large margin of 3-4% box AP and mask AP in dense prediction tasks. Our code is available at https://github.com/joyfang1106/MRLA.
Recurrence along Depth: Deep Convolutional Neural Networks with Recurrent Layer Aggregation
Oct 22, 2021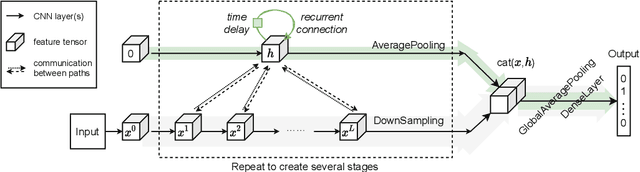
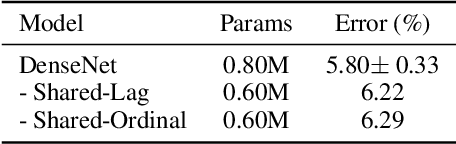
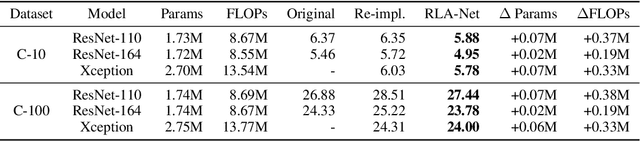
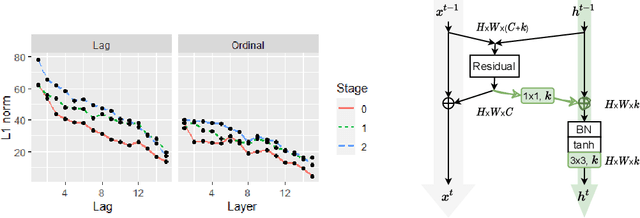
This paper introduces a concept of layer aggregation to describe how information from previous layers can be reused to better extract features at the current layer. While DenseNet is a typical example of the layer aggregation mechanism, its redundancy has been commonly criticized in the literature. This motivates us to propose a very light-weighted module, called recurrent layer aggregation (RLA), by making use of the sequential structure of layers in a deep CNN. Our RLA module is compatible with many mainstream deep CNNs, including ResNets, Xception and MobileNetV2, and its effectiveness is verified by our extensive experiments on image classification, object detection and instance segmentation tasks. Specifically, improvements can be uniformly observed on CIFAR, ImageNet and MS COCO datasets, and the corresponding RLA-Nets can surprisingly boost the performances by 2-3% on the object detection task. This evidences the power of our RLA module in helping main CNNs better learn structural information in images.