 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDivergence Meets Consensus: A Multi-Source Negative Sampling Framework for Sequential Recommendation
May 19, 2026Negative sampling is significant for training sequential recommendation models under implicit feedback. The predominant strategy, self-guided hard negative sampling, selects negatives based on the model's current state but suffers from three limitations: (1) the coupling between sampling and model updates triggers a vicious cycle that drives the model into local optima; (2) relying on current model parameters narrows sampling to a small region of the item space, reducing diversity and harming generalization; (3) identifying a hard negative requires scoring the entire candidate pool, causing substantial computational overhead with minimal information gain. To address these challenges, we propose MDCNS (Multi-source Divergence-Consensus for Negative Sampling), a novel "Teacher-Peer-Self" framework inspired by Vygotsky's Zone of Proximal Development (ZPD) theory. The proposed method comprises three components, including multi-source scoring, divergence re-ranking, and consensus distillation. Firstly, multi-source scoring incorporates peer and ensemble teacher models to inject external negative signals and break the self-reinforcement loop. Then, divergence re-ranking exploits prediction discrepancy between self and peer models to enhance sampling diversity. Finally, consensus distillation aligns the self model with the teacher via KL divergence, simultaneously improving computational cost utilization. Extensive experiments on six real-world datasets and five backbone models show that MDCNS consistently outperforms state-of-the-art negative sampling methods, demonstrating strong effectiveness and generalization.
HAPS: Hierarchical LLM Routing with Joint Architecture and Parameter Search
Jan 09, 2026Large language model (LLM) routing aims to exploit the specialized strengths of different LLMs for diverse tasks. However, existing approaches typically focus on selecting LLM architectures while overlooking parameter settings, which are critical for task performance. In this paper, we introduce HAPS, a hierarchical LLM routing framework that jointly searches over model architectures and parameters. Specifically, we use a high-level router to select among candidate LLM architectures, and then search for the optimal parameters for the selected architectures based on a low-level router. We design a parameter generation network to share parameters between the two routers to mutually enhance their capabilities. In the training process, we design a reward-augmented objective to effectively optimize our framework. Experiments on two commonly used benchmarks show that HAPS consistently outperforms strong routing baselines. We have released our code at https://github.com/zihangtian/HAPS.
HF4Rec: Human-Like Feedback-Driven Optimization Framework for Explainable Recommendation
Apr 19, 2025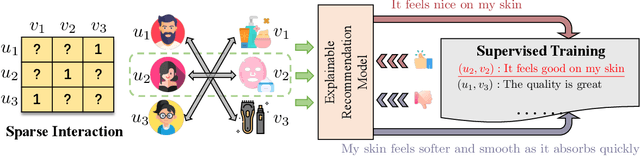

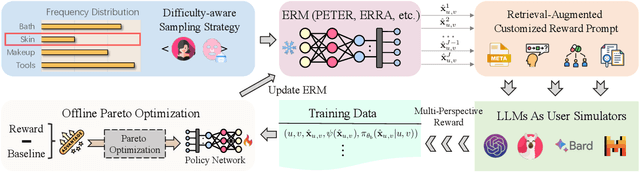
Recent advancements in explainable recommendation have greatly bolstered user experience by elucidating the decision-making rationale. However, the existing methods actually fail to provide effective feedback signals for potentially better or worse generated explanations due to their reliance on traditional supervised learning paradigms in sparse interaction data. To address these issues, we propose a novel human-like feedback-driven optimization framework. This framework employs a dynamic interactive optimization mechanism for achieving human-centered explainable requirements without incurring high labor costs. Specifically, we propose to utilize large language models (LLMs) as human simulators to predict human-like feedback for guiding the learning process. To enable the LLMs to deeply understand the task essence and meet user's diverse personalized requirements, we introduce a human-induced customized reward scoring method, which helps stimulate the language understanding and logical reasoning capabilities of LLMs. Furthermore, considering the potential conflicts between different perspectives of explanation quality, we introduce a principled Pareto optimization that transforms the multi-perspective quality enhancement task into a multi-objective optimization problem for improving explanation performance. At last, to achieve efficient model training, we design an off-policy optimization pipeline. By incorporating a replay buffer and addressing the data distribution biases, we can effectively improve data utilization and enhance model generality. Extensive experiments on four datasets demonstrate the superiority of our approach.
Enhancing Recommendation Explanations through User-Centric Refinement
Feb 17, 2025



Generating natural language explanations for recommendations has become increasingly important in recommender systems. Traditional approaches typically treat user reviews as ground truth for explanations and focus on improving review prediction accuracy by designing various model architectures. However, due to limitations in data scale and model capability, these explanations often fail to meet key user-centric aspects such as factuality, personalization, and sentiment coherence, significantly reducing their overall helpfulness to users. In this paper, we propose a novel paradigm that refines initial explanations generated by existing explainable recommender models during the inference stage to enhance their quality in multiple aspects. Specifically, we introduce a multi-agent collaborative refinement framework based on large language models. To ensure alignment between the refinement process and user demands, we employ a plan-then-refine pattern to perform targeted modifications. To enable continuous improvements, we design a hierarchical reflection mechanism that provides feedback on the refinement process from both strategic and content perspectives. Extensive experiments on three datasets demonstrate the effectiveness of our framework.
CharacterEval: A Chinese Benchmark for Role-Playing Conversational Agent Evaluation
Jan 09, 2024Recently, the advent of large language models (LLMs) has revolutionized generative agents. Among them, Role-Playing Conversational Agents (RPCAs) attract considerable attention due to their ability to emotionally engage users. However, the absence of a comprehensive benchmark impedes progress in this field. To bridge this gap, we introduce CharacterEval, a Chinese benchmark for comprehensive RPCA assessment, complemented by a tailored high-quality dataset. The dataset comprises 1,785 multi-turn role-playing dialogues, encompassing 23,020 examples and featuring 77 characters derived from Chinese novels and scripts. It was carefully constructed, beginning with initial dialogue extraction via GPT-4, followed by rigorous human-led quality control, and enhanced with in-depth character profiles sourced from Baidu Baike. CharacterEval employs a multifaceted evaluation approach, encompassing thirteen targeted metrics on four dimensions. Comprehensive experiments on CharacterEval demonstrate that Chinese LLMs exhibit more promising capabilities than GPT-4 in Chinese role-playing conversation. Source code, data source and reward model will be publicly accessible at https://github.com/morecry/CharacterEval.