 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFull spectrum Unlearnable Examples via Spectral Equalization
Jun 25, 2026Unlearnable examples (UEs) protect training data by injecting imperceptible perturbations so that models fail to extract exploitable representations. In this paper, we reveal that existing UEs exhibit a critical failure once low-pass filtering is applied, indicating that the effective perturbation signals for unlearnability concentrate predominantly in high frequencies. Hence, we argue that reliable UEs should remain effective across the full spectrum. To this end, we propose Full-spectrum Unlearnable examples via Spectral Equalization (FUSE), which aims to generate spectrum-agnostic perturbations by equalizing the contributions from different bands and enforcing cross-band consistency. Specifically, FUSE adopts a Random Spectral Masking (RSM) strategy during generator training, which randomly removes a contiguous frequency band, forcing the remaining bands to maintain unlearnability. In addition, FUSE further integrates Cross-Band Guidance (CBG), which enforces mutual consistency between high- and low-frequency components, thereby further enhancing low-frequency unlearnability and regulating high-frequency perturbations to preserve the semantic fidelity of images. Extensive experiments across multiple datasets, architectures, and spectral filtering demonstrate the strong protection achieved by FUSE.
Baguan-TS: A Sequence-Native In-Context Learning Model for Time Series Forecasting with Covariates
Mar 18, 2026Transformers enable in-context learning (ICL) for rapid, gradient-free adaptation in time series forecasting, yet most ICL-style approaches rely on tabularized, hand-crafted features, while end-to-end sequence models lack inference-time adaptation. We bridge this gap with a unified framework, Baguan-TS, which integrates the raw-sequence representation learning with ICL, instantiated by a 3D Transformer that attends jointly over temporal, variable, and context axes. To make this high-capacity model practical, we tackle two key hurdles: (i) calibration and training stability, improved with a feature-agnostic, target-space retrieval-based local calibration; and (ii) output oversmoothing, mitigated via context-overfitting strategy. On public benchmark with covariates, Baguan-TS consistently outperforms established baselines, achieving the highest win rate and significant reductions in both point and probabilistic forecasting metrics. Further evaluations across diverse real-world energy datasets demonstrate its robustness, yielding substantial improvements.
When Priors Backfire: On the Vulnerability of Unlearnable Examples to Pretraining
Mar 05, 2026Unlearnable Examples (UEs) serve as a data protection strategy that generates imperceptible perturbations to mislead models into learning spurious correlations instead of underlying semantics. In this paper, we uncover a fundamental vulnerability of UEs that emerges when learning starts from a pretrained model. Crucially, our empirical analysis shows that even when data are protected by carefully crafted perturbations, pretraining priors still furnish rich semantic representations that allow the model to circumvent the shortcuts introduced by UEs and capture genuine features, thereby nullifying unlearnability. To address this, we propose BAIT (Binding Artificial perturbations to Incorrect Targets), a novel bi-level optimization formulation. Specifically, the inner level aims at associating the perturbed samples with real labels to simulate standard data-label alignment, while the outer level actively disrupts this alignment by enforcing a mislabel-perturbation binding that maps samples to designated incorrect targets. This mechanism effectively overrides the semantic guidance of priors, forcing the model to rely on the injected perturbations and consequently preventing the acquisition of true semantics. Extensive experiments on standard benchmarks and multiple pretrained backbones demonstrate that BAIT effectively mitigates the influence of pretraining priors and maintains data unlearnability.
Homophily Enhanced Graph Domain Adaptation
May 26, 2025



Graph Domain Adaptation (GDA) transfers knowledge from labeled source graphs to unlabeled target graphs, addressing the challenge of label scarcity. In this paper, we highlight the significance of graph homophily, a pivotal factor for graph domain alignment, which, however, has long been overlooked in existing approaches. Specifically, our analysis first reveals that homophily discrepancies exist in benchmarks. Moreover, we also show that homophily discrepancies degrade GDA performance from both empirical and theoretical aspects, which further underscores the importance of homophily alignment in GDA. Inspired by this finding, we propose a novel homophily alignment algorithm that employs mixed filters to smooth graph signals, thereby effectively capturing and mitigating homophily discrepancies between graphs. Experimental results on a variety of benchmarks verify the effectiveness of our method.
ZETA: Leveraging Z-order Curves for Efficient Top-k Attention
Jan 24, 2025Over recent years, the Transformer has become a fundamental building block for sequence modeling architectures. Yet at its core is the use of self-attention, whose memory and computational cost grow quadratically with the sequence length $N$, rendering it prohibitively expensive for long sequences. A promising approach is top-$k$ attention, which selects only the $k$ most relevant tokens and achieves performance comparable to vanilla self-attention while significantly reducing space and computational demands. However, causal masks require the current query token to only attend to past tokens, preventing the existing top-$k$ attention method from efficiently searching for the most relevant tokens in parallel, thereby limiting training efficiency. In this work, we propose ZETA, leveraging \textbf{Z}-Order Curves for \textbf{E}fficient \textbf{T}op-$k$ \textbf{A}ttention, to enable parallel querying of past tokens for entire sequences. % in both space and time complexity of $\mathcal{O}(N \log N)$. We first theoretically show that the choice of key and query dimensions involves a trade-off between the curse of dimensionality and the preservation of relative distances after projection. In light of this insight, we propose reducing the dimensionality of keys and queries in contrast to values and further leverage $Z$-order curves to map low-dimensional keys and queries into \emph{one}-dimensional space, which permits parallel sorting, thereby largely improving the efficiency for top-$k$ token selection. Experimental results demonstrate that ZETA matches the performance of standard attention on the synthetic \textsc{Multi-Query Associative Recall} task and outperforms attention and its variants on \textsc{Long Range Arena} and \textsc{WikiText-103} language modeling.
Leveraging Group Classification with Descending Soft Labeling for Deep Imbalanced Regression
Dec 16, 2024



Deep imbalanced regression (DIR), where the target values have a highly skewed distribution and are also continuous, is an intriguing yet under-explored problem in machine learning. While recent works have already shown that incorporating various classification-based regularizers can produce enhanced outcomes, the role of classification remains elusive in DIR. Moreover, such regularizers (e.g., contrastive penalties) merely focus on learning discriminative features of data, which inevitably results in ignorance of either continuity or similarity across the data. To address these issues, we first bridge the connection between the objectives of DIR and classification from a Bayesian perspective. Consequently, this motivates us to decompose the objective of DIR into a combination of classification and regression tasks, which naturally guides us toward a divide-and-conquer manner to solve the DIR problem. Specifically, by aggregating the data at nearby labels into the same groups, we introduce an ordinal group-aware contrastive learning loss along with a multi-experts regressor to tackle the different groups of data thereby maintaining the data continuity. Meanwhile, considering the similarity between the groups, we also propose a symmetric descending soft labeling strategy to exploit the intrinsic similarity across the data, which allows classification to facilitate regression more effectively. Extensive experiments on real-world datasets also validate the effectiveness of our method.
Intersectional Unfairness Discovery
May 31, 2024



AI systems have been shown to produce unfair results for certain subgroups of population, highlighting the need to understand bias on certain sensitive attributes. Current research often falls short, primarily focusing on the subgroups characterized by a single sensitive attribute, while neglecting the nature of intersectional fairness of multiple sensitive attributes. This paper focuses on its one fundamental aspect by discovering diverse high-bias subgroups under intersectional sensitive attributes. Specifically, we propose a Bias-Guided Generative Network (BGGN). By treating each bias value as a reward, BGGN efficiently generates high-bias intersectional sensitive attributes. Experiments on real-world text and image datasets demonstrate a diverse and efficient discovery of BGGN. To further evaluate the generated unseen but possible unfair intersectional sensitive attributes, we formulate them as prompts and use modern generative AI to produce new texts and images. The results of frequently generating biased data provides new insights of discovering potential unfairness in popular modern generative AI systems. Warning: This paper contains generative examples that are offensive in nature.
Generalizing across Temporal Domains with Koopman Operators
Feb 15, 2024



In the field of domain generalization, the task of constructing a predictive model capable of generalizing to a target domain without access to target data remains challenging. This problem becomes further complicated when considering evolving dynamics between domains. While various approaches have been proposed to address this issue, a comprehensive understanding of the underlying generalization theory is still lacking. In this study, we contribute novel theoretic results that aligning conditional distribution leads to the reduction of generalization bounds. Our analysis serves as a key motivation for solving the Temporal Domain Generalization (TDG) problem through the application of Koopman Neural Operators, resulting in Temporal Koopman Networks (TKNets). By employing Koopman Operators, we effectively address the time-evolving distributions encountered in TDG using the principles of Koopman theory, where measurement functions are sought to establish linear transition relations between evolving domains. Through empirical evaluations conducted on synthetic and real-world datasets, we validate the effectiveness of our proposed approach.
When Source-Free Domain Adaptation Meets Learning with Noisy Labels
Jan 31, 2023



Recent state-of-the-art source-free domain adaptation (SFDA) methods have focused on learning meaningful cluster structures in the feature space, which have succeeded in adapting the knowledge from source domain to unlabeled target domain without accessing the private source data. However, existing methods rely on the pseudo-labels generated by source models that can be noisy due to domain shift. In this paper, we study SFDA from the perspective of learning with label noise (LLN). Unlike the label noise in the conventional LLN scenario, we prove that the label noise in SFDA follows a different distribution assumption. We also prove that such a difference makes existing LLN methods that rely on their distribution assumptions unable to address the label noise in SFDA. Empirical evidence suggests that only marginal improvements are achieved when applying the existing LLN methods to solve the SFDA problem. On the other hand, although there exists a fundamental difference between the label noise in the two scenarios, we demonstrate theoretically that the early-time training phenomenon (ETP), which has been previously observed in conventional label noise settings, can also be observed in the SFDA problem. Extensive experiments demonstrate significant improvements to existing SFDA algorithms by leveraging ETP to address the label noise in SFDA.
On Learning Fairness and Accuracy on Multiple Subgroups
Oct 19, 2022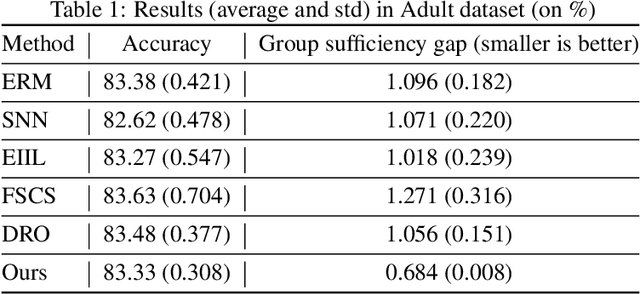
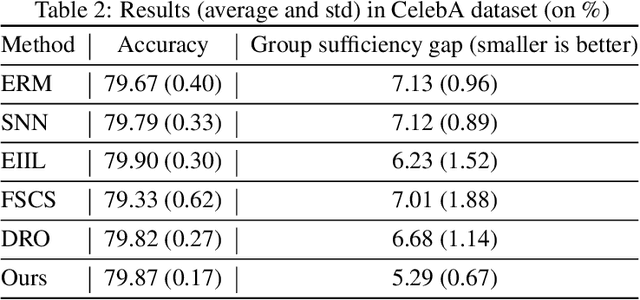
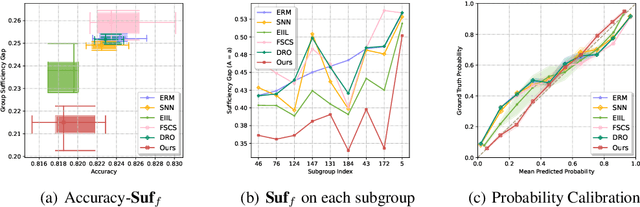
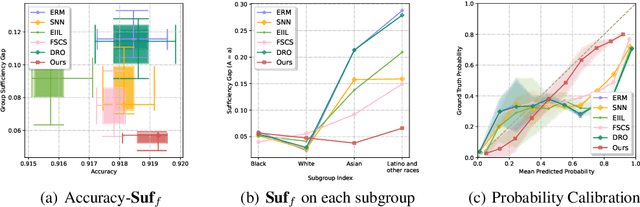
We propose an analysis in fair learning that preserves the utility of the data while reducing prediction disparities under the criteria of group sufficiency. We focus on the scenario where the data contains multiple or even many subgroups, each with limited number of samples. As a result, we present a principled method for learning a fair predictor for all subgroups via formulating it as a bilevel objective. Specifically, the subgroup specific predictors are learned in the lower-level through a small amount of data and the fair predictor. In the upper-level, the fair predictor is updated to be close to all subgroup specific predictors. We further prove that such a bilevel objective can effectively control the group sufficiency and generalization error. We evaluate the proposed framework on real-world datasets. Empirical evidence suggests the consistently improved fair predictions, as well as the comparable accuracy to the baselines.