 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual and Seasonal LSTMs for Time Series Anomaly Detection
Feb 10, 2026Univariate time series (UTS), where each timestamp records a single variable, serve as crucial indicators in web systems and cloud servers. Anomaly detection in UTS plays an essential role in both data mining and system reliability management. However, existing reconstruction-based and prediction-based methods struggle to capture certain subtle anomalies, particularly small point anomalies and slowly rising anomalies. To address these challenges, we propose a novel prediction-based framework named Contextual and Seasonal LSTMs (CS-LSTMs). CS-LSTMs are built upon a noise decomposition strategy and jointly leverage contextual dependencies and seasonal patterns, thereby strengthening the detection of subtle anomalies. By integrating both time-domain and frequency-domain representations, CS-LSTMs achieve more accurate modeling of periodic trends and anomaly localization. Extensive evaluations on public benchmark datasets demonstrate that CS-LSTMs consistently outperform state-of-the-art methods, highlighting their effectiveness and practical value in robust time series anomaly detection.
Navigating the Risks: A Survey of Security, Privacy, and Ethics Threats in LLM-Based Agents
Nov 14, 2024



With the continuous development of large language models (LLMs), transformer-based models have made groundbreaking advances in numerous natural language processing (NLP) tasks, leading to the emergence of a series of agents that use LLMs as their control hub. While LLMs have achieved success in various tasks, they face numerous security and privacy threats, which become even more severe in the agent scenarios. To enhance the reliability of LLM-based applications, a range of research has emerged to assess and mitigate these risks from different perspectives. To help researchers gain a comprehensive understanding of various risks, this survey collects and analyzes the different threats faced by these agents. To address the challenges posed by previous taxonomies in handling cross-module and cross-stage threats, we propose a novel taxonomy framework based on the sources and impacts. Additionally, we identify six key features of LLM-based agents, based on which we summarize the current research progress and analyze their limitations. Subsequently, we select four representative agents as case studies to analyze the risks they may face in practical use. Finally, based on the aforementioned analyses, we propose future research directions from the perspectives of data, methodology, and policy, respectively.
CLIBE: Detecting Dynamic Backdoors in Transformer-based NLP Models
Sep 02, 2024



Backdoors can be injected into NLP models to induce misbehavior when the input text contains a specific feature, known as a trigger, which the attacker secretly selects. Unlike fixed words, phrases, or sentences used in the static text trigger, NLP dynamic backdoor attacks design triggers associated with abstract and latent text features, making them considerably stealthier than traditional static backdoor attacks. However, existing research on NLP backdoor detection primarily focuses on defending against static backdoor attacks, while detecting dynamic backdoors in NLP models remains largely unexplored. This paper presents CLIBE, the first framework to detect dynamic backdoors in Transformer-based NLP models. CLIBE injects a "few-shot perturbation" into the suspect Transformer model by crafting optimized weight perturbation in the attention layers to make the perturbed model classify a limited number of reference samples as a target label. Subsequently, CLIBE leverages the generalization ability of this few-shot perturbation to determine whether the original model contains a dynamic backdoor. Extensive evaluation on three advanced NLP dynamic backdoor attacks, two widely-used Transformer frameworks, and four real-world classification tasks strongly validates the effectiveness of CLIBE. We also demonstrate the robustness of CLIBE against various adaptive attacks. Furthermore, we employ CLIBE to scrutinize 49 popular Transformer models on Hugging Face and discover one exhibiting a high probability of containing a dynamic backdoor. We have contacted Hugging Face and provided detailed evidence of this model's backdoor behavior. Moreover, we extend CLIBE to detect backdoor text generation models modified to exhibit toxic behavior. To the best of our knowledge, CLIBE is the first framework capable of detecting backdoors in text generation models without access to trigger input test samples.
Enhancing Automatic Modulation Recognition through Robust Global Feature Extraction
Jan 02, 2024



Automatic Modulation Recognition (AMR) plays a crucial role in wireless communication systems. Deep learning AMR strategies have achieved tremendous success in recent years. Modulated signals exhibit long temporal dependencies, and extracting global features is crucial in identifying modulation schemes. Traditionally, human experts analyze patterns in constellation diagrams to classify modulation schemes. Classical convolutional-based networks, due to their limited receptive fields, excel at extracting local features but struggle to capture global relationships. To address this limitation, we introduce a novel hybrid deep framework named TLDNN, which incorporates the architectures of the transformer and long short-term memory (LSTM). We utilize the self-attention mechanism of the transformer to model the global correlations in signal sequences while employing LSTM to enhance the capture of temporal dependencies. To mitigate the impact like RF fingerprint features and channel characteristics on model generalization, we propose data augmentation strategies known as segment substitution (SS) to enhance the model's robustness to modulation-related features. Experimental results on widely-used datasets demonstrate that our method achieves state-of-the-art performance and exhibits significant advantages in terms of complexity. Our proposed framework serves as a foundational backbone that can be extended to different datasets. We have verified the effectiveness of our augmentation approach in enhancing the generalization of the models, particularly in few-shot scenarios. Code is available at \url{https://github.com/AMR-Master/TLDNN}.
Non-volatile Reconfigurable Digital Optical Diffractive Neural Network Based on Phase Change Material
May 18, 2023



Optical diffractive neural networks have triggered extensive research with their low power consumption and high speed in image processing. In this work, we propose a reconfigurable digital all-optical diffractive neural network (R-ODNN) structure. The optical neurons are built with Sb2Se3 phase-change material, making our network reconfigurable, digital, and non-volatile. Using three digital diffractive layers with 14,400 neurons on each and 10 photodetectors connected to a resistor network, our model achieves 94.46% accuracy for handwritten digit recognition. We also performed full-vector simulations and discussed the impact of errors to demonstrate the feasibility and robustness of the R-ODNN.
Deep Learning for Hybrid Beamforming with Finite Feedback in GSM Aided mmWave MIMO Systems
Feb 15, 2023



Hybrid beamforming is widely recognized as an important technique for millimeter wave (mmWave) multiple input multiple output (MIMO) systems. Generalized spatial modulation (GSM) is further introduced to improve the spectrum efficiency. However, most of the existing works on beamforming assume the perfect channel state information (CSI), which is unrealistic in practical systems. In this paper, joint optimization of downlink pilot training, channel estimation, CSI feedback, and hybrid beamforming is considered in GSM aided frequency division duplexing (FDD) mmWave MIMO systems. With the help of deep learning, the GSM hybrid beamformers are designed via unsupervised learning in an end-to-end way. Experiments show that the proposed multi-resolution network named GsmEFBNet can reach a better achievable rate with fewer feedback bits compared with the conventional algorithm.
Towards Efficient Subarray Hybrid Beamforming: Attention Network-based Practical Feedback in FDD Massive MU-MIMO Systems
Feb 05, 2023



Channel state information (CSI) feedback is necessary for the frequency division duplexing (FDD) multiple input multiple output (MIMO) systems due to the channel non-reciprocity. With the help of deep learning, many works have succeeded in rebuilding the compressed ideal CSI for massive MIMO. However, simple CSI reconstruction is of limited practicality since the channel estimation and the targeted beamforming design are not considered. In this paper, a jointly optimized network is introduced for channel estimation and feedback so that a spectral-efficient beamformer can be learned. Moreover, the deployment-friendly subarray hybrid beamforming architecture is applied and a practical lightweight end-to-end network is specially designed. Experiments show that the proposed network is over 10 times lighter at the resource-sensitive user equipment compared with the previous state-of-the-art method with only a minor performance loss.
Quantization Adaptor for Bit-Level Deep Learning-Based Massive MIMO CSI Feedback
Nov 09, 2022



In massive multiple-input multiple-output (MIMO) systems, the user equipment (UE) needs to feed the channel state information (CSI) back to the base station (BS) for the following beamforming. But the large scale of antennas in massive MIMO systems causes huge feedback overhead. Deep learning (DL) based methods can compress the CSI at the UE and recover it at the BS, which reduces the feedback cost significantly. But the compressed CSI must be quantized into bit streams for transmission. In this paper, we propose an adaptor-assisted quantization strategy for bit-level DL-based CSI feedback. First, we design a network-aided adaptor and an advanced training scheme to adaptively improve the quantization and reconstruction accuracy. Moreover, for easy practical employment, we introduce the expert knowledge of data distribution and propose a pluggable and cost-free adaptor scheme. Experiments show that compared with the state-of-the-art feedback quantization method, this adaptor-aided quantization strategy can achieve better quantization accuracy and reconstruction performance with less or no additional cost. The open-source codes are available at https://github.com/zhang-xd18/QCRNet.
Better Lightweight Network for Free: Codeword Mimic Learning for Massive MIMO CSI feedback
Oct 29, 2022The channel state information (CSI) needs to be fed back from the user equipment (UE) to the base station (BS) in frequency division duplexing (FDD) multiple-input multiple-output (MIMO) system. Recently, neural networks are widely applied to CSI compressed feedback since the original overhead is too large for the massive MIMO system. Notably, lightweight feedback networks attract special attention due to their practicality of deployment. However, the feedback accuracy is likely to be harmed by the network compression. In this paper, a cost free distillation technique named codeword mimic (CM) is proposed to train better feedback networks with the practical lightweight encoder. A mimic-explore training strategy with a special distillation scheduler is designed to enhance the CM learning. Experiments show that the proposed CM learning outperforms the previous state-of-the-art feedback distillation method, boosting the performance of the lightweight feedback network without any extra inference cost.
Deep Feature Mining via Attention-based BiLSTM-GCN for Human Motor Imagery Recognition
May 02, 2020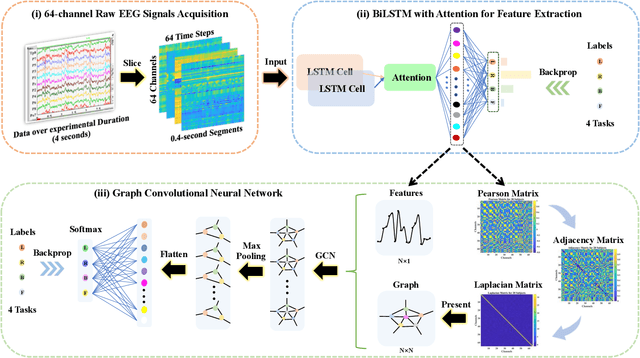
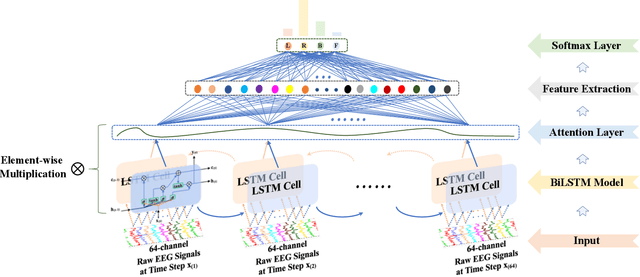
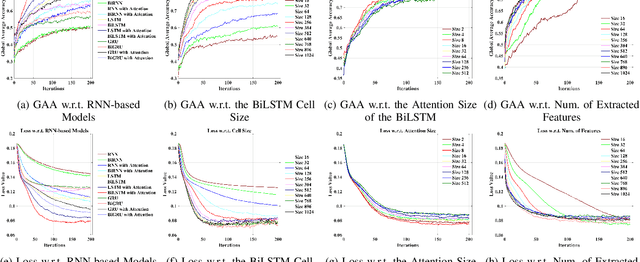
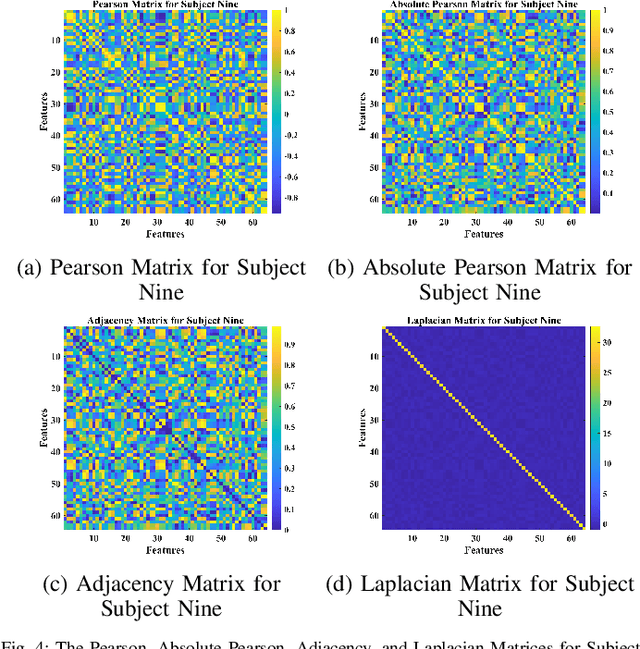
Recognition accuracy and response time are both critically essential ahead of building practical electroencephalography (EEG) based brain-computer interface (BCI). Recent approaches, however, have either compromised in the classification accuracy or responding time. This paper presents a novel deep learning approach designed towards remarkably accurate and responsive motor imagery (MI) recognition based on scalp EEG. Bidirectional Long Short-term Memory (BiLSTM) with the Attention mechanism manages to derive relevant features from raw EEG signals. The connected graph convolutional neural network (GCN) promotes the decoding performance by cooperating with the topological structure of features, which are estimated from the overall data. The 0.4-second detection framework has shown effective and efficient prediction based on individual and group-wise training, with 98.81% and 94.64% accuracy, respectively, which outperformed all the state-of-the-art studies. The introduced deep feature mining approach can precisely recognize human motion intents from raw EEG signals, which paves the road to translate the EEG based MI recognition to practical BCI systems.