 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUEPS: Robust and Efficient MRI Reconstruction
Mar 19, 2026Deep unrolled models (DUMs) have become the state of the art for accelerated MRI reconstruction, yet their robustness under domain shift remains a critical barrier to clinical adoption. In this work, we identify coil sensitivity map (CSM) estimation as the primary bottleneck limiting generalization. To address this, we propose UEPS, a novel DUM architecture featuring three key innovations: (i) an Unrolled Expanded (UE) design that eliminates CSM dependency by reconstructing each coil independently; (ii) progressive resolution, which leverages k-space-to-image mapping for efficient coarse-to-fine refinement; and (iii) sparse attention tailored to MRI's 1D undersampling nature. These physics-grounded designs enable simultaneous gains in robustness and computational efficiency. We construct a large-scale zero-shot transfer benchmark comprising 10 out-of-distribution test sets spanning diverse clinical shifts -- anatomy, view, contrast, vendor, field strength, and coil configurations. Extensive experiments demonstrate that UEPS consistently and substantially outperforms existing DUM, end-to-end, diffusion, and untrained methods across all OOD tests, achieving state-of-the-art robustness with low-latency inference suitable for real-time deployment.
ASM: Adaptive Skinning Model for High-Quality 3D Face Modeling
Apr 19, 2023The research fields of parametric face models and 3D face reconstruction have been extensively studied. However, a critical question remains unanswered: how to tailor the face model for specific reconstruction settings. We argue that reconstruction with multi-view uncalibrated images demands a new model with stronger capacity. Our study shifts attention from data-dependent 3D Morphable Models (3DMM) to an understudied human-designed skinning model. We propose Adaptive Skinning Model (ASM), which redefines the skinning model with more compact and fully tunable parameters. With extensive experiments, we demonstrate that ASM achieves significantly improved capacity than 3DMM, with the additional advantage of model size and easy implementation for new topology. We achieve state-of-the-art performance with ASM for multi-view reconstruction on the Florence MICC Coop benchmark. Our quantitative analysis demonstrates the importance of a high-capacity model for fully exploiting abundant information from multi-view input in reconstruction. Furthermore, our model with physical-semantic parameters can be directly utilized for real-world applications, such as in-game avatar creation. As a result, our work opens up new research directions for the parametric face models and facilitates future research on multi-view reconstruction.
Weakly Supervised Learning with Side Information for Noisy Labeled Images
Sep 04, 2020
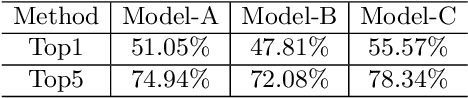
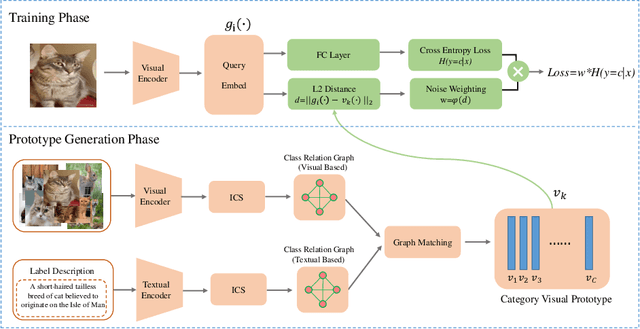

In many real-world datasets, like WebVision, the performance of DNN based classifier is often limited by the noisy labeled data. To tackle this problem, some image related side information, such as captions and tags, often reveal underlying relationships across images. In this paper, we present an efficient weakly supervised learning by using a Side Information Network (SINet), which aims to effectively carry out a large scale classification with severely noisy labels. The proposed SINet consists of a visual prototype module and a noise weighting module. The visual prototype module is designed to generate a compact representation for each category by introducing the side information. The noise weighting module aims to estimate the correctness of each noisy image and produce a confidence score for image ranking during the training procedure. The propsed SINet can largely alleviate the negative impact of noisy image labels, and is beneficial to train a high performance CNN based classifier. Besides, we released a fine-grained product dataset called AliProducts, which contains more than 2.5 million noisy web images crawled from the internet by using queries generated from 50,000 fine-grained semantic classes. Extensive experiments on several popular benchmarks (i.e. Webvision, ImageNet and Clothing-1M) and our proposed AliProducts achieve state-of-the-art performance. The SINet has won the first place in the classification task on WebVision Challenge 2019, and outperformed other competitors by a large margin.