 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Contrastive Learning by Visualizing Feature Transformation
Aug 06, 2021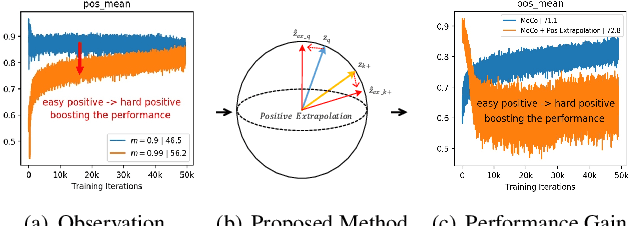

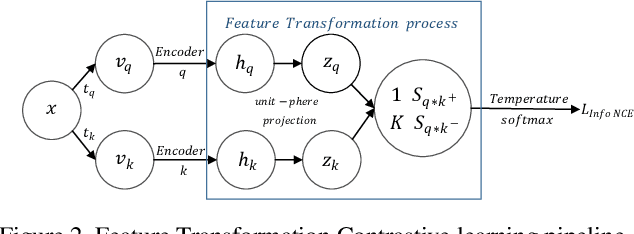

Contrastive learning, which aims at minimizing the distance between positive pairs while maximizing that of negative ones, has been widely and successfully applied in unsupervised feature learning, where the design of positive and negative (pos/neg) pairs is one of its keys. In this paper, we attempt to devise a feature-level data manipulation, differing from data augmentation, to enhance the generic contrastive self-supervised learning. To this end, we first design a visualization scheme for pos/neg score (Pos/neg score indicates cosine similarity of pos/neg pair.) distribution, which enables us to analyze, interpret and understand the learning process. To our knowledge, this is the first attempt of its kind. More importantly, leveraging this tool, we gain some significant observations, which inspire our novel Feature Transformation proposals including the extrapolation of positives. This operation creates harder positives to boost the learning because hard positives enable the model to be more view-invariant. Besides, we propose the interpolation among negatives, which provides diversified negatives and makes the model more discriminative. It is the first attempt to deal with both challenges simultaneously. Experiment results show that our proposed Feature Transformation can improve at least 6.0% accuracy on ImageNet-100 over MoCo baseline, and about 2.0% accuracy on ImageNet-1K over the MoCoV2 baseline. Transferring to the downstream tasks successfully demonstrate our model is less task-bias. Visualization tools and codes https://github.com/DTennant/CL-Visualizing-Feature-Transformation .
Toward Accurate and Realistic Outfits Visualization with Attention to Details
Jun 11, 2021
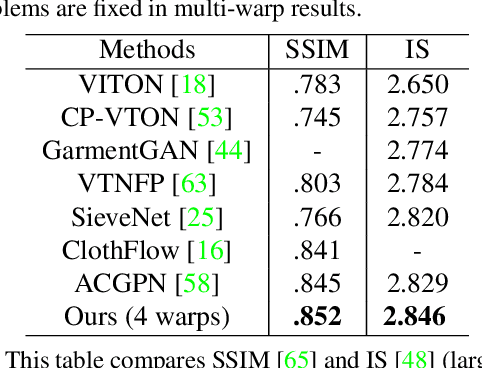


Virtual try-on methods aim to generate images of fashion models wearing arbitrary combinations of garments. This is a challenging task because the generated image must appear realistic and accurately display the interaction between garments. Prior works produce images that are filled with artifacts and fail to capture important visual details necessary for commercial applications. We propose Outfit Visualization Net (OVNet) to capture these important details (e.g. buttons, shading, textures, realistic hemlines, and interactions between garments) and produce high quality multiple-garment virtual try-on images. OVNet consists of 1) a semantic layout generator and 2) an image generation pipeline using multiple coordinated warps. We train the warper to output multiple warps using a cascade loss, which refines each successive warp to focus on poorly generated regions of a previous warp and yields consistent improvements in detail. In addition, we introduce a method for matching outfits with the most suitable model and produce significant improvements for both our and other previous try-on methods. Through quantitative and qualitative analysis, we demonstrate our method generates substantially higher-quality studio images compared to prior works for multi-garment outfits. An interactive interface powered by this method has been deployed on fashion e-commerce websites and received overwhelmingly positive feedback.
Action Unit Memory Network for Weakly Supervised Temporal Action Localization
Apr 29, 2021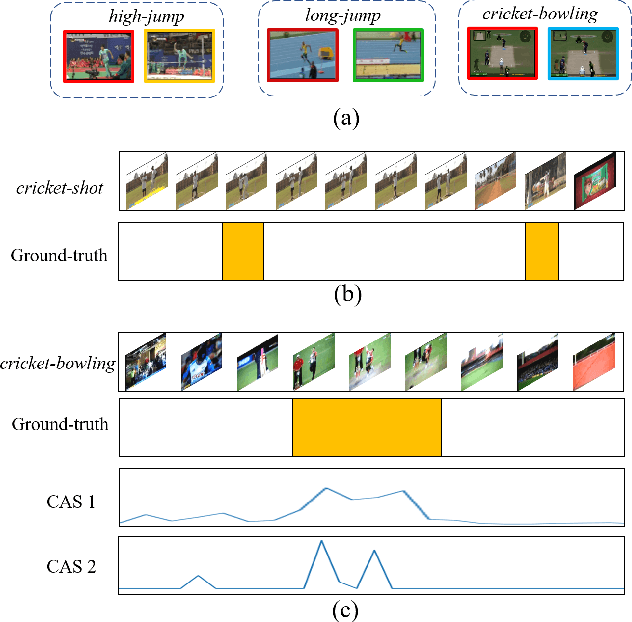
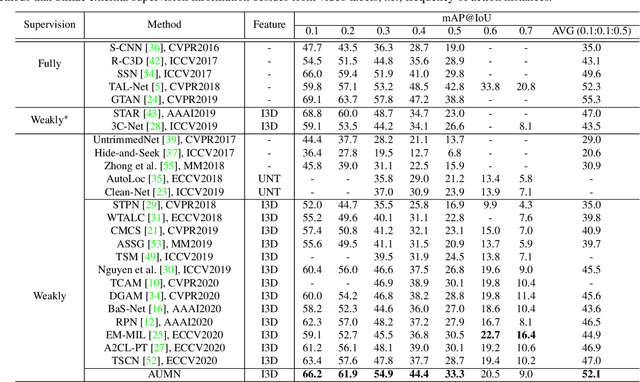
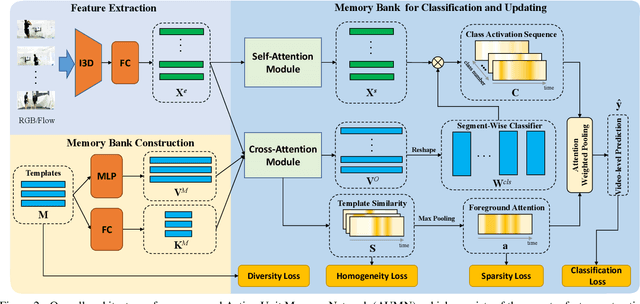
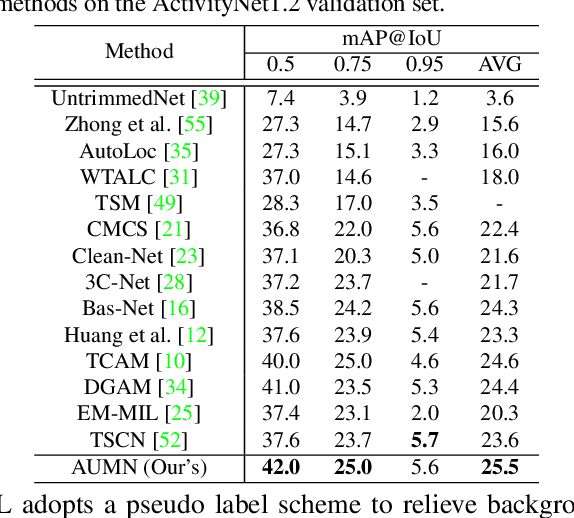
Weakly supervised temporal action localization aims to detect and localize actions in untrimmed videos with only video-level labels during training. However, without frame-level annotations, it is challenging to achieve localization completeness and relieve background interference. In this paper, we present an Action Unit Memory Network (AUMN) for weakly supervised temporal action localization, which can mitigate the above two challenges by learning an action unit memory bank. In the proposed AUMN, two attention modules are designed to update the memory bank adaptively and learn action units specific classifiers. Furthermore, three effective mechanisms (diversity, homogeneity and sparsity) are designed to guide the updating of the memory network. To the best of our knowledge, this is the first work to explicitly model the action units with a memory network. Extensive experimental results on two standard benchmarks (THUMOS14 and ActivityNet) demonstrate that our AUMN performs favorably against state-of-the-art methods. Specifically, the average mAP of IoU thresholds from 0.1 to 0.5 on the THUMOS14 dataset is significantly improved from 47.0% to 52.1%.
Learning a Unified Sample Weighting Network for Object Detection
Jun 14, 2020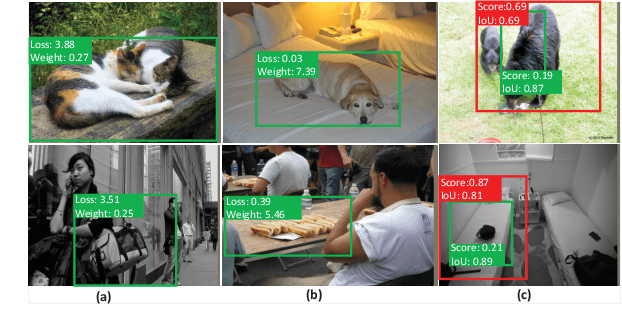

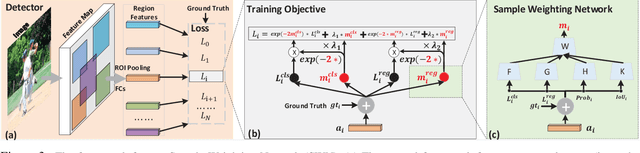
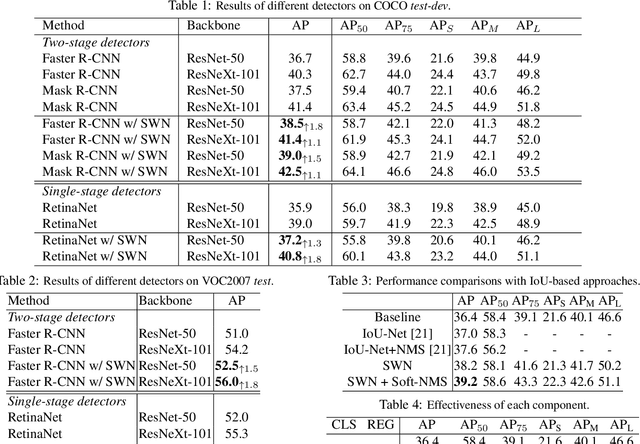
Region sampling or weighting is significantly important to the success of modern region-based object detectors. Unlike some previous works, which only focus on "hard" samples when optimizing the objective function, we argue that sample weighting should be data-dependent and task-dependent. The importance of a sample for the objective function optimization is determined by its uncertainties to both object classification and bounding box regression tasks. To this end, we devise a general loss function to cover most region-based object detectors with various sampling strategies, and then based on it we propose a unified sample weighting network to predict a sample's task weights. Our framework is simple yet effective. It leverages the samples' uncertainty distributions on classification loss, regression loss, IoU, and probability score, to predict sample weights. Our approach has several advantages: (i). It jointly learns sample weights for both classification and regression tasks, which differentiates it from most previous work. (ii). It is a data-driven process, so it avoids some manual parameter tuning. (iii). It can be effortlessly plugged into most object detectors and achieves noticeable performance improvements without affecting their inference time. Our approach has been thoroughly evaluated with recent object detection frameworks and it can consistently boost the detection accuracy. Code has been made available at \url{https://github.com/caiqi/sample-weighting-network}.
Robust Visual Object Tracking with Two-Stream Residual Convolutional Networks
May 13, 2020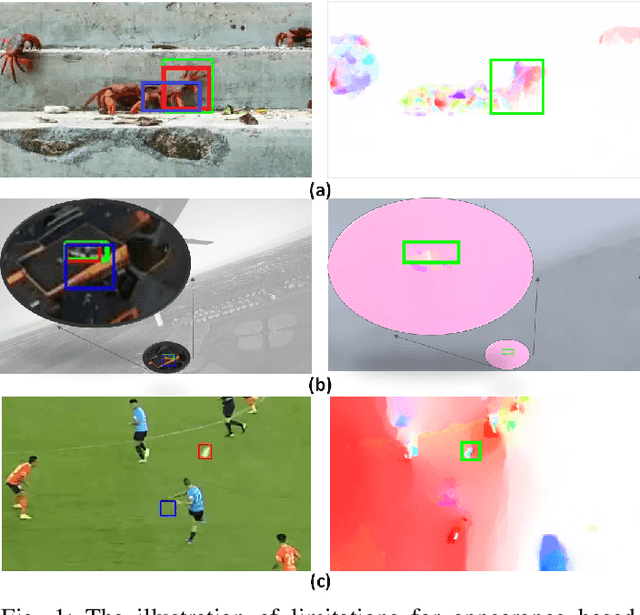
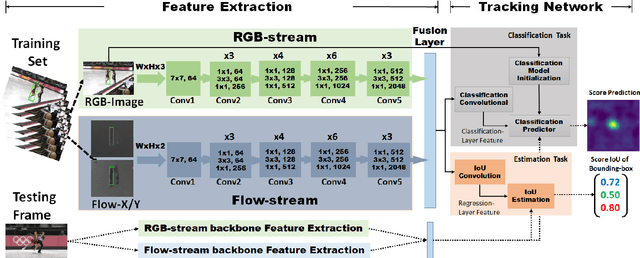

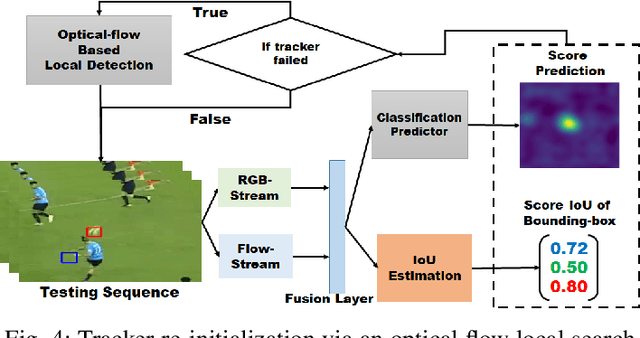
The current deep learning based visual tracking approaches have been very successful by learning the target classification and/or estimation model from a large amount of supervised training data in offline mode. However, most of them can still fail in tracking objects due to some more challenging issues such as dense distractor objects, confusing background, motion blurs, and so on. Inspired by the human "visual tracking" capability which leverages motion cues to distinguish the target from the background, we propose a Two-Stream Residual Convolutional Network (TS-RCN) for visual tracking, which successfully exploits both appearance and motion features for model update. Our TS-RCN can be integrated with existing deep learning based visual trackers. To further improve the tracking performance, we adopt a "wider" residual network ResNeXt as its feature extraction backbone. To the best of our knowledge, TS-RCN is the first end-to-end trainable two-stream visual tracking system, which makes full use of both appearance and motion features of the target. We have extensively evaluated the TS-RCN on most widely used benchmark datasets including VOT2018, VOT2019, and GOT-10K. The experiment results have successfully demonstrated that our two-stream model can greatly outperform the appearance based tracker, and it also achieves state-of-the-art performance. The tracking system can run at up to 38.1 FPS.
Toward Accurate and Realistic Virtual Try-on Through Shape Matching and Multiple Warps
Mar 27, 2020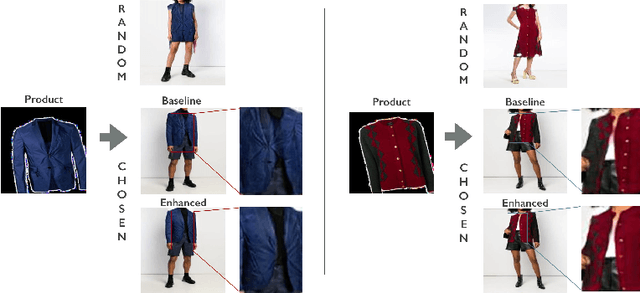
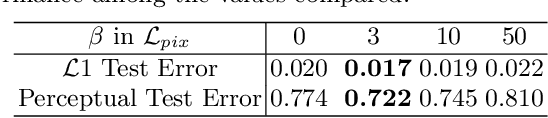
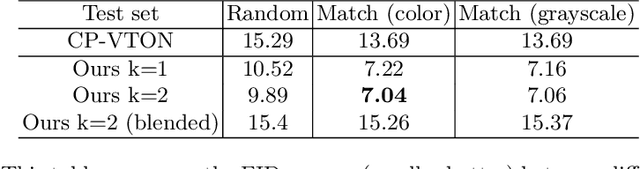
A virtual try-on method takes a product image and an image of a model and produces an image of the model wearing the product. Most methods essentially compute warps from the product image to the model image and combine using image generation methods. However, obtaining a realistic image is challenging because the kinematics of garments is complex and because outline, texture, and shading cues in the image reveal errors to human viewers. The garment must have appropriate drapes; texture must be warped to be consistent with the shape of a draped garment; small details (buttons, collars, lapels, pockets, etc.) must be placed appropriately on the garment, and so on. Evaluation is particularly difficult and is usually qualitative. This paper uses quantitative evaluation on a challenging, novel dataset to demonstrate that (a) for any warping method, one can choose target models automatically to improve results, and (b) learning multiple coordinated specialized warpers offers further improvements on results. Target models are chosen by a learned embedding procedure that predicts a representation of the products the model is wearing. This prediction is used to match products to models. Specialized warpers are trained by a method that encourages a second warper to perform well in locations where the first works poorly. The warps are then combined using a U-Net. Qualitative evaluation confirms that these improvements are wholesale over outline, texture shading, and garment details.
Theme-Matters: Fashion Compatibility Learning via Theme Attention
Dec 26, 2019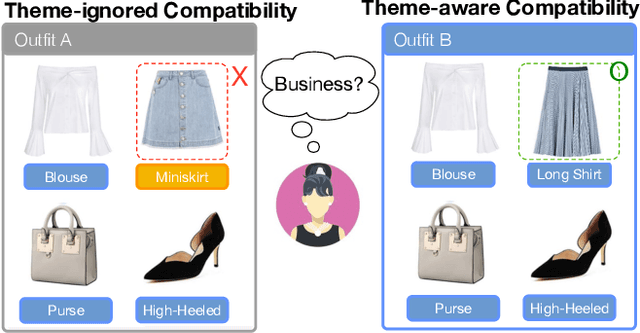
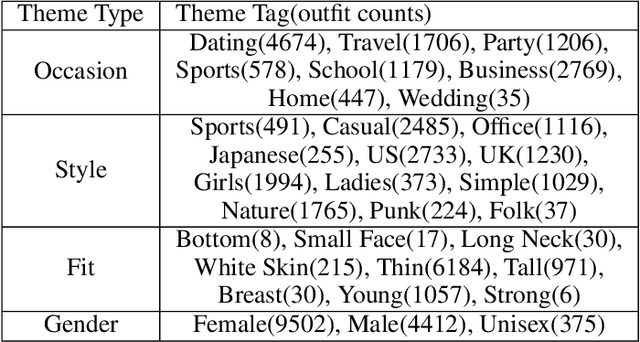
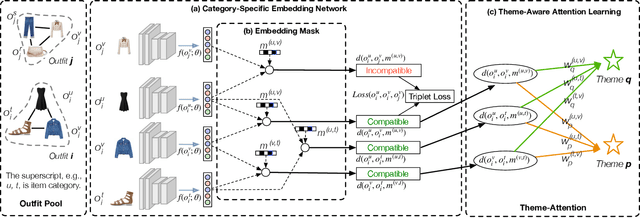
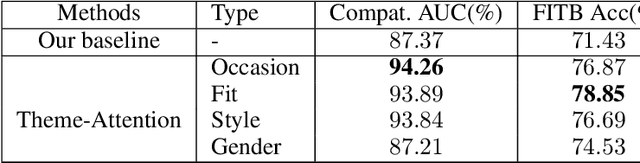
Fashion compatibility learning is important to many fashion markets such as outfit composition and online fashion recommendation. Unlike previous work, we argue that fashion compatibility is not only a visual appearance compatible problem but also a theme-matters problem. An outfit, which consists of a set of fashion items (e.g., shirt, suit, shoes, etc.), is considered to be compatible for a "dating" event, yet maybe not for a "business" occasion. In this paper, we aim at solving the fashion compatibility problem given specific themes. To this end, we built the first real-world theme-aware fashion dataset comprising 14K around outfits labeled with 32 themes. In this dataset, there are more than 40K fashion items labeled with 152 fine-grained categories. We also propose an attention model learning fashion compatibility given a specific theme. It starts with a category-specific subspace learning, which projects compatible outfit items in certain categories to be close in the subspace. Thanks to strong connections between fashion themes and categories, we then build a theme-attention model over the category-specific embedding space. This model associates themes with the pairwise compatibility with attention, and thus compute the outfit-wise compatibility. To the best of our knowledge, this is the first attempt to estimate outfit compatibility conditional on a theme. We conduct extensive qualitative and quantitative experiments on our new dataset. Our method outperforms the state-of-the-art approaches.
Customizable Architecture Search for Semantic Segmentation
Aug 26, 2019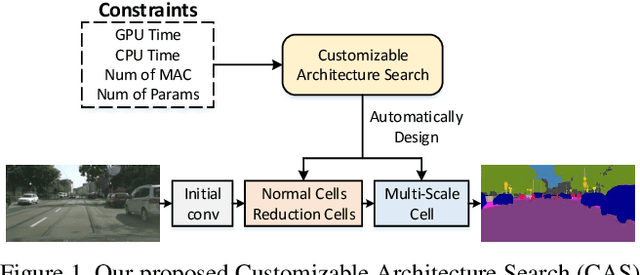
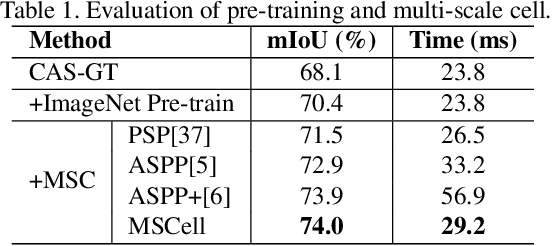
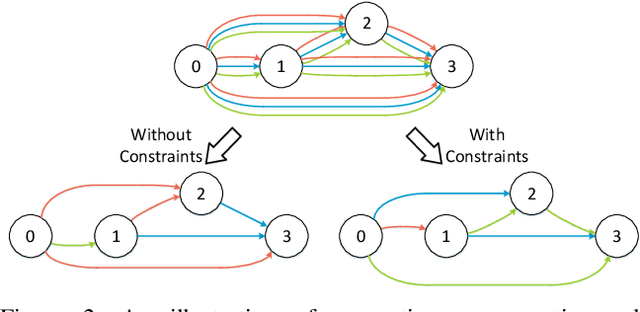
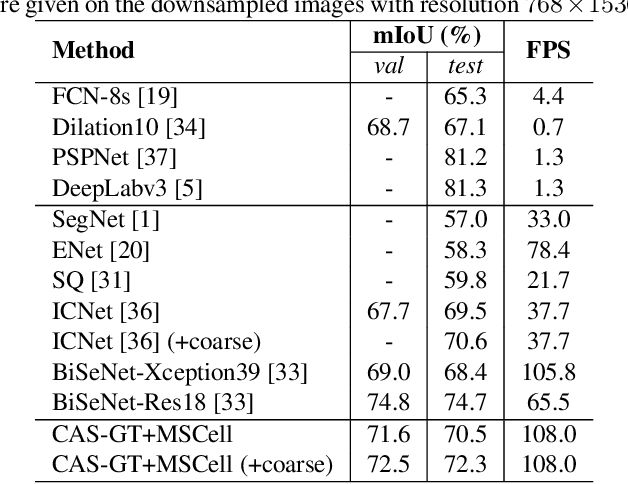
In this paper, we propose a Customizable Architecture Search (CAS) approach to automatically generate a network architecture for semantic image segmentation. The generated network consists of a sequence of stacked computation cells. A computation cell is represented as a directed acyclic graph, in which each node is a hidden representation (i.e., feature map) and each edge is associated with an operation (e.g., convolution and pooling), which transforms data to a new layer. During the training, the CAS algorithm explores the search space for an optimized computation cell to build a network. The cells of the same type share one architecture but with different weights. In real applications, however, an optimization may need to be conducted under some constraints such as GPU time and model size. To this end, a cost corresponding to the constraint will be assigned to each operation. When an operation is selected during the search, its associated cost will be added to the objective. As a result, our CAS is able to search an optimized architecture with customized constraints. The approach has been thoroughly evaluated on Cityscapes and CamVid datasets, and demonstrates superior performance over several state-of-the-art techniques. More remarkably, our CAS achieves 72.3% mIoU on the Cityscapes dataset with speed of 108 FPS on an Nvidia TitanXp GPU.
Zero-Shot Event Detection by Multimodal Distributional Semantic Embedding of Videos
Dec 16, 2015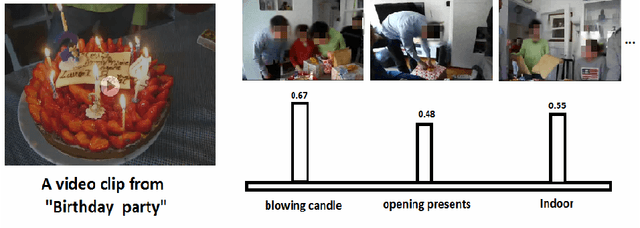

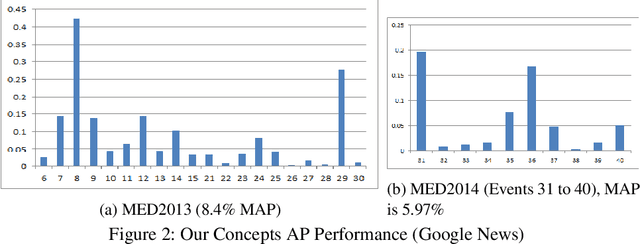

We propose a new zero-shot Event Detection method by Multi-modal Distributional Semantic embedding of videos. Our model embeds object and action concepts as well as other available modalities from videos into a distributional semantic space. To our knowledge, this is the first Zero-Shot event detection model that is built on top of distributional semantics and extends it in the following directions: (a) semantic embedding of multimodal information in videos (with focus on the visual modalities), (b) automatically determining relevance of concepts/attributes to a free text query, which could be useful for other applications, and (c) retrieving videos by free text event query (e.g., "changing a vehicle tire") based on their content. We embed videos into a distributional semantic space and then measure the similarity between videos and the event query in a free text form. We validated our method on the large TRECVID MED (Multimedia Event Detection) challenge. Using only the event title as a query, our method outperformed the state-of-the-art that uses big descriptions from 12.6% to 13.5% with MAP metric and 0.73 to 0.83 with ROC-AUC metric. It is also an order of magnitude faster.