 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeWork-R1: Coevolving Safety and Intelligence under the AI-45$^{\circ}$ Law
Jul 24, 2025



We introduce SafeWork-R1, a cutting-edge multimodal reasoning model that demonstrates the coevolution of capabilities and safety. It is developed by our proposed SafeLadder framework, which incorporates large-scale, progressive, safety-oriented reinforcement learning post-training, supported by a suite of multi-principled verifiers. Unlike previous alignment methods such as RLHF that simply learn human preferences, SafeLadder enables SafeWork-R1 to develop intrinsic safety reasoning and self-reflection abilities, giving rise to safety `aha' moments. Notably, SafeWork-R1 achieves an average improvement of $46.54\%$ over its base model Qwen2.5-VL-72B on safety-related benchmarks without compromising general capabilities, and delivers state-of-the-art safety performance compared to leading proprietary models such as GPT-4.1 and Claude Opus 4. To further bolster its reliability, we implement two distinct inference-time intervention methods and a deliberative search mechanism, enforcing step-level verification. Finally, we further develop SafeWork-R1-InternVL3-78B, SafeWork-R1-DeepSeek-70B, and SafeWork-R1-Qwen2.5VL-7B. All resulting models demonstrate that safety and capability can co-evolve synergistically, highlighting the generalizability of our framework in building robust, reliable, and trustworthy general-purpose AI.
Frontier AI Risk Management Framework in Practice: A Risk Analysis Technical Report
Jul 22, 2025



To understand and identify the unprecedented risks posed by rapidly advancing artificial intelligence (AI) models, this report presents a comprehensive assessment of their frontier risks. Drawing on the E-T-C analysis (deployment environment, threat source, enabling capability) from the Frontier AI Risk Management Framework (v1.0) (SafeWork-F1-Framework), we identify critical risks in seven areas: cyber offense, biological and chemical risks, persuasion and manipulation, uncontrolled autonomous AI R\&D, strategic deception and scheming, self-replication, and collusion. Guided by the "AI-$45^\circ$ Law," we evaluate these risks using "red lines" (intolerable thresholds) and "yellow lines" (early warning indicators) to define risk zones: green (manageable risk for routine deployment and continuous monitoring), yellow (requiring strengthened mitigations and controlled deployment), and red (necessitating suspension of development and/or deployment). Experimental results show that all recent frontier AI models reside in green and yellow zones, without crossing red lines. Specifically, no evaluated models cross the yellow line for cyber offense or uncontrolled AI R\&D risks. For self-replication, and strategic deception and scheming, most models remain in the green zone, except for certain reasoning models in the yellow zone. In persuasion and manipulation, most models are in the yellow zone due to their effective influence on humans. For biological and chemical risks, we are unable to rule out the possibility of most models residing in the yellow zone, although detailed threat modeling and in-depth assessment are required to make further claims. This work reflects our current understanding of AI frontier risks and urges collective action to mitigate these challenges.
Visual Contextual Attack: Jailbreaking MLLMs with Image-Driven Context Injection
Jul 03, 2025With the emergence of strong visual-language capabilities, multimodal large language models (MLLMs) have demonstrated tremendous potential for real-world applications. However, the security vulnerabilities exhibited by the visual modality pose significant challenges to deploying such models in open-world environments. Recent studies have successfully induced harmful responses from target MLLMs by encoding harmful textual semantics directly into visual inputs. However, in these approaches, the visual modality primarily serves as a trigger for unsafe behavior, often exhibiting semantic ambiguity and lacking grounding in realistic scenarios. In this work, we define a novel setting: visual-centric jailbreak, where visual information serves as a necessary component in constructing a complete and realistic jailbreak context. Building on this setting, we propose the VisCo (Visual Contextual) Attack. VisCo fabricates contextual dialogue using four distinct visual-focused strategies, dynamically generating auxiliary images when necessary to construct a visual-centric jailbreak scenario. To maximize attack effectiveness, it incorporates automatic toxicity obfuscation and semantic refinement to produce a final attack prompt that reliably triggers harmful responses from the target black-box MLLMs. Specifically, VisCo achieves a toxicity score of 4.78 and an Attack Success Rate (ASR) of 85% on MM-SafetyBench against GPT-4o, significantly outperforming the baseline, which performs a toxicity score of 2.48 and an ASR of 22.2%. The code is available at https://github.com/Dtc7w3PQ/Visco-Attack.
A Comprehensive Evaluation of Multi-Modal Large Language Models for Endoscopy Analysis
May 29, 2025
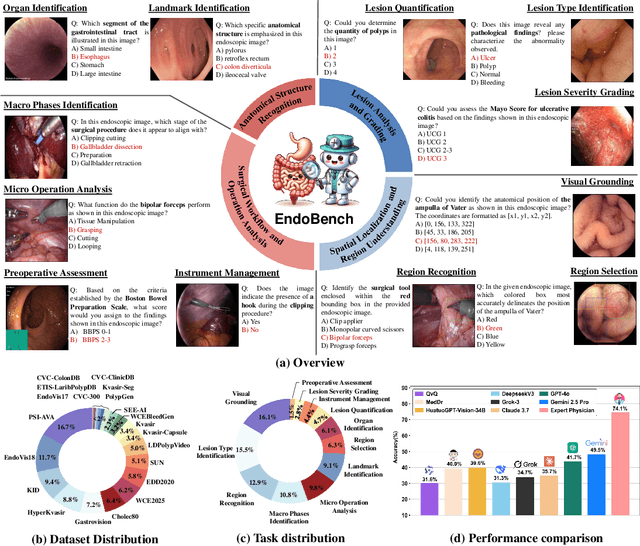


Endoscopic procedures are essential for diagnosing and treating internal diseases, and multi-modal large language models (MLLMs) are increasingly applied to assist in endoscopy analysis. However, current benchmarks are limited, as they typically cover specific endoscopic scenarios and a small set of clinical tasks, failing to capture the real-world diversity of endoscopic scenarios and the full range of skills needed in clinical workflows. To address these issues, we introduce EndoBench, the first comprehensive benchmark specifically designed to assess MLLMs across the full spectrum of endoscopic practice with multi-dimensional capacities. EndoBench encompasses 4 distinct endoscopic scenarios, 12 specialized clinical tasks with 12 secondary subtasks, and 5 levels of visual prompting granularities, resulting in 6,832 rigorously validated VQA pairs from 21 diverse datasets. Our multi-dimensional evaluation framework mirrors the clinical workflow--spanning anatomical recognition, lesion analysis, spatial localization, and surgical operations--to holistically gauge the perceptual and diagnostic abilities of MLLMs in realistic scenarios. We benchmark 23 state-of-the-art models, including general-purpose, medical-specialized, and proprietary MLLMs, and establish human clinician performance as a reference standard. Our extensive experiments reveal: (1) proprietary MLLMs outperform open-source and medical-specialized models overall, but still trail human experts; (2) medical-domain supervised fine-tuning substantially boosts task-specific accuracy; and (3) model performance remains sensitive to prompt format and clinical task complexity. EndoBench establishes a new standard for evaluating and advancing MLLMs in endoscopy, highlighting both progress and persistent gaps between current models and expert clinical reasoning. We publicly release our benchmark and code.
A Survey of Efficient Reasoning for Large Reasoning Models: Language, Multimodality, and Beyond
Mar 27, 2025Recent Large Reasoning Models (LRMs), such as DeepSeek-R1 and OpenAI o1, have demonstrated strong performance gains by scaling up the length of Chain-of-Thought (CoT) reasoning during inference. However, a growing concern lies in their tendency to produce excessively long reasoning traces, which are often filled with redundant content (e.g., repeated definitions), over-analysis of simple problems, and superficial exploration of multiple reasoning paths for harder tasks. This inefficiency introduces significant challenges for training, inference, and real-world deployment (e.g., in agent-based systems), where token economy is critical. In this survey, we provide a comprehensive overview of recent efforts aimed at improving reasoning efficiency in LRMs, with a particular focus on the unique challenges that arise in this new paradigm. We identify common patterns of inefficiency, examine methods proposed across the LRM lifecycle, i.e., from pretraining to inference, and discuss promising future directions for research. To support ongoing development, we also maintain a real-time GitHub repository tracking recent progress in the field. We hope this survey serves as a foundation for further exploration and inspires innovation in this rapidly evolving area.
MAS-GPT: Training LLMs to Build LLM-based Multi-Agent Systems
Mar 05, 2025



LLM-based multi-agent systems (MAS) have shown significant potential in tackling diverse tasks. However, to design effective MAS, existing approaches heavily rely on manual configurations or multiple calls of advanced LLMs, resulting in inadaptability and high inference costs. In this paper, we simplify the process of building an MAS by reframing it as a generative language task, where the input is a user query and the output is a corresponding MAS. To address this novel task, we unify the representation of MAS as executable code and propose a consistency-oriented data construction pipeline to create a high-quality dataset comprising coherent and consistent query-MAS pairs. Using this dataset, we train MAS-GPT, an open-source medium-sized LLM that is capable of generating query-adaptive MAS within a single LLM inference. The generated MAS can be seamlessly applied to process user queries and deliver high-quality responses. Extensive experiments on 9 benchmarks and 5 LLMs show that the proposed MAS-GPT consistently outperforms 10+ baseline MAS methods on diverse settings, indicating MAS-GPT's high effectiveness, efficiency and strong generalization ability. Code will be available at https://github.com/rui-ye/MAS-GPT.
Iterative Value Function Optimization for Guided Decoding
Mar 05, 2025While Reinforcement Learning from Human Feedback (RLHF) has become the predominant method for controlling language model outputs, it suffers from high computational costs and training instability. Guided decoding, especially value-guided methods, offers a cost-effective alternative by controlling outputs without re-training models. However, the accuracy of the value function is crucial for value-guided decoding, as inaccuracies can lead to suboptimal decision-making and degraded performance. Existing methods struggle with accurately estimating the optimal value function, leading to less effective control. We propose Iterative Value Function Optimization, a novel framework that addresses these limitations through two key components: Monte Carlo Value Estimation, which reduces estimation variance by exploring diverse trajectories, and Iterative On-Policy Optimization, which progressively improves value estimation through collecting trajectories from value-guided policies. Extensive experiments on text summarization, multi-turn dialogue, and instruction following demonstrate the effectiveness of value-guided decoding approaches in aligning language models. These approaches not only achieve alignment but also significantly reduce computational costs by leveraging principled value function optimization for efficient and effective control.
LED-Merging: Mitigating Safety-Utility Conflicts in Model Merging with Location-Election-Disjoint
Feb 24, 2025Fine-tuning pre-trained Large Language Models (LLMs) for specialized tasks incurs substantial computational and data costs. While model merging offers a training-free solution to integrate multiple task-specific models, existing methods suffer from safety-utility conflicts where enhanced general capabilities degrade safety safeguards. We identify two root causes: \textbf{neuron misidentification} due to simplistic parameter magnitude-based selection, and \textbf{cross-task neuron interference} during merging. To address these challenges, we propose \textbf{LED-Merging}, a three-stage framework that \textbf{L}ocates task-specific neurons via gradient-based attribution, dynamically \textbf{E}lects critical neurons through multi-model importance fusion, and \textbf{D}isjoints conflicting updates through parameter isolation. Extensive experiments on Llama-3-8B, Mistral-7B, and Llama2-13B demonstrate that LED-Merging reduces harmful response rates(\emph{e.g.}, a 31.4\% decrease on Llama-3-8B-Instruct on HarmBench) while preserving 95\% of utility performance(\emph{e.g.}, 52.39\% accuracy on GSM8K). LED-Merging resolves safety-utility conflicts and provides a lightweight, training-free paradigm for constructing reliable multi-task LLMs.
SEER: Self-Explainability Enhancement of Large Language Models' Representations
Feb 07, 2025Explaining the hidden representations of Large Language Models (LLMs) is a perspective to understand LLMs' underlying inference logic and improve their reliability in application scenarios. However, previous methods introduce external ''black-box'' modules to explain ''black-box'' LLMs, increasing the potential uncertainty and failing to provide faithful explanations. In this paper, we propose a self-explaining method SEER, enhancing LLMs' explainability by aggregating the same concept and disentangling the different concepts in the representation space. In this way, SEER provides faithful explanations carried by representations synchronously with the LLMs' output. Additionally, we showcase the applications of SEER on trustworthiness-related tasks (e.g., the safety risks classification and detoxification tasks), where self-explained LLMs achieve consistent improvement in explainability and performance. More crucially, we theoretically analyze the improvement of SEER on LLMs' generalization ability through optimal transport theory.
Rethinking Bottlenecks in Safety Fine-Tuning of Vision Language Models
Jan 30, 2025Large Vision-Language Models (VLMs) have achieved remarkable performance across a wide range of tasks. However, their deployment in safety-critical domains poses significant challenges. Existing safety fine-tuning methods, which focus on textual or multimodal content, fall short in addressing challenging cases or disrupt the balance between helpfulness and harmlessness. Our evaluation highlights a safety reasoning gap: these methods lack safety visual reasoning ability, leading to such bottlenecks. To address this limitation and enhance both visual perception and reasoning in safety-critical contexts, we propose a novel dataset that integrates multi-image inputs with safety Chain-of-Thought (CoT) labels as fine-grained reasoning logic to improve model performance. Specifically, we introduce the Multi-Image Safety (MIS) dataset, an instruction-following dataset tailored for multi-image safety scenarios, consisting of training and test splits. Our experiments demonstrate that fine-tuning InternVL2.5-8B with MIS significantly outperforms both powerful open-source models and API-based models in challenging multi-image tasks requiring safety-related visual reasoning. This approach not only delivers exceptional safety performance but also preserves general capabilities without any trade-offs. Specifically, fine-tuning with MIS increases average accuracy by 0.83% across five general benchmarks and reduces the Attack Success Rate (ASR) on multiple safety benchmarks by a large margin. Data and Models are released under: \href{https://dripnowhy.github.io/MIS/}{\texttt{https://dripnowhy.github.io/MIS/}}