 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Clipping for Federated Learning: Convergence and Client-Level Differential Privacy
Jun 25, 2021



Providing privacy protection has been one of the primary motivations of Federated Learning (FL). Recently, there has been a line of work on incorporating the formal privacy notion of differential privacy with FL. To guarantee the client-level differential privacy in FL algorithms, the clients' transmitted model updates have to be clipped before adding privacy noise. Such clipping operation is substantially different from its counterpart of gradient clipping in the centralized differentially private SGD and has not been well-understood. In this paper, we first empirically demonstrate that the clipped FedAvg can perform surprisingly well even with substantial data heterogeneity when training neural networks, which is partly because the clients' updates become similar for several popular deep architectures. Based on this key observation, we provide the convergence analysis of a differential private (DP) FedAvg algorithm and highlight the relationship between clipping bias and the distribution of the clients' updates. To the best of our knowledge, this is the first work that rigorously investigates theoretical and empirical issues regarding the clipping operation in FL algorithms.
Towards Heterogeneous Clients with Elastic Federated Learning
Jun 17, 2021
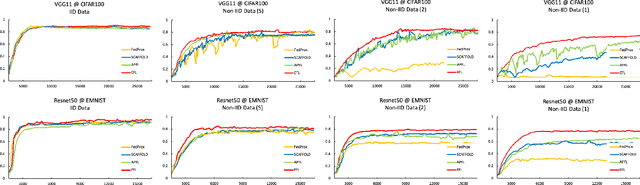
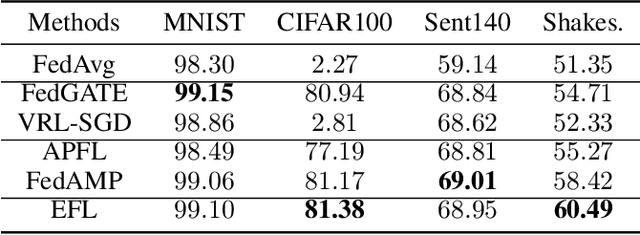
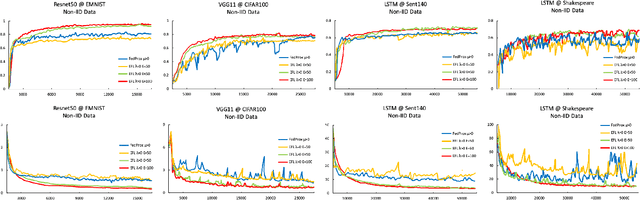
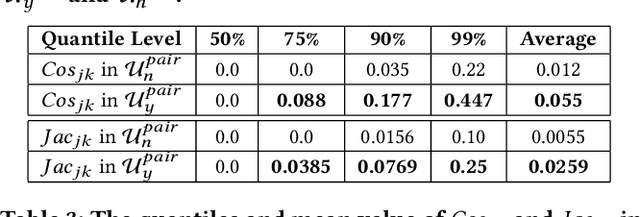
Federated learning involves training machine learning models over devices or data silos, such as edge processors or data warehouses, while keeping the data local. Training in heterogeneous and potentially massive networks introduces bias into the system, which is originated from the non-IID data and the low participation rate in reality. In this paper, we propose Elastic Federated Learning (EFL), an unbiased algorithm to tackle the heterogeneity in the system, which makes the most informative parameters less volatile during training, and utilizes the incomplete local updates. It is an efficient and effective algorithm that compresses both upstream and downstream communications. Theoretically, the algorithm has convergence guarantee when training on the non-IID data at the low participation rate. Empirical experiments corroborate the competitive performance of EFL framework on the robustness and the efficiency.
Leveraging Tripartite Interaction Information from Live Stream E-Commerce for Improving Product Recommendation
Jun 07, 2021


Recently, a new form of online shopping becomes more and more popular, which combines live streaming with E-Commerce activity. The streamers introduce products and interact with their audiences, and hence greatly improve the performance of selling products. Despite of the successful applications in industries, the live stream E-commerce has not been well studied in the data science community. To fill this gap, we investigate this brand-new scenario and collect a real-world Live Stream E-Commerce (LSEC) dataset. Different from conventional E-commerce activities, the streamers play a pivotal role in the LSEC events. Hence, the key is to make full use of rich interaction information among streamers, users, and products. We first conduct data analysis on the tripartite interaction data and quantify the streamer's influence on users' purchase behavior. Based on the analysis results, we model the tripartite information as a heterogeneous graph, which can be decomposed to multiple bipartite graphs in order to better capture the influence. We propose a novel Live Stream E-Commerce Graph Neural Network framework (LSEC-GNN) to learn the node representations of each bipartite graph, and further design a multi-task learning approach to improve product recommendation. Extensive experiments on two real-world datasets with different scales show that our method can significantly outperform various baseline approaches.
A Simple yet Universal Strategy for Online Convex Optimization
May 14, 2021Recently, several universal methods have been proposed for online convex optimization, and attain minimax rates for multiple types of convex functions simultaneously. However, they need to design and optimize one surrogate loss for each type of functions, which makes it difficult to exploit the structure of the problem and utilize the vast amount of existing algorithms. In this paper, we propose a simple strategy for universal online convex optimization, which avoids these limitations. The key idea is to construct a set of experts to process the original online functions, and deploy a meta-algorithm over the \emph{linearized} losses to aggregate predictions from experts. Specifically, we choose Adapt-ML-Prod to track the best expert, because it has a second-order bound and can be used to leverage strong convexity and exponential concavity. In this way, we can plug in off-the-shelf online solvers as black-box experts to deliver problem-dependent regret bounds. Furthermore, our strategy inherits the theoretical guarantee of any expert designed for strongly convex functions and exponentially concave functions, up to a double logarithmic factor. For general convex functions, it maintains the minimax optimality and also achieves a small-loss bound.
Fast Certified Robust Training via Better Initialization and Shorter Warmup
Apr 01, 2021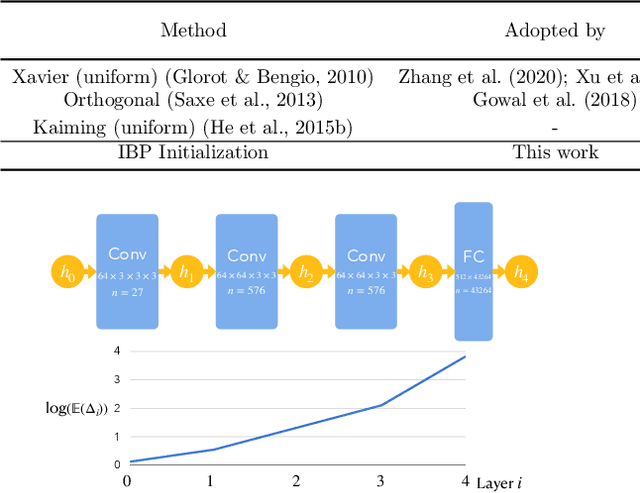
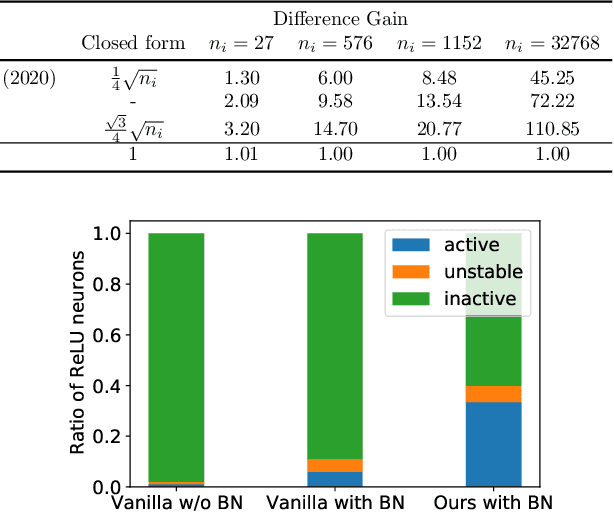
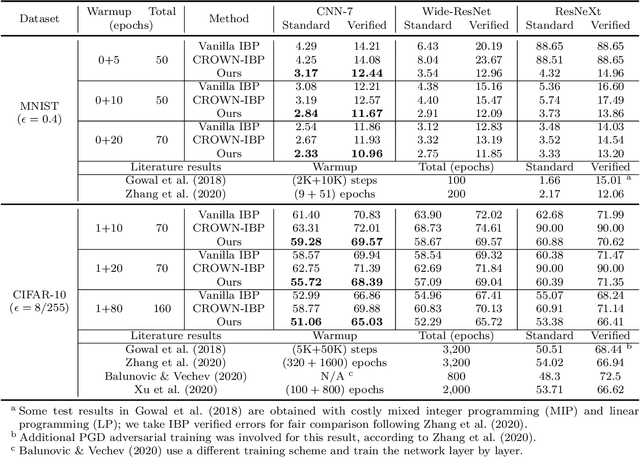
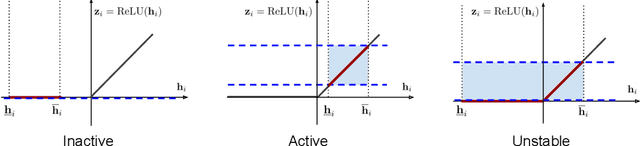
Recently, bound propagation based certified adversarial defense have been proposed for training neural networks with certifiable robustness guarantees. Despite state-of-the-art (SOTA) methods including interval bound propagation (IBP) and CROWN-IBP have per-batch training complexity similar to standard neural network training, to reach SOTA performance they usually need a long warmup schedule with hundreds or thousands epochs and are thus still quite costly for training. In this paper, we discover that the weight initialization adopted by prior works, such as Xavier or orthogonal initialization, which was originally designed for standard network training, results in very loose certified bounds at initialization thus a longer warmup schedule must be used. We also find that IBP based training leads to a significant imbalance in ReLU activation states, which can hamper model performance. Based on our findings, we derive a new IBP initialization as well as principled regularizers during the warmup stage to stabilize certified bounds during initialization and warmup stage, which can significantly reduce the warmup schedule and improve the balance of ReLU activation states. Additionally, we find that batch normalization (BN) is a crucial architectural element to build best-performing networks for certified training, because it helps stabilize bound variance and balance ReLU activation states. With our proposed initialization, regularizers and architectural changes combined, we are able to obtain 65.03% verified error on CIFAR-10 ($\epsilon=\frac{8}{255}$) and 82.13% verified error on TinyImageNet ($\epsilon=\frac{1}{255}$) using very short training schedules (160 and 80 total epochs, respectively), outperforming literature SOTA trained with a few hundreds or thousands epochs.
On the Adversarial Robustness of Visual Transformers
Mar 29, 2021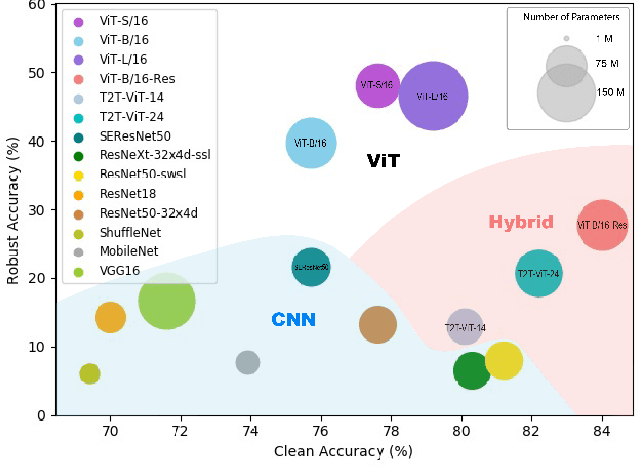
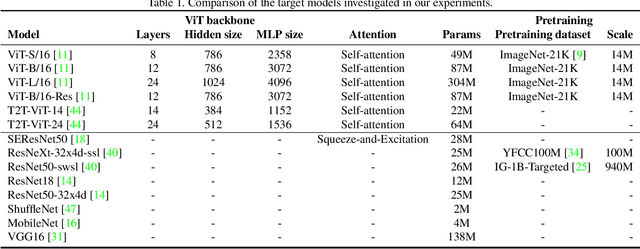
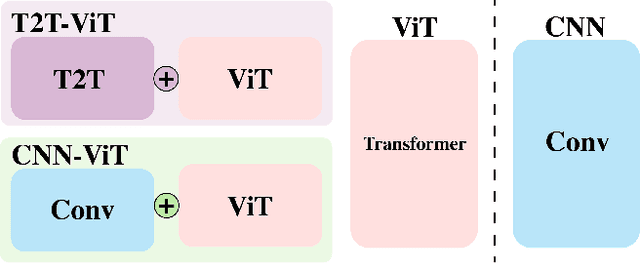
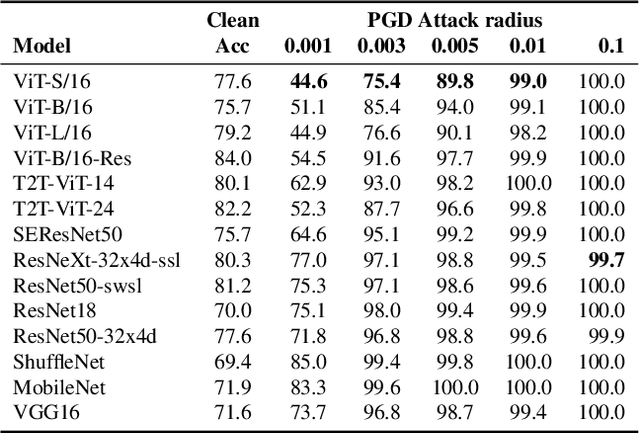
Following the success in advancing natural language processing and understanding, transformers are expected to bring revolutionary changes to computer vision. This work provides the first and comprehensive study on the robustness of vision transformers (ViTs) against adversarial perturbations. Tested on various white-box and transfer attack settings, we find that ViTs possess better adversarial robustness when compared with convolutional neural networks (CNNs). We summarize the following main observations contributing to the improved robustness of ViTs: 1) Features learned by ViTs contain less low-level information and are more generalizable, which contributes to superior robustness against adversarial perturbations. 2) Introducing convolutional or tokens-to-token blocks for learning low-level features in ViTs can improve classification accuracy but at the cost of adversarial robustness. 3) Increasing the proportion of transformers in the model structure (when the model consists of both transformer and CNN blocks) leads to better robustness. But for a pure transformer model, simply increasing the size or adding layers cannot guarantee a similar effect. 4) Pre-training on larger datasets does not significantly improve adversarial robustness though it is critical for training ViTs. 5) Adversarial training is also applicable to ViT for training robust models. Furthermore, feature visualization and frequency analysis are conducted for explanation. The results show that ViTs are less sensitive to high-frequency perturbations than CNNs and there is a high correlation between how well the model learns low-level features and its robustness against different frequency-based perturbations.
Provable Defense Against Delusive Poisoning
Feb 09, 2021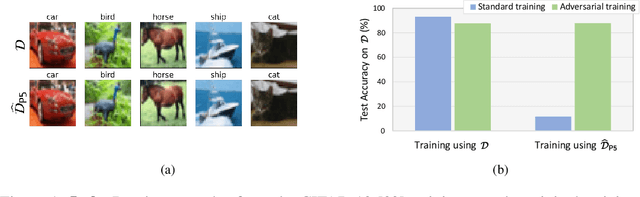
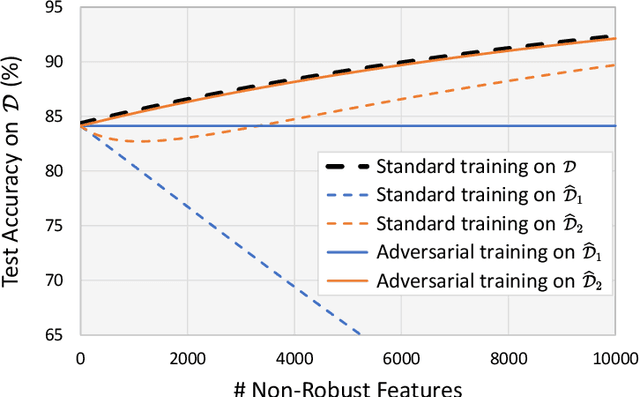
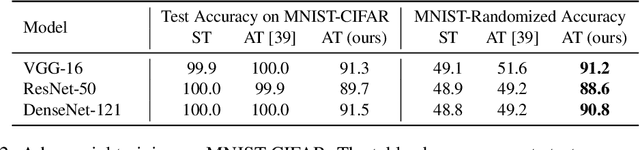
Delusive poisoning is a special kind of attack to obstruct learning, where the learning performance could be significantly deteriorated by only manipulating (even slightly) the features of correctly labeled training examples. By formalizing this malicious attack as finding the worst-case distribution shift at training time within a specific $\infty$-Wasserstein ball, we show that minimizing adversarial risk on the poison data is equivalent to optimizing an upper bound of natural risk on the original data. This implies that adversarial training can be a principled defense method against delusive poisoning. To further understand the internal mechanism of the defense, we disclose that adversarial training can resist the training distribution shift by preventing the learner from overly relying on non-robust features in a natural setting. Finally, we complement our theoretical findings with a set of experiments on popular benchmark datasets, which shows that the defense withstands six different practical attacks. Both theoretical and empirical results vote for adversarial training when confronted with delusive poisoning.
Robust Text CAPTCHAs Using Adversarial Examples
Jan 07, 2021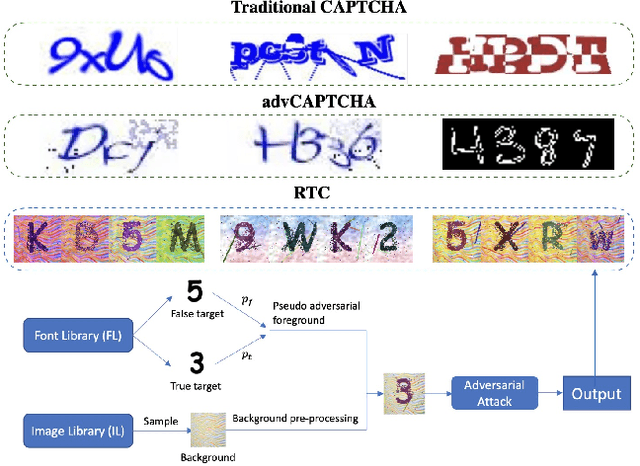
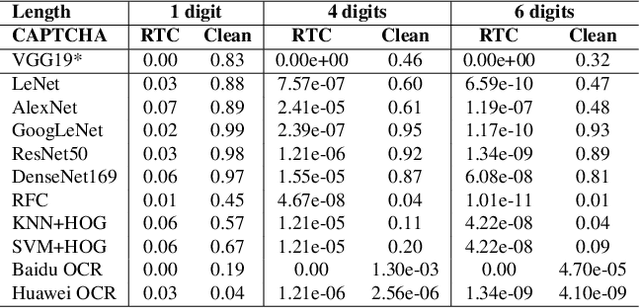

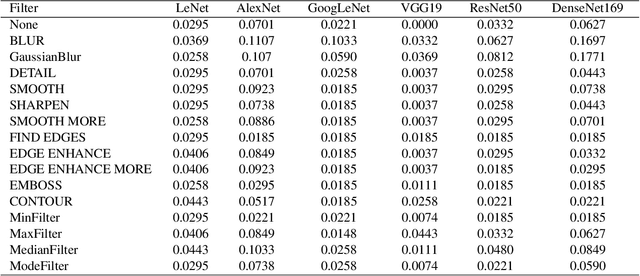
CAPTCHA (Completely Automated Public Truing test to tell Computers and Humans Apart) is a widely used technology to distinguish real users and automated users such as bots. However, the advance of AI technologies weakens many CAPTCHA tests and can induce security concerns. In this paper, we propose a user-friendly text-based CAPTCHA generation method named Robust Text CAPTCHA (RTC). At the first stage, the foregrounds and backgrounds are constructed with randomly sampled font and background images, which are then synthesized into identifiable pseudo adversarial CAPTCHAs. At the second stage, we design and apply a highly transferable adversarial attack for text CAPTCHAs to better obstruct CAPTCHA solvers. Our experiments cover comprehensive models including shallow models such as KNN, SVM and random forest, various deep neural networks and OCR models. Experiments show that our CAPTCHAs have a failure rate lower than one millionth in general and high usability. They are also robust against various defensive techniques that attackers may employ, including adversarial training, data pre-processing and manual tagging.
On the Limitations of Denoising Strategies as Adversarial Defenses
Dec 17, 2020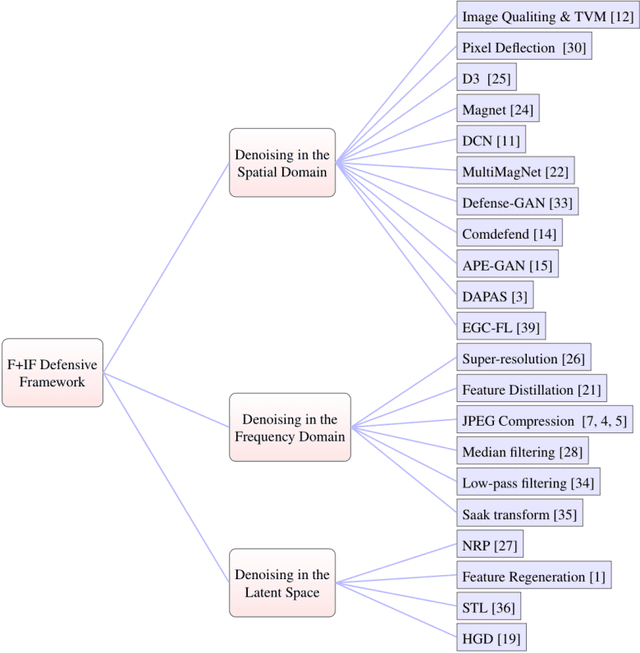
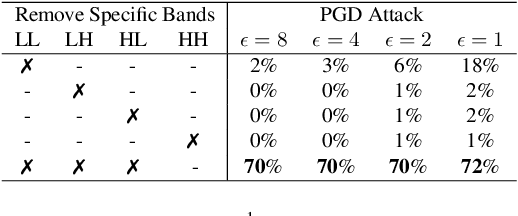
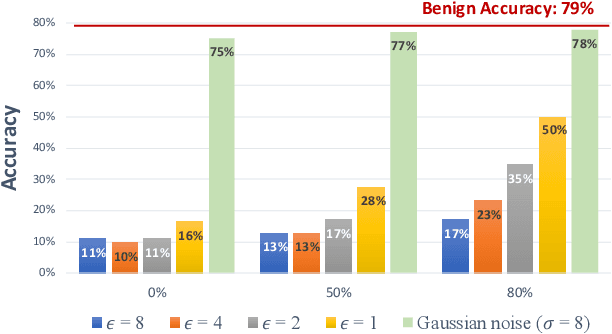
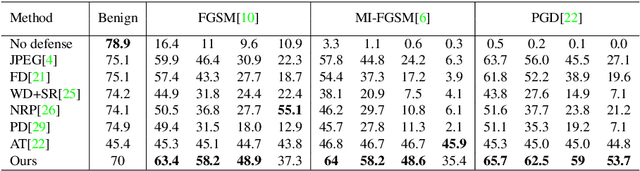
As adversarial attacks against machine learning models have raised increasing concerns, many denoising-based defense approaches have been proposed. In this paper, we summarize and analyze the defense strategies in the form of symmetric transformation via data denoising and reconstruction (denoted as $F+$ inverse $F$, $F-IF$ Framework). In particular, we categorize these denoising strategies from three aspects (i.e. denoising in the spatial domain, frequency domain, and latent space, respectively). Typically, defense is performed on the entire adversarial example, both image and perturbation are modified, making it difficult to tell how it defends against the perturbations. To evaluate the robustness of these denoising strategies intuitively, we directly apply them to defend against adversarial noise itself (assuming we have obtained all of it), which saving us from sacrificing benign accuracy. Surprisingly, our experimental results show that even if most of the perturbations in each dimension is eliminated, it is still difficult to obtain satisfactory robustness. Based on the above findings and analyses, we propose the adaptive compression strategy for different frequency bands in the feature domain to improve the robustness. Our experiment results show that the adaptive compression strategies enable the model to better suppress adversarial perturbations, and improve robustness compared with existing denoising strategies.
Provably Robust Metric Learning
Jun 12, 2020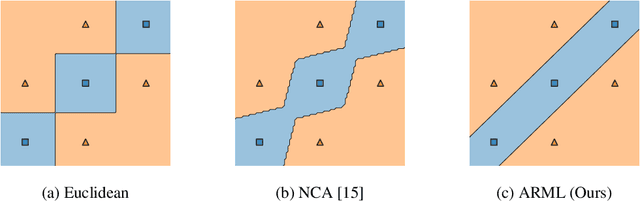
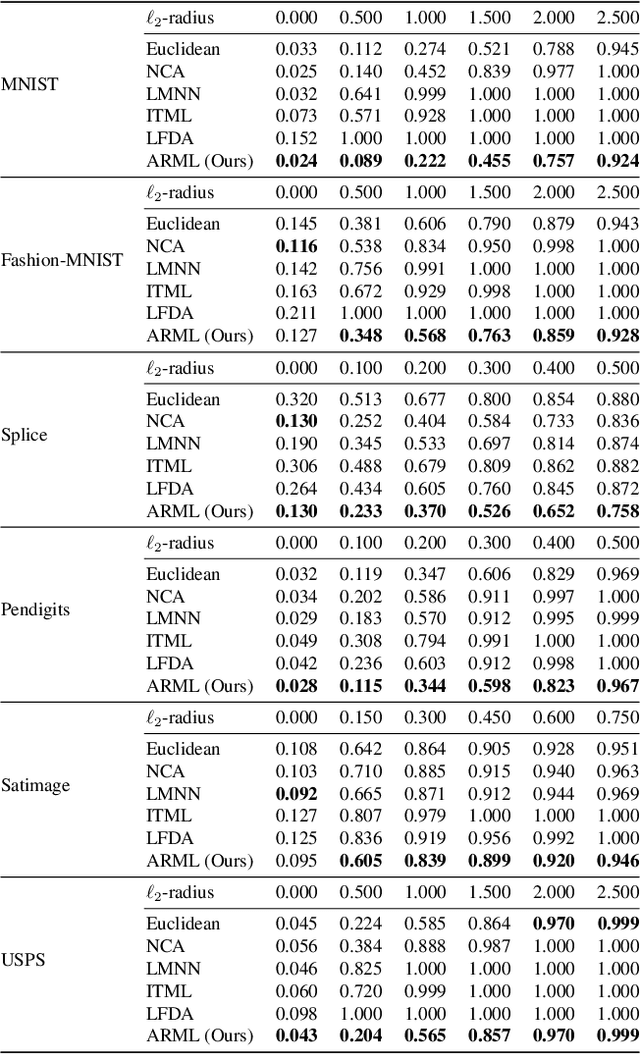
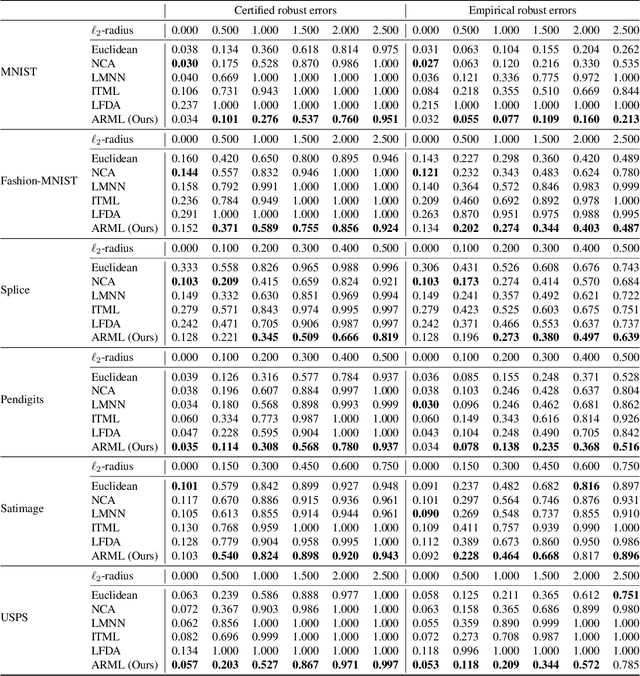
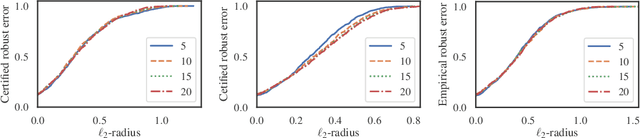
Metric learning is an important family of algorithms for classification and similarity search, but the robustness of learned metrics against small adversarial perturbations is less studied. In this paper, we show that existing metric learning algorithms, which focus on boosting the clean accuracy, can result in metrics that are less robust than the Euclidean distance. To overcome this problem, we propose a novel metric learning algorithm to find a Mahalanobis distance that is robust against adversarial perturbations, and the robustness of the resulting model is certifiable. Experimental results show that the proposed metric learning algorithm improves both certified robust errors and empirical robust errors (errors under adversarial attacks). Furthermore, unlike neural network defenses which usually encounter a trade-off between clean and robust errors, our method does not sacrifice clean errors compared with previous metric learning methods. Our code is available at https://github.com/wangwllu/provably_robust_metric_learning.