 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiHeFusion: Harnessing Large Language Models for Science Communication in Nuclear Fusion
Feb 08, 2025



Nuclear fusion is one of the most promising ways for humans to obtain infinite energy. Currently, with the rapid development of artificial intelligence, the mission of nuclear fusion has also entered a critical period of its development. How to let more people to understand nuclear fusion and join in its research is one of the effective means to accelerate the implementation of fusion. This paper proposes the first large model in the field of nuclear fusion, XiHeFusion, which is obtained through supervised fine-tuning based on the open-source large model Qwen2.5-14B. We have collected multi-source knowledge about nuclear fusion tasks to support the training of this model, including the common crawl, eBooks, arXiv, dissertation, etc. After the model has mastered the knowledge of the nuclear fusion field, we further used the chain of thought to enhance its logical reasoning ability, making XiHeFusion able to provide more accurate and logical answers. In addition, we propose a test questionnaire containing 180+ questions to assess the conversational ability of this science popularization large model. Extensive experimental results show that our nuclear fusion dialogue model, XiHeFusion, can perform well in answering science popularization knowledge. The pre-trained XiHeFusion model is released on https://github.com/Event-AHU/XiHeFusion.
Event Stream-based Visual Object Tracking: HDETrack V2 and A High-Definition Benchmark
Feb 08, 2025

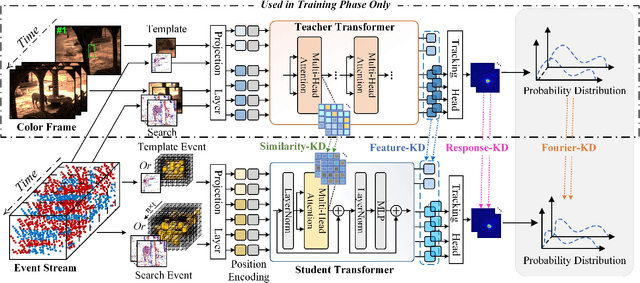

We then introduce a novel hierarchical knowledge distillation strategy that incorporates the similarity matrix, feature representation, and response map-based distillation to guide the learning of the student Transformer network. We also enhance the model's ability to capture temporal dependencies by applying the temporal Fourier transform to establish temporal relationships between video frames. We adapt the network model to specific target objects during testing via a newly proposed test-time tuning strategy to achieve high performance and flexibility in target tracking. Recognizing the limitations of existing event-based tracking datasets, which are predominantly low-resolution, we propose EventVOT, the first large-scale high-resolution event-based tracking dataset. It comprises 1141 videos spanning diverse categories such as pedestrians, vehicles, UAVs, ping pong, etc. Extensive experiments on both low-resolution (FE240hz, VisEvent, FELT), and our newly proposed high-resolution EventVOT dataset fully validated the effectiveness of our proposed method. Both the benchmark dataset and source code have been released on https://github.com/Event-AHU/EventVOT_Benchmark
LWGANet: A Lightweight Group Attention Backbone for Remote Sensing Visual Tasks
Jan 17, 2025Remote sensing (RS) visual tasks have gained significant academic and practical importance. However, they encounter numerous challenges that hinder effective feature extraction, including the detection and recognition of multiple objects exhibiting substantial variations in scale within a single image. While prior dual-branch or multi-branch architectural strategies have been effective in managing these object variances, they have concurrently resulted in considerable increases in computational demands and parameter counts. Consequently, these architectures are rendered less viable for deployment on resource-constrained devices. Contemporary lightweight backbone networks, designed primarily for natural images, frequently encounter difficulties in effectively extracting features from multi-scale objects, which compromises their efficacy in RS visual tasks. This article introduces LWGANet, a specialized lightweight backbone network tailored for RS visual tasks, incorporating a novel lightweight group attention (LWGA) module designed to address these specific challenges. LWGA module, tailored for RS imagery, adeptly harnesses redundant features to extract a wide range of spatial information, from local to global scales, without introducing additional complexity or computational overhead. This facilitates precise feature extraction across multiple scales within an efficient framework.LWGANet was rigorously evaluated across twelve datasets, which span four crucial RS visual tasks: scene classification, oriented object detection, semantic segmentation, and change detection. The results confirm LWGANet's widespread applicability and its ability to maintain an optimal balance between high performance and low complexity, achieving SOTA results across diverse datasets. LWGANet emerged as a novel solution for resource-limited scenarios requiring robust RS image processing capabilities.
Activating Associative Disease-Aware Vision Token Memory for LLM-Based X-ray Report Generation
Jan 07, 2025X-ray image based medical report generation achieves significant progress in recent years with the help of the large language model, however, these models have not fully exploited the effective information in visual image regions, resulting in reports that are linguistically sound but insufficient in describing key diseases. In this paper, we propose a novel associative memory-enhanced X-ray report generation model that effectively mimics the process of professional doctors writing medical reports. It considers both the mining of global and local visual information and associates historical report information to better complete the writing of the current report. Specifically, given an X-ray image, we first utilize a classification model along with its activation maps to accomplish the mining of visual regions highly associated with diseases and the learning of disease query tokens. Then, we employ a visual Hopfield network to establish memory associations for disease-related tokens, and a report Hopfield network to retrieve report memory information. This process facilitates the generation of high-quality reports based on a large language model and achieves state-of-the-art performance on multiple benchmark datasets, including the IU X-ray, MIMIC-CXR, and Chexpert Plus. The source code of this work is released on \url{https://github.com/Event-AHU/Medical_Image_Analysis}.
Dynamic Disentangled Fusion Network for RGBT Tracking
Dec 11, 2024



RGBT tracking usually suffers from various challenging factors of low resolution, similar appearance, extreme illumination, thermal crossover and occlusion, to name a few. Existing works often study complex fusion models to handle challenging scenarios, but can not well adapt to various challenges, which might limit tracking performance. To handle this problem, we propose a novel Dynamic Disentangled Fusion Network called DDFNet, which disentangles the fusion process into several dynamic fusion models via the challenge attributes to adapt to various challenging scenarios, for robust RGBT tracking. In particular, we design six attribute-based fusion models to integrate RGB and thermal features under the six challenging scenarios respectively.Since each fusion model is to deal with the corresponding challenges, such disentangled fusion scheme could increase the fusion capacity without the dependence on large-scale training data. Considering that every challenging scenario also has different levels of difficulty, we propose to optimize the combination of multiple fusion units to form each attribute-based fusion model in a dynamic manner, which could well adapt to the difficulty of the corresponding challenging scenario. To address the issue that which fusion models should be activated in the tracking process, we design an adaptive aggregation fusion module to integrate all features from attribute-based fusion models in an adaptive manner with a three-stage training algorithm. In addition, we design an enhancement fusion module to further strengthen the aggregated feature and modality-specific features. Experimental results on benchmark datasets demonstrate the effectiveness of our DDFNet against other state-of-the-art methods.
Text-Guided Coarse-to-Fine Fusion Network for Robust Remote Sensing Visual Question Answering
Nov 24, 2024



Remote Sensing Visual Question Answering (RSVQA) has gained significant research interest. However, current RSVQA methods are limited by the imaging mechanisms of optical sensors, particularly under challenging conditions such as cloud-covered and low-light scenarios. Given the all-time and all-weather imaging capabilities of Synthetic Aperture Radar (SAR), it is crucial to investigate the integration of optical-SAR images to improve RSVQA performance. In this work, we propose a Text-guided Coarse-to-Fine Fusion Network (TGFNet), which leverages the semantic relationships between question text and multi-source images to guide the network toward complementary fusion at the feature level. Specifically, we develop a Text-guided Coarse-to-Fine Attention Refinement (CFAR) module to focus on key areas related to the question in complex remote sensing images. This module progressively directs attention from broad areas to finer details through key region routing, enhancing the model's ability to focus on relevant regions. Furthermore, we propose an Adaptive Multi-Expert Fusion (AMEF) module that dynamically integrates different experts, enabling the adaptive fusion of optical and SAR features. In addition, we create the first large-scale benchmark dataset for evaluating optical-SAR RSVQA methods, comprising 6,008 well-aligned optical-SAR image pairs and 1,036,694 well-labeled question-answer pairs across 16 diverse question types, including complex relational reasoning questions. Extensive experiments on the proposed dataset demonstrate that our TGFNet effectively integrates complementary information between optical and SAR images, significantly improving the model's performance in challenging scenarios. The dataset is available at: https://github.com/mmic-lcl/. Index Terms: Remote Sensing Visual Question Answering, Multi-source Data Fusion, Multimodal, Remote Sensing, OPT-SAR.
UnityGraph: Unified Learning of Spatio-temporal features for Multi-person Motion Prediction
Nov 06, 2024



Multi-person motion prediction is a complex and emerging field with significant real-world applications. Current state-of-the-art methods typically adopt dual-path networks to separately modeling spatial features and temporal features. However, the uncertain compatibility of the two networks brings a challenge for spatio-temporal features fusion and violate the spatio-temporal coherence and coupling of human motions by nature. To address this issue, we propose a novel graph structure, UnityGraph, which treats spatio-temporal features as a whole, enhancing model coherence and coupling.spatio-temporal features as a whole, enhancing model coherence and coupling. Specifically, UnityGraph is a hypervariate graph based network. The flexibility of the hypergraph allows us to consider the observed motions as graph nodes. We then leverage hyperedges to bridge these nodes for exploring spatio-temporal features. This perspective considers spatio-temporal dynamics unitedly and reformulates multi-person motion prediction into a problem on a single graph. Leveraging the dynamic message passing based on this hypergraph, our model dynamically learns from both types of relations to generate targeted messages that reflect the relevance among nodes. Extensive experiments on several datasets demonstrates that our method achieves state-of-the-art performance, confirming its effectiveness and innovative design.
Relation Learning and Aggregate-attention for Multi-person Motion Prediction
Nov 06, 2024



Multi-person motion prediction is an emerging and intricate task with broad real-world applications. Unlike single person motion prediction, it considers not just the skeleton structures or human trajectories but also the interactions between others. Previous methods use various networks to achieve impressive predictions but often overlook that the joints relations within an individual (intra-relation) and interactions among groups (inter-relation) are distinct types of representations. These methods often lack explicit representation of inter&intra-relations, and inevitably introduce undesired dependencies. To address this issue, we introduce a new collaborative framework for multi-person motion prediction that explicitly modeling these relations:a GCN-based network for intra-relations and a novel reasoning network for inter-relations.Moreover, we propose a novel plug-and-play aggregation module called the Interaction Aggregation Module (IAM), which employs an aggregate-attention mechanism to seamlessly integrate these relations. Experiments indicate that the module can also be applied to other dual-path models. Extensive experiments on the 3DPW, 3DPW-RC, CMU-Mocap, MuPoTS-3D, as well as synthesized datasets Mix1 & Mix2 (9 to 15 persons), demonstrate that our method achieves state-of-the-art performance.
Reliable and Compact Graph Fine-tuning via GraphSparse Prompting
Oct 29, 2024



Recently, graph prompt learning has garnered increasing attention in adapting pre-trained GNN models for downstream graph learning tasks. However, existing works generally conduct prompting over all graph elements (e.g., nodes, edges, node attributes, etc.), which is suboptimal and obviously redundant. To address this issue, we propose exploiting sparse representation theory for graph prompting and present Graph Sparse Prompting (GSP). GSP aims to adaptively and sparsely select the optimal elements (e.g., certain node attributes) to achieve compact prompting for downstream tasks. Specifically, we propose two kinds of GSP models, termed Graph Sparse Feature Prompting (GSFP) and Graph Sparse multi-Feature Prompting (GSmFP). Both GSFP and GSmFP provide a general scheme for tuning any specific pre-trained GNNs that can achieve attribute selection and compact prompt learning simultaneously. A simple yet effective algorithm has been designed for solving GSFP and GSmFP models. Experiments on 16 widely-used benchmark datasets validate the effectiveness and advantages of the proposed GSFPs.
Guidance Disentanglement Network for Optics-Guided Thermal UAV Image Super-Resolution
Oct 27, 2024Optics-guided Thermal UAV image Super-Resolution (OTUAV-SR) has attracted significant research interest due to its potential applications in security inspection, agricultural measurement, and object detection. Existing methods often employ single guidance model to generate the guidance features from optical images to assist thermal UAV images super-resolution. However, single guidance models make it difficult to generate effective guidance features under favorable and adverse conditions in UAV scenarios, thus limiting the performance of OTUAV-SR. To address this issue, we propose a novel Guidance Disentanglement network (GDNet), which disentangles the optical image representation according to typical UAV scenario attributes to form guidance features under both favorable and adverse conditions, for robust OTUAV-SR. Moreover, we design an attribute-aware fusion module to combine all attribute-based optical guidance features, which could form a more discriminative representation and fit the attribute-agnostic guidance process. To facilitate OTUAV-SR research in complex UAV scenarios, we introduce VGTSR2.0, a large-scale benchmark dataset containing 3,500 aligned optical-thermal image pairs captured under diverse conditions and scenes. Extensive experiments on VGTSR2.0 demonstrate that GDNet significantly improves OTUAV-SR performance over state-of-the-art methods, especially in the challenging low-light and foggy environments commonly encountered in UAV scenarios. The dataset and code will be publicly available at https://github.com/Jocelyney/GDNet.