 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Reactive Framework for Whole-Body Motion Planning of Mobile Manipulators Combining Reinforcement Learning and SDF-Constrained Quadratic Programmi
Mar 31, 2025As an important branch of embodied artificial intelligence, mobile manipulators are increasingly applied in intelligent services, but their redundant degrees of freedom also limit efficient motion planning in cluttered environments. To address this issue, this paper proposes a hybrid learning and optimization framework for reactive whole-body motion planning of mobile manipulators. We develop the Bayesian distributional soft actor-critic (Bayes-DSAC) algorithm to improve the quality of value estimation and the convergence performance of the learning. Additionally, we introduce a quadratic programming method constrained by the signed distance field to enhance the safety of the obstacle avoidance motion. We conduct experiments and make comparison with standard benchmark. The experimental results verify that our proposed framework significantly improves the efficiency of reactive whole-body motion planning, reduces the planning time, and improves the success rate of motion planning. Additionally, the proposed reinforcement learning method ensures a rapid learning process in the whole-body planning task. The novel framework allows mobile manipulators to adapt to complex environments more safely and efficiently.
Swin-X2S: Reconstructing 3D Shape from 2D Biplanar X-ray with Swin Transformers
Jan 10, 2025



The conversion from 2D X-ray to 3D shape holds significant potential for improving diagnostic efficiency and safety. However, existing reconstruction methods often rely on hand-crafted features, manual intervention, and prior knowledge, resulting in unstable shape errors and additional processing costs. In this paper, we introduce Swin-X2S, an end-to-end deep learning method for directly reconstructing 3D segmentation and labeling from 2D biplanar orthogonal X-ray images. Swin-X2S employs an encoder-decoder architecture: the encoder leverages 2D Swin Transformer for X-ray information extraction, while the decoder employs 3D convolution with cross-attention to integrate structural features from orthogonal views. A dimension-expanding module is introduced to bridge the encoder and decoder, ensuring a smooth conversion from 2D pixels to 3D voxels. We evaluate proposed method through extensive qualitative and quantitative experiments across nine publicly available datasets covering four anatomies (femur, hip, spine, and rib), with a total of 54 categories. Significant improvements over previous methods have been observed not only in the segmentation and labeling metrics but also in the clinically relevant parameters that are of primary concern in practical applications, which demonstrates the promise of Swin-X2S to provide an effective option for anatomical shape reconstruction in clinical scenarios. Code implementation is available at: \url{https://github.com/liukuan5625/Swin-X2S}.
Escaping the Curse of Dimensionality in Similarity Learning: Efficient Frank-Wolfe Algorithm and Generalization Bounds
Oct 31, 2018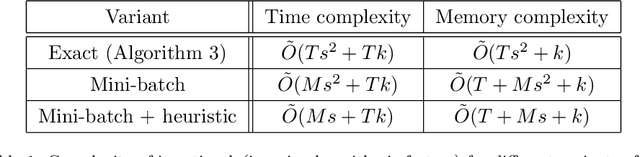
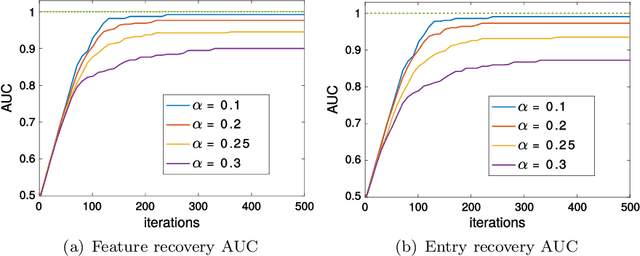
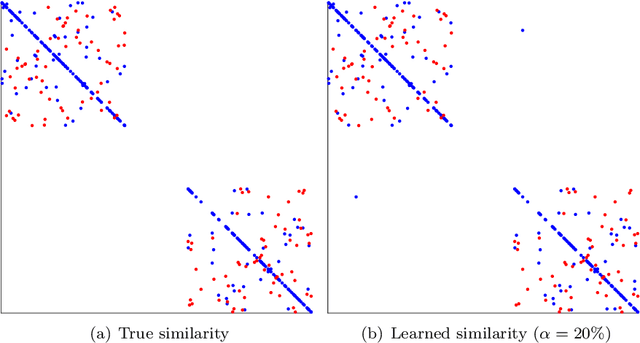
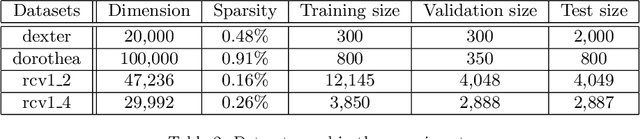
Similarity and metric learning provides a principled approach to construct a task-specific similarity from weakly supervised data. However, these methods are subject to the curse of dimensionality: as the number of features grows large, poor generalization is to be expected and training becomes intractable due to high computational and memory costs. In this paper, we propose a similarity learning method that can efficiently deal with high-dimensional sparse data. This is achieved through a parameterization of similarity functions by convex combinations of sparse rank-one matrices, together with the use of a greedy approximate Frank-Wolfe algorithm which provides an efficient way to control the number of active features. We show that the convergence rate of the algorithm, as well as its time and memory complexity, are independent of the data dimension. We further provide a theoretical justification of our modeling choices through an analysis of the generalization error, which depends logarithmically on the sparsity of the solution rather than on the number of features. Our experiments on datasets with up to one million features demonstrate the ability of our approach to generalize well despite the high dimensionality as well as its superiority compared to several competing methods.
Learn to Combine Modalities in Multimodal Deep Learning
May 29, 2018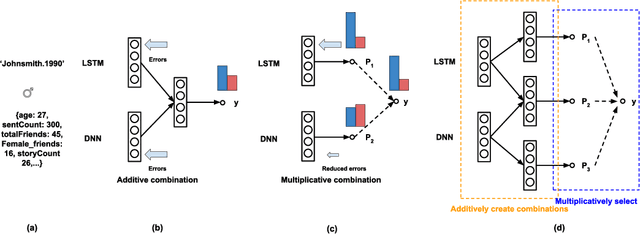

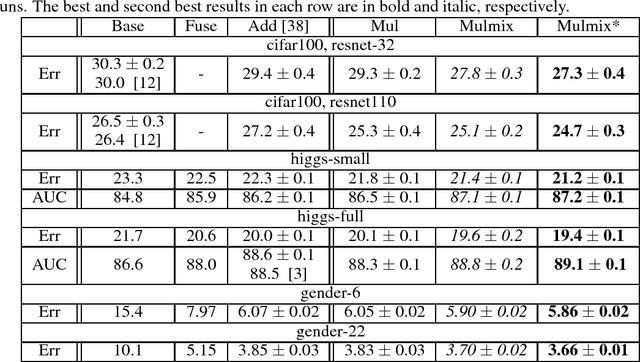
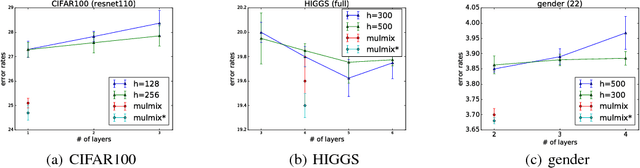
Combining complementary information from multiple modalities is intuitively appealing for improving the performance of learning-based approaches. However, it is challenging to fully leverage different modalities due to practical challenges such as varying levels of noise and conflicts between modalities. Existing methods do not adopt a joint approach to capturing synergies between the modalities while simultaneously filtering noise and resolving conflicts on a per sample basis. In this work we propose a novel deep neural network based technique that multiplicatively combines information from different source modalities. Thus the model training process automatically focuses on information from more reliable modalities while reducing emphasis on the less reliable modalities. Furthermore, we propose an extension that multiplicatively combines not only the single-source modalities, but a set of mixtured source modalities to better capture cross-modal signal correlations. We demonstrate the effectiveness of our proposed technique by presenting empirical results on three multimodal classification tasks from different domains. The results show consistent accuracy improvements on all three tasks.
A Sequential Embedding Approach for Item Recommendation with Heterogeneous Attributes
May 28, 2018

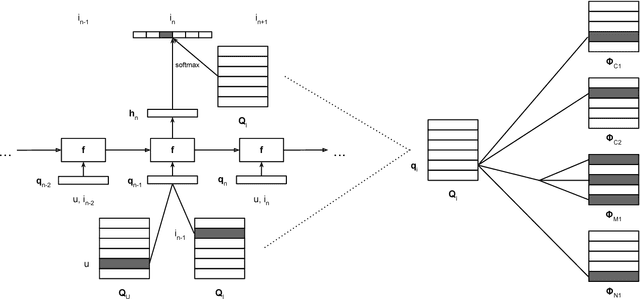
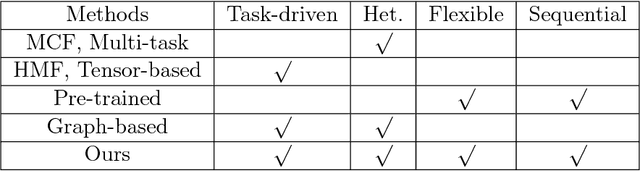
Attributes, such as metadata and profile, carry useful information which in principle can help improve accuracy in recommender systems. However, existing approaches have difficulty in fully leveraging attribute information due to practical challenges such as heterogeneity and sparseness. These approaches also fail to combine recurrent neural networks which have recently shown effectiveness in item recommendations in applications such as video and music browsing. To overcome the challenges and to harvest the advantages of sequence models, we present a novel approach, Heterogeneous Attribute Recurrent Neural Networks (HA-RNN), which incorporates heterogeneous attributes and captures sequential dependencies in \textit{both} items and attributes. HA-RNN extends recurrent neural networks with 1) a hierarchical attribute combination input layer and 2) an output attribute embedding layer. We conduct extensive experiments on two large-scale datasets. The new approach show significant improvements over the state-of-the-art models. Our ablation experiments demonstrate the effectiveness of the two components to address heterogeneous attribute challenges including variable lengths and attribute sparseness. We further investigate why sequence modeling works well by conducting exploratory studies and show sequence models are more effective when data scale increases.
A Batch Learning Framework for Scalable Personalized Ranking
Nov 10, 2017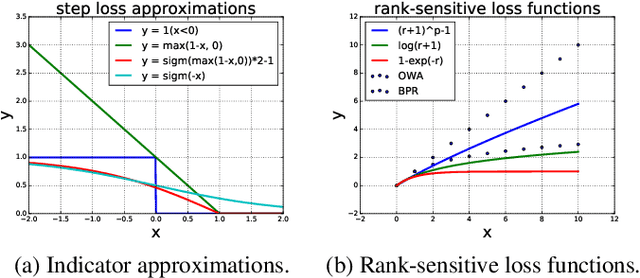

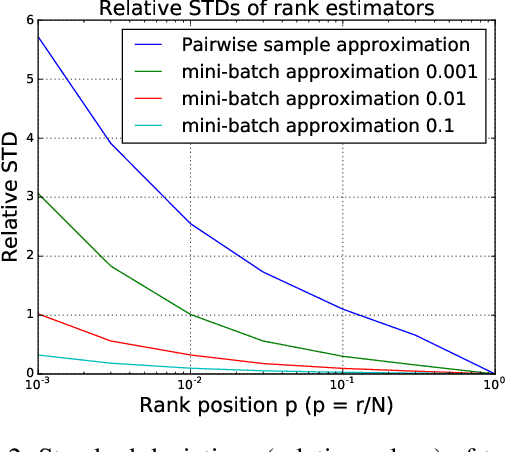
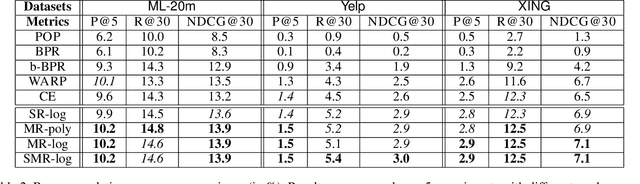
In designing personalized ranking algorithms, it is desirable to encourage a high precision at the top of the ranked list. Existing methods either seek a smooth convex surrogate for a non-smooth ranking metric or directly modify updating procedures to encourage top accuracy. In this work we point out that these methods do not scale well to a large-scale setting, and this is partly due to the inaccurate pointwise or pairwise rank estimation. We propose a new framework for personalized ranking. It uses batch-based rank estimators and smooth rank-sensitive loss functions. This new batch learning framework leads to more stable and accurate rank approximations compared to previous work. Moreover, it enables explicit use of parallel computation to speed up training. We conduct empirical evaluation on three item recommendation tasks. Our method shows consistent accuracy improvements over state-of-the-art methods. Additionally, we observe time efficiency advantages when data scale increases.
* AAAI 2018, Feb 2-7, New Orleans, USA
WMRB: Learning to Rank in a Scalable Batch Training Approach
Nov 10, 2017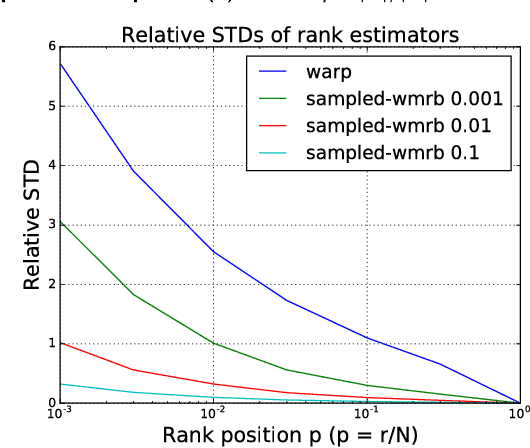
We propose a new learning to rank algorithm, named Weighted Margin-Rank Batch loss (WMRB), to extend the popular Weighted Approximate-Rank Pairwise loss (WARP). WMRB uses a new rank estimator and an efficient batch training algorithm. The approach allows more accurate item rank approximation and explicit utilization of parallel computation to accelerate training. In three item recommendation tasks, WMRB consistently outperforms WARP and other baselines. Moreover, WMRB shows clear time efficiency advantages as data scale increases.
Kernel Approximation Methods for Speech Recognition
Jan 13, 2017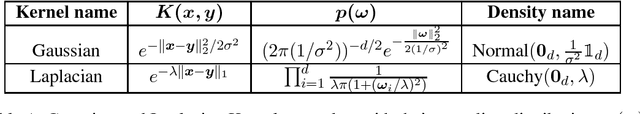
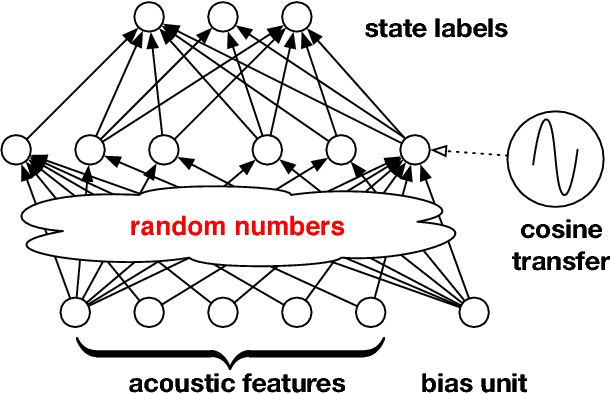
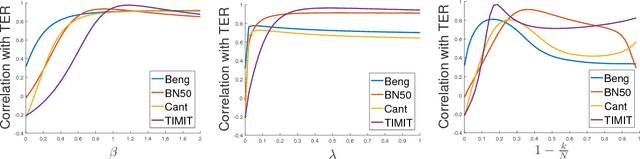

We study large-scale kernel methods for acoustic modeling in speech recognition and compare their performance to deep neural networks (DNNs). We perform experiments on four speech recognition datasets, including the TIMIT and Broadcast News benchmark tasks, and compare these two types of models on frame-level performance metrics (accuracy, cross-entropy), as well as on recognition metrics (word/character error rate). In order to scale kernel methods to these large datasets, we use the random Fourier feature method of Rahimi and Recht (2007). We propose two novel techniques for improving the performance of kernel acoustic models. First, in order to reduce the number of random features required by kernel models, we propose a simple but effective method for feature selection. The method is able to explore a large number of non-linear features while maintaining a compact model more efficiently than existing approaches. Second, we present a number of frame-level metrics which correlate very strongly with recognition performance when computed on the heldout set; we take advantage of these correlations by monitoring these metrics during training in order to decide when to stop learning. This technique can noticeably improve the recognition performance of both DNN and kernel models, while narrowing the gap between them. Additionally, we show that the linear bottleneck method of Sainath et al. (2013) improves the performance of our kernel models significantly, in addition to speeding up training and making the models more compact. Together, these three methods dramatically improve the performance of kernel acoustic models, making their performance comparable to DNNs on the tasks we explored.
Temporal Learning and Sequence Modeling for a Job Recommender System
Aug 11, 2016
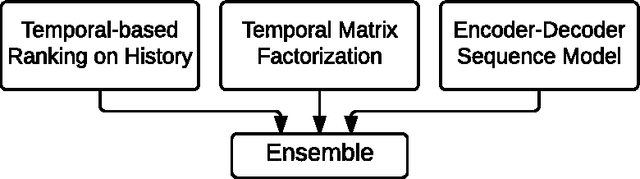
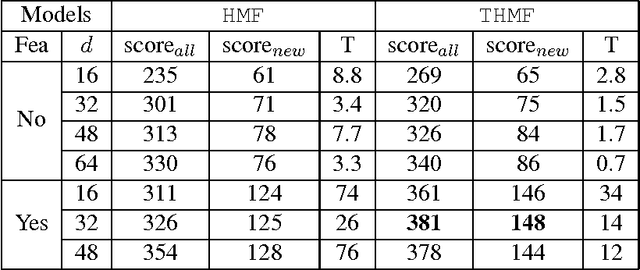
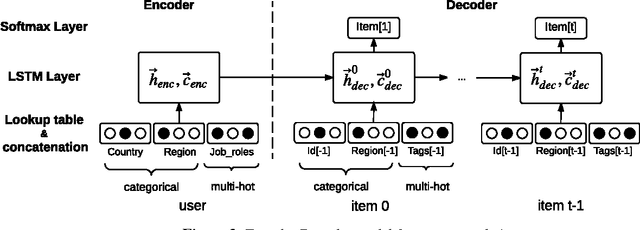
We present our solution to the job recommendation task for RecSys Challenge 2016. The main contribution of our work is to combine temporal learning with sequence modeling to capture complex user-item activity patterns to improve job recommendations. First, we propose a time-based ranking model applied to historical observations and a hybrid matrix factorization over time re-weighted interactions. Second, we exploit sequence properties in user-items activities and develop a RNN-based recommendation model. Our solution achieved 5$^{th}$ place in the challenge among more than 100 participants. Notably, the strong performance of our RNN approach shows a promising new direction in employing sequence modeling for recommendation systems.
A Comparison between Deep Neural Nets and Kernel Acoustic Models for Speech Recognition
Mar 18, 2016


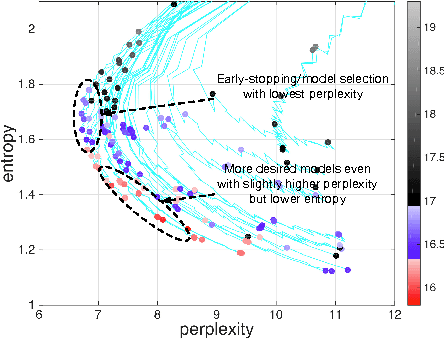
We study large-scale kernel methods for acoustic modeling and compare to DNNs on performance metrics related to both acoustic modeling and recognition. Measuring perplexity and frame-level classification accuracy, kernel-based acoustic models are as effective as their DNN counterparts. However, on token-error-rates DNN models can be significantly better. We have discovered that this might be attributed to DNN's unique strength in reducing both the perplexity and the entropy of the predicted posterior probabilities. Motivated by our findings, we propose a new technique, entropy regularized perplexity, for model selection. This technique can noticeably improve the recognition performance of both types of models, and reduces the gap between them. While effective on Broadcast News, this technique could be also applicable to other tasks.