 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidence Calibration for Multimodal LLMs: An Empirical Study through Medical VQA
Jun 18, 2026Multimodal Large Language Models (MLLMs) show great potential in medical tasks, but their elicited confidence often misaligns with actual accuracy, potentially leading to misdiagnosis or overlooking correct advice. This study presents the first comprehensive analysis of the relationship between accuracy and confidence in medical MLLMs. It proposes a novel method that combines Multi-Strategy Fusion-Based Interrogation (MS-FBI) with auxiliary expert LLM assessment, aiming to improve confidence calibration in Medical Visual Question Answering (VQA). Experiments demonstrate that our method reduces the Expected Calibration Error (ECE) by an average of 40\% across three Medical VQA datasets, significantly enhancing MLLMs' reliability. The findings highlight the importance of domain-specific calibration for MLLMs in healthcare, offering a more trustworthy solution for AI-assisted diagnosis.
AxiomOcean: Forecasting the Three-Dimensional Structure of the Upper Ocean
May 11, 2026Short-term ocean forecast skill depends strongly on the three-dimensional ocean structure of the upper ocean, which governs stratification, subsurface heat storage, and the response of the ocean to atmospheric forcing. However, AI ocean forecasting models often fail to preserve this vertical structure, resulting in over-smoothed subsurface features and weak physical consistency under strong forcing. Here, we present AxiomOcean, a global AI ocean forecasting model that explicitly represents vertical hierarchy and cross-layer dependence within the water column. By combining a fully three-dimensional encoder-backbone-decoder architecture with surface atmospheric forcing, AxiomOcean jointly predicts upper-ocean temperature, salinity, and three-dimensional currents at global 1/12° resolution down to 643 m depth. In 10-day forecasts, AxiomOcean outperforms an advanced AI comparison model across variables and lead times, reducing day-1 RMSE by approximately 20 to 35% while maintaining higher anomaly correlation. The gain is not achieved through excessive smoothing: AxiomOcean better preserves eddy kinetic energy, temperature and salinity variance. Its advantage also extends through the water column and remains evident across the equatorial Pacific, Kuroshio Extension, and Southern Ocean, yielding a more realistic reconstruction of upper-ocean heat content. These results show that explicitly preserving upper-ocean three-dimensional structure can improve both forecast accuracy and physical fidelity in AI ocean prediction.
Linking Perception, Confidence and Accuracy in MLLMs
Mar 12, 2026Recent advances in Multi-modal Large Language Models (MLLMs) have predominantly focused on enhancing visual perception to improve accuracy. However, a critical question remains unexplored: Do models know when they do not know? Through a probing experiment, we reveal a severe confidence miscalibration problem in MLLMs. To address this, we propose Confidence-Driven Reinforcement Learning (CDRL), which uses original-noise image pairs and a novel confidence-based reward to enhance perceptual sensitivity and robustly calibrate the model's confidence. Beyond training benefits, calibrated confidence enables more effective test-time scaling as a free lunch. We further propose Confidence-Aware Test-Time Scaling (CA-TTS), which dynamically coordinates Self-Consistency, Self-Reflection, and Visual Self-Check modules guided by confidence signals. An Expert Model acts in multiple roles (e.g., Planner, Critic, Voter) to schedule these modules and provide external verification. Our integrated framework establishes new state-of-the-art results with consistent 8.8% gains across four benchmarks. More ablation studies demonstrate the effectiveness of each module and scaling superiority.
Variation-aware Flexible 3D Gaussian Editing
Feb 13, 2026Indirect editing methods for 3D Gaussian Splatting (3DGS) have recently witnessed significant advancements. These approaches operate by first applying edits in the rendered 2D space and subsequently projecting the modifications back into 3D. However, this paradigm inevitably introduces cross-view inconsistencies and constrains both the flexibility and efficiency of the editing process. To address these challenges, we present VF-Editor, which enables native editing of Gaussian primitives by predicting attribute variations in a feedforward manner. To accurately and efficiently estimate these variations, we design a novel variation predictor distilled from 2D editing knowledge. The predictor encodes the input to generate a variation field and employs two learnable, parallel decoding functions to iteratively infer attribute changes for each 3D Gaussian. Thanks to its unified design, VF-Editor can seamlessly distill editing knowledge from diverse 2D editors and strategies into a single predictor, allowing for flexible and effective knowledge transfer into the 3D domain. Extensive experiments on both public and private datasets reveal the inherent limitations of indirect editing pipelines and validate the effectiveness and flexibility of our approach.
Style-Aligned Image Composition for Robust Detection of Abnormal Cells in Cytopathology
Jun 26, 2025



Challenges such as the lack of high-quality annotations, long-tailed data distributions, and inconsistent staining styles pose significant obstacles to training neural networks to detect abnormal cells in cytopathology robustly. This paper proposes a style-aligned image composition (SAIC) method that composes high-fidelity and style-preserved pathological images to enhance the effectiveness and robustness of detection models. Without additional training, SAIC first selects an appropriate candidate from the abnormal cell bank based on attribute guidance. Then, it employs a high-frequency feature reconstruction to achieve a style-aligned and high-fidelity composition of abnormal cells and pathological backgrounds. Finally, it introduces a large vision-language model to filter high-quality synthesis images. Experimental results demonstrate that incorporating SAIC-synthesized images effectively enhances the performance and robustness of abnormal cell detection for tail categories and styles, thereby improving overall detection performance. The comprehensive quality evaluation further confirms the generalizability and practicality of SAIC in clinical application scenarios. Our code will be released at https://github.com/Joey-Qi/SAIC.
Distilling Multi-view Diffusion Models into 3D Generators
Apr 03, 2025We introduce DD3G, a formulation that Distills a multi-view Diffusion model (MV-DM) into a 3D Generator using gaussian splatting. DD3G compresses and integrates extensive visual and spatial geometric knowledge from the MV-DM by simulating its ordinary differential equation (ODE) trajectory, ensuring the distilled generator generalizes better than those trained solely on 3D data. Unlike previous amortized optimization approaches, we align the MV-DM and 3D generator representation spaces to transfer the teacher's probabilistic flow to the student, thus avoiding inconsistencies in optimization objectives caused by probabilistic sampling. The introduction of probabilistic flow and the coupling of various attributes in 3D Gaussians introduce challenges in the generation process. To tackle this, we propose PEPD, a generator consisting of Pattern Extraction and Progressive Decoding phases, which enables efficient fusion of probabilistic flow and converts a single image into 3D Gaussians within 0.06 seconds. Furthermore, to reduce knowledge loss and overcome sparse-view supervision, we design a joint optimization objective that ensures the quality of generated samples through explicit supervision and implicit verification. Leveraging existing 2D generation models, we compile 120k high-quality RGBA images for distillation. Experiments on synthetic and public datasets demonstrate the effectiveness of our method. Our project is available at: https://qinbaigao.github.io/DD3G_project/
Probablistic Restoration with Adaptive Noise Sampling for 3D Human Pose Estimation
May 03, 2024



The accuracy and robustness of 3D human pose estimation (HPE) are limited by 2D pose detection errors and 2D to 3D ill-posed challenges, which have drawn great attention to Multi-Hypothesis HPE research. Most existing MH-HPE methods are based on generative models, which are computationally expensive and difficult to train. In this study, we propose a Probabilistic Restoration 3D Human Pose Estimation framework (PRPose) that can be integrated with any lightweight single-hypothesis model. Specifically, PRPose employs a weakly supervised approach to fit the hidden probability distribution of the 2D-to-3D lifting process in the Single-Hypothesis HPE model and then reverse-map the distribution to the 2D pose input through an adaptive noise sampling strategy to generate reasonable multi-hypothesis samples effectively. Extensive experiments on 3D HPE benchmarks (Human3.6M and MPI-INF-3DHP) highlight the effectiveness and efficiency of PRPose. Code is available at: https://github.com/xzhouzeng/PRPose.
Deep Sequential Feature Learning in Clinical Image Classification of Infectious Keratitis
Jun 04, 2020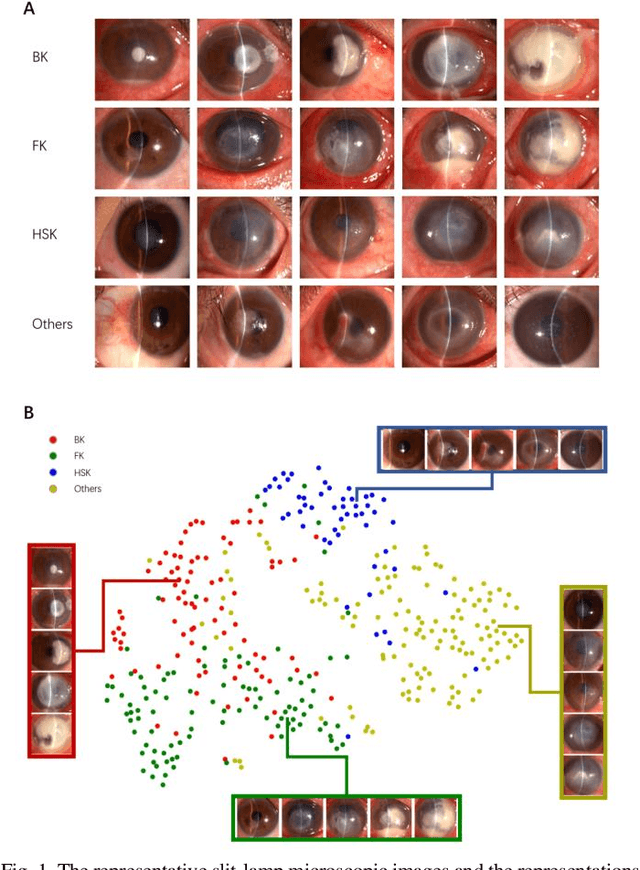
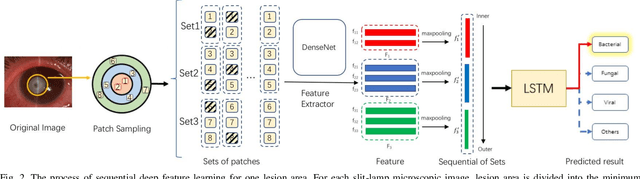
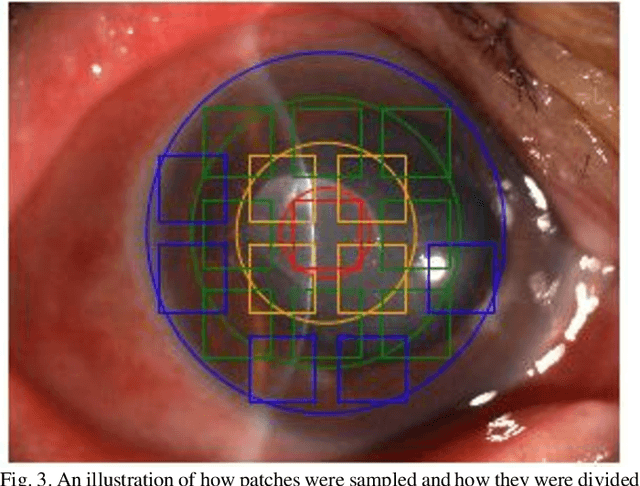
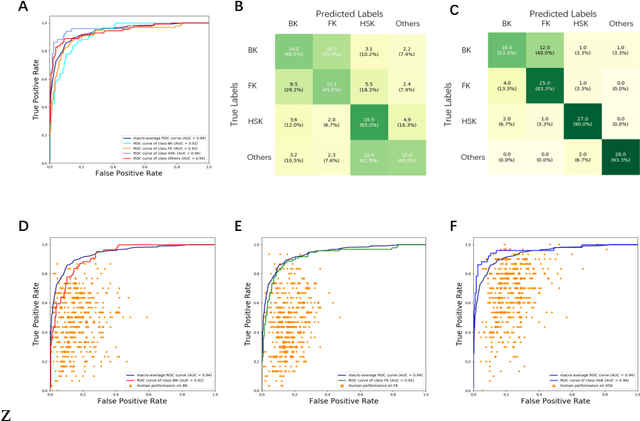
Infectious keratitis is the most common entities of corneal diseases, in which pathogen grows in the cornea leading to inflammation and destruction of the corneal tissues. Infectious keratitis is a medical emergency, for which a rapid and accurate diagnosis is needed for speedy initiation of prompt and precise treatment to halt the disease progress and to limit the extent of corneal damage; otherwise it may develop sight-threatening and even eye-globe-threatening condition. In this paper, we propose a sequential-level deep learning model to effectively discriminate the distinction and subtlety of infectious corneal disease via the classification of clinical images. In this approach, we devise an appropriate mechanism to preserve the spatial structures of clinical images and disentangle the informative features for clinical image classification of infectious keratitis. In competition with 421 ophthalmologists, the performance of the proposed sequential-level deep model achieved 80.00% diagnostic accuracy, far better than the 49.27% diagnostic accuracy achieved by ophthalmologists over 120 test images.