 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProposalContrast: Unsupervised Pre-training for LiDAR-based 3D Object Detection
Jul 26, 2022
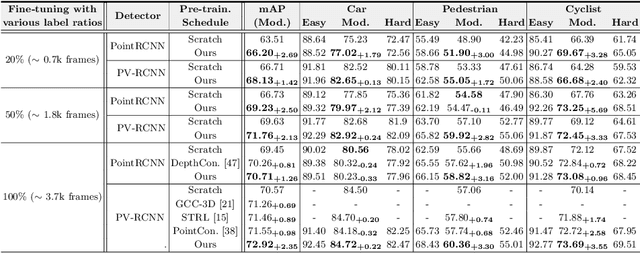
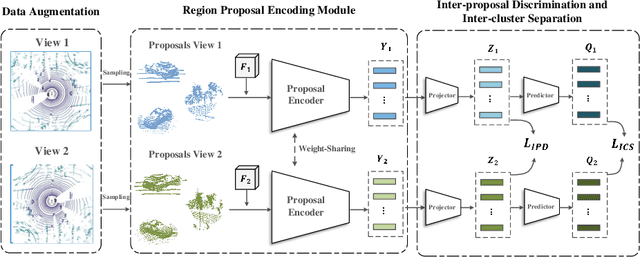
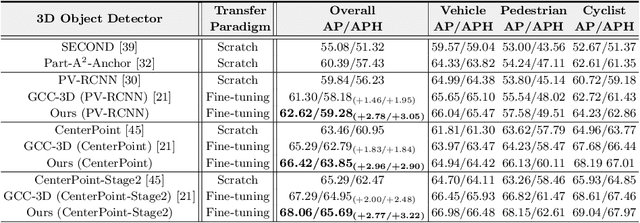
Existing approaches for unsupervised point cloud pre-training are constrained to either scene-level or point/voxel-level instance discrimination. Scene-level methods tend to lose local details that are crucial for recognizing the road objects, while point/voxel-level methods inherently suffer from limited receptive field that is incapable of perceiving large objects or context environments. Considering region-level representations are more suitable for 3D object detection, we devise a new unsupervised point cloud pre-training framework, called ProposalContrast, that learns robust 3D representations by contrasting region proposals. Specifically, with an exhaustive set of region proposals sampled from each point cloud, geometric point relations within each proposal are modeled for creating expressive proposal representations. To better accommodate 3D detection properties, ProposalContrast optimizes with both inter-cluster and inter-proposal separation, i.e., sharpening the discriminativeness of proposal representations across semantic classes and object instances. The generalizability and transferability of ProposalContrast are verified on various 3D detectors (i.e., PV-RCNN, CenterPoint, PointPillars and PointRCNN) and datasets (i.e., KITTI, Waymo and ONCE).
Imitate then Transcend: Multi-Agent Optimal Execution with Dual-Window Denoise PPO
Jun 21, 2022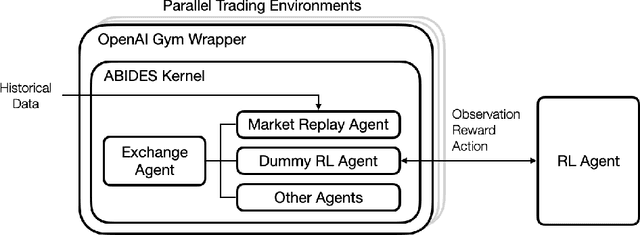
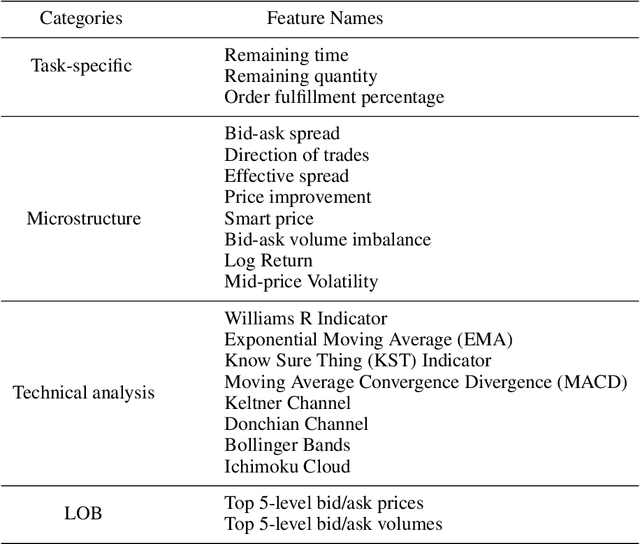
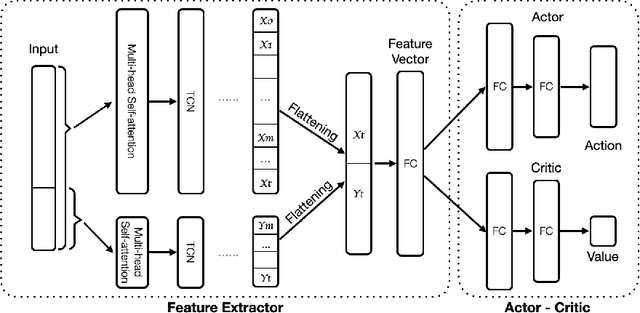
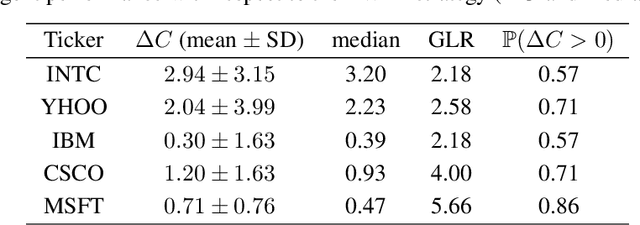
A novel framework for solving the optimal execution and placement problems using reinforcement learning (RL) with imitation was proposed. The RL agents trained from the proposed framework consistently outperformed the industry benchmark time-weighted average price (TWAP) strategy in execution cost and showed great generalization across out-of-sample trading dates and tickers. The impressive performance was achieved from three aspects. First, our RL network architecture called Dual-window Denoise PPO enabled efficient learning in a noisy market environment. Second, a reward scheme with imitation learning was designed, and a comprehensive set of market features was studied. Third, our flexible action formulation allowed the RL agent to tackle optimal execution and placement collectively resulting in better performance than solving individual problems separately. The RL agent's performance was evaluated in our multi-agent realistic historical limit order book simulator in which price impact was accurately assessed. In addition, ablation studies were also performed, confirming the superiority of our framework.
AutoShape: Real-Time Shape-Aware Monocular 3D Object Detection
Aug 25, 2021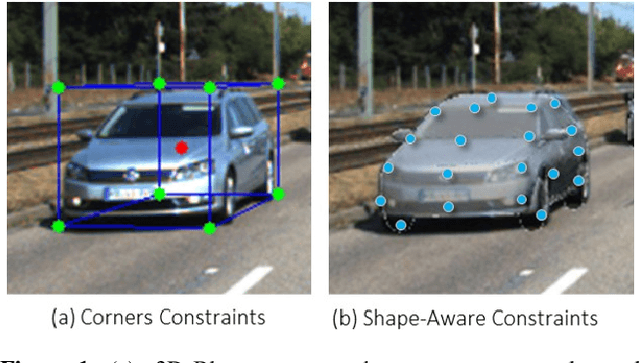
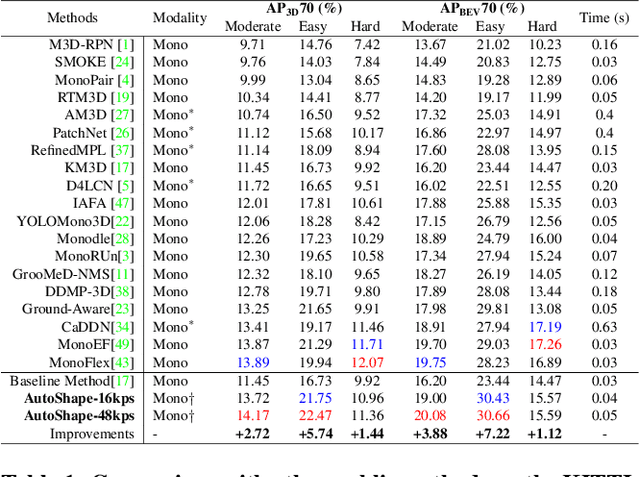
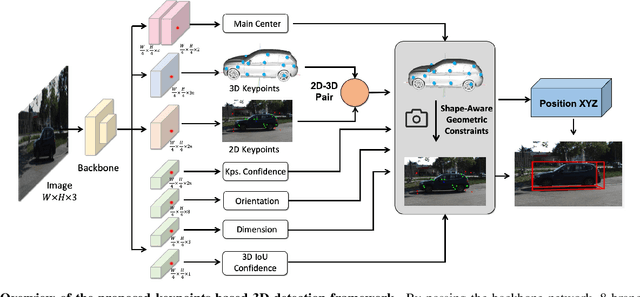
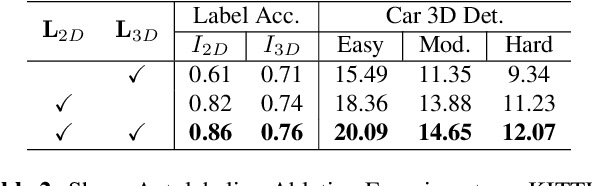
Existing deep learning-based approaches for monocular 3D object detection in autonomous driving often model the object as a rotated 3D cuboid while the object's geometric shape has been ignored. In this work, we propose an approach for incorporating the shape-aware 2D/3D constraints into the 3D detection framework. Specifically, we employ the deep neural network to learn distinguished 2D keypoints in the 2D image domain and regress their corresponding 3D coordinates in the local 3D object coordinate first. Then the 2D/3D geometric constraints are built by these correspondences for each object to boost the detection performance. For generating the ground truth of 2D/3D keypoints, an automatic model-fitting approach has been proposed by fitting the deformed 3D object model and the object mask in the 2D image. The proposed framework has been verified on the public KITTI dataset and the experimental results demonstrate that by using additional geometrical constraints the detection performance has been significantly improved as compared to the baseline method. More importantly, the proposed framework achieves state-of-the-art performance with real time. Data and code will be available at https://github.com/zongdai/AutoShape
FusionPainting: Multimodal Fusion with Adaptive Attention for 3D Object Detection
Jun 23, 2021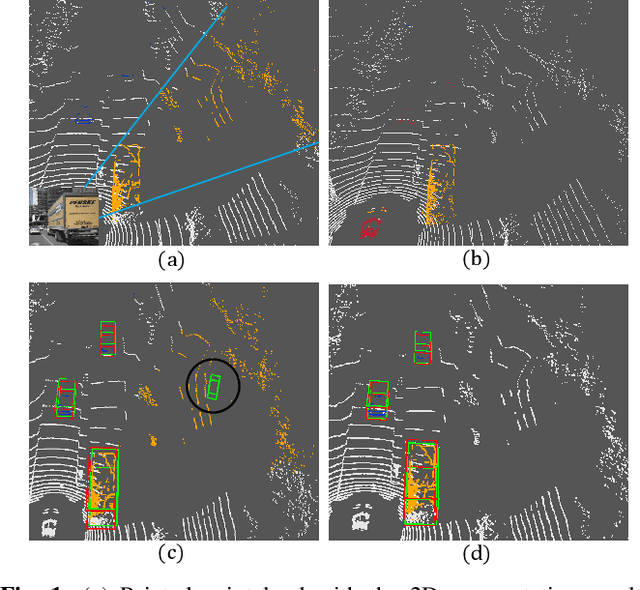
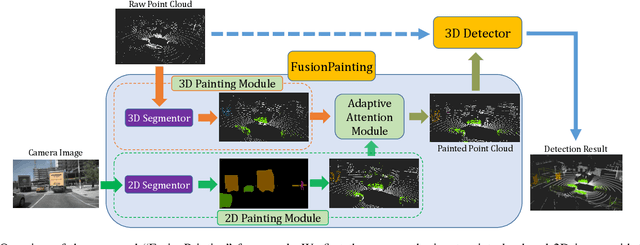
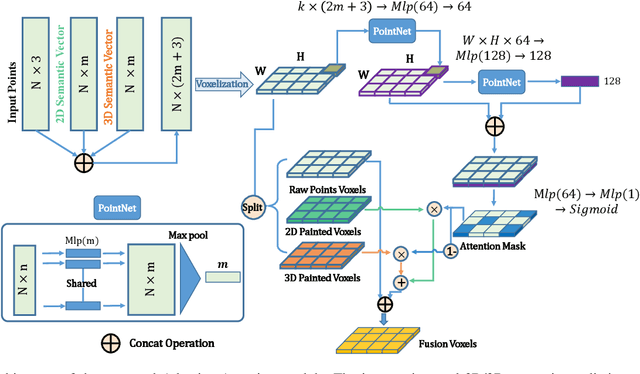
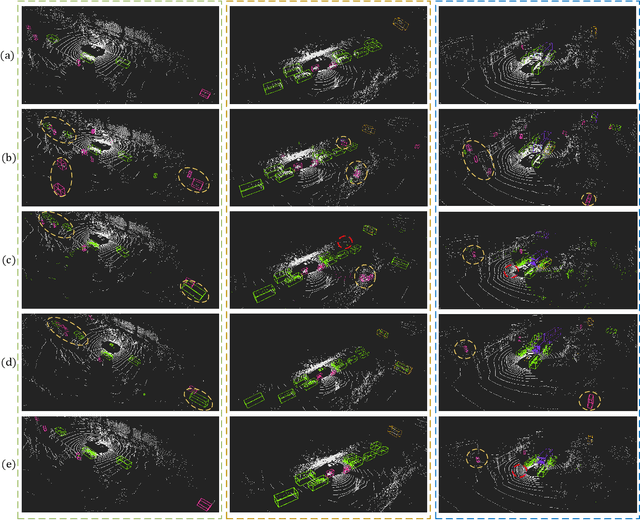
Accurate detection of obstacles in 3D is an essential task for autonomous driving and intelligent transportation. In this work, we propose a general multimodal fusion framework FusionPainting to fuse the 2D RGB image and 3D point clouds at a semantic level for boosting the 3D object detection task. Especially, the FusionPainting framework consists of three main modules: a multi-modal semantic segmentation module, an adaptive attention-based semantic fusion module, and a 3D object detector. First, semantic information is obtained for 2D images and 3D Lidar point clouds based on 2D and 3D segmentation approaches. Then the segmentation results from different sensors are adaptively fused based on the proposed attention-based semantic fusion module. Finally, the point clouds painted with the fused semantic label are sent to the 3D detector for obtaining the 3D objection results. The effectiveness of the proposed framework has been verified on the large-scale nuScenes detection benchmark by comparing it with three different baselines. The experimental results show that the fusion strategy can significantly improve the detection performance compared to the methods using only point clouds, and the methods using point clouds only painted with 2D segmentation information. Furthermore, the proposed approach outperforms other state-of-the-art methods on the nuScenes testing benchmark.
Invisible for both Camera and LiDAR: Security of Multi-Sensor Fusion based Perception in Autonomous Driving Under Physical-World Attacks
Jun 17, 2021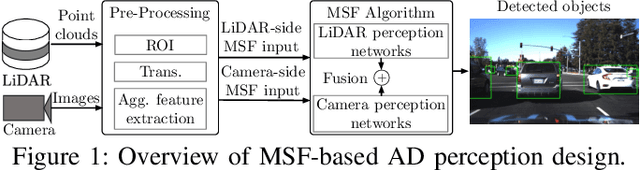

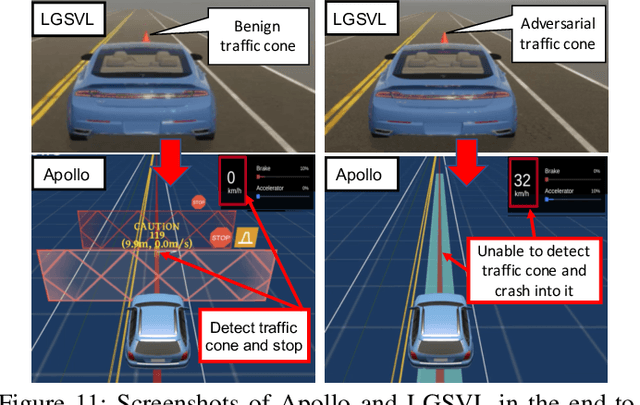

In Autonomous Driving (AD) systems, perception is both security and safety critical. Despite various prior studies on its security issues, all of them only consider attacks on camera- or LiDAR-based AD perception alone. However, production AD systems today predominantly adopt a Multi-Sensor Fusion (MSF) based design, which in principle can be more robust against these attacks under the assumption that not all fusion sources are (or can be) attacked at the same time. In this paper, we present the first study of security issues of MSF-based perception in AD systems. We directly challenge the basic MSF design assumption above by exploring the possibility of attacking all fusion sources simultaneously. This allows us for the first time to understand how much security guarantee MSF can fundamentally provide as a general defense strategy for AD perception. We formulate the attack as an optimization problem to generate a physically-realizable, adversarial 3D-printed object that misleads an AD system to fail in detecting it and thus crash into it. We propose a novel attack pipeline that addresses two main design challenges: (1) non-differentiable target camera and LiDAR sensing systems, and (2) non-differentiable cell-level aggregated features popularly used in LiDAR-based AD perception. We evaluate our attack on MSF included in representative open-source industry-grade AD systems in real-world driving scenarios. Our results show that the attack achieves over 90% success rate across different object types and MSF. Our attack is also found stealthy, robust to victim positions, transferable across MSF algorithms, and physical-world realizable after being 3D-printed and captured by LiDAR and camera devices. To concretely assess the end-to-end safety impact, we further perform simulation evaluation and show that it can cause a 100% vehicle collision rate for an industry-grade AD system.
Large Scale Autonomous Driving Scenarios Clustering with Self-supervised Feature Extraction
Mar 30, 2021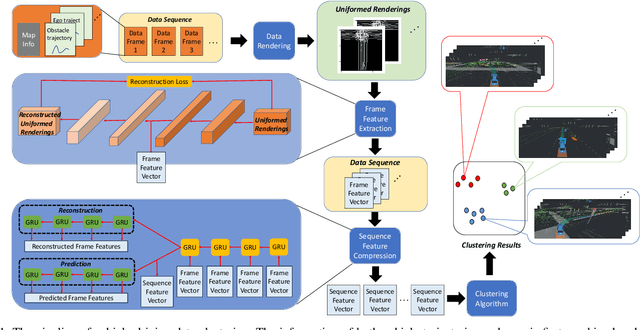
The clustering of autonomous driving scenario data can substantially benefit the autonomous driving validation and simulation systems by improving the simulation tests' completeness and fidelity. This article proposes a comprehensive data clustering framework for a large set of vehicle driving data. Existing algorithms utilize handcrafted features whose quality relies on the judgments of human experts. Additionally, the related feature compression methods are not scalable for a large data-set. Our approach thoroughly considers the traffic elements, including both in-traffic agent objects and map information. Meanwhile, we proposed a self-supervised deep learning approach for spatial and temporal feature extraction to avoid biased data representation. With the newly designed driving data clustering evaluation metrics based on data-augmentation, the accuracy assessment does not require a human-labeled data-set, which is subject to human bias. Via such unprejudiced evaluation metrics, we have shown our approach surpasses the existing methods that rely on handcrafted feature extractions.
MapFusion: A General Framework for 3D Object Detection with HDMaps
Mar 10, 2021
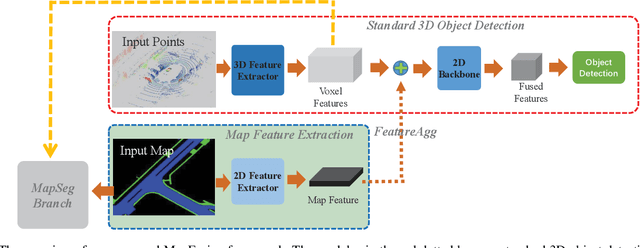
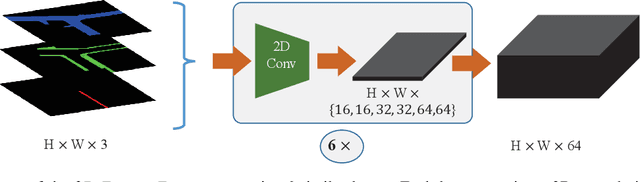
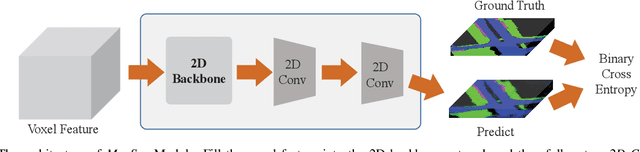
3D object detection is a key perception component in autonomous driving. Most recent approaches are based on Lidar sensors only or fused with cameras. Maps (e.g., High Definition Maps), a basic infrastructure for intelligent vehicles, however, have not been well exploited for boosting object detection tasks. In this paper, we propose a simple but effective framework - MapFusion to integrate the map information into modern 3D object detector pipelines. In particular, we design a FeatureAgg module for HD Map feature extraction and fusion, and a MapSeg module as an auxiliary segmentation head for the detection backbone. Our proposed MapFusion is detector independent and can be easily integrated into different detectors. The experimental results of three different baselines on large public autonomous driving dataset demonstrate the superiority of the proposed framework. By fusing the map information, we can achieve 1.27 to 2.79 points improvements for mean Average Precision (mAP) on three strong 3d object detection baselines.
IAFA: Instance-aware Feature Aggregation for 3D Object Detection from a Single Image
Mar 05, 2021
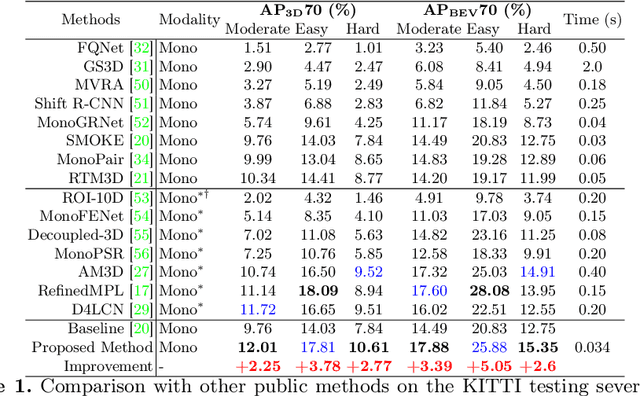
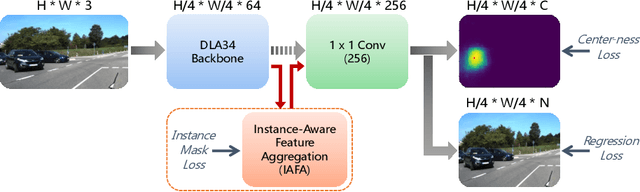
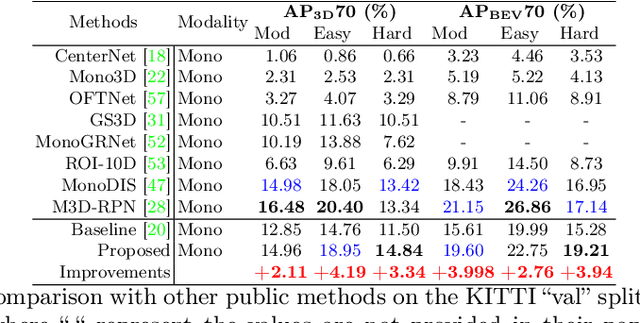
3D object detection from a single image is an important task in Autonomous Driving (AD), where various approaches have been proposed. However, the task is intrinsically ambiguous and challenging as single image depth estimation is already an ill-posed problem. In this paper, we propose an instance-aware approach to aggregate useful information for improving the accuracy of 3D object detection with the following contributions. First, an instance-aware feature aggregation (IAFA) module is proposed to collect local and global features for 3D bounding boxes regression. Second, we empirically find that the spatial attention module can be well learned by taking coarse-level instance annotations as a supervision signal. The proposed module has significantly boosted the performance of the baseline method on both 3D detection and 2D bird-eye's view of vehicle detection among all three categories. Third, our proposed method outperforms all single image-based approaches (even these methods trained with depth as auxiliary inputs) and achieves state-of-the-art 3D detection performance on the KITTI benchmark.
AutoRemover: Automatic Object Removal for Autonomous Driving Videos
Nov 28, 2019
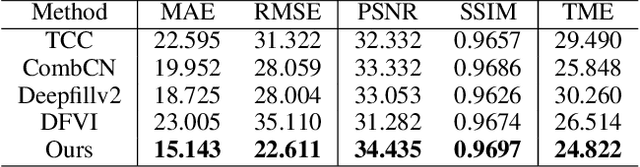
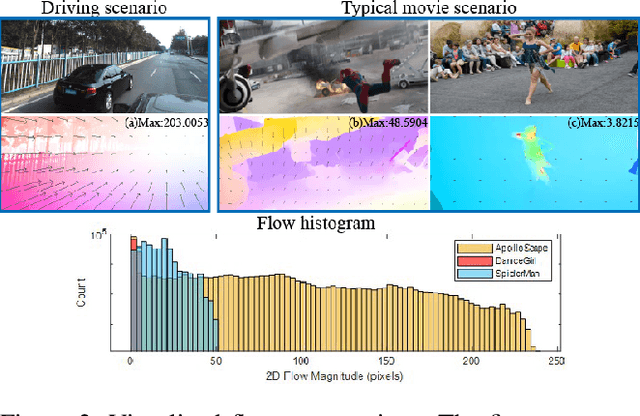
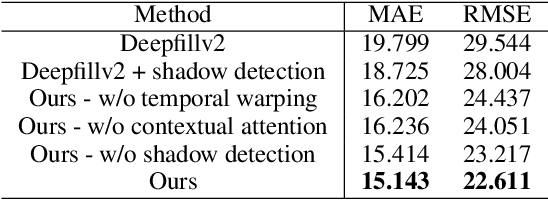
Motivated by the need for photo-realistic simulation in autonomous driving, in this paper we present a video inpainting algorithm \emph{AutoRemover}, designed specifically for generating street-view videos without any moving objects. In our setup we have two challenges: the first is the shadow, shadows are usually unlabeled but tightly coupled with the moving objects. The second is the large ego-motion in the videos. To deal with shadows, we build up an autonomous driving shadow dataset and design a deep neural network to detect shadows automatically. To deal with large ego-motion, we take advantage of the multi-source data, in particular the 3D data, in autonomous driving. More specifically, the geometric relationship between frames is incorporated into an inpainting deep neural network to produce high-quality structurally consistent video output. Experiments show that our method outperforms other state-of-the-art (SOTA) object removal algorithms, reducing the RMSE by over $19\%$.
IoU Loss for 2D/3D Object Detection
Aug 11, 2019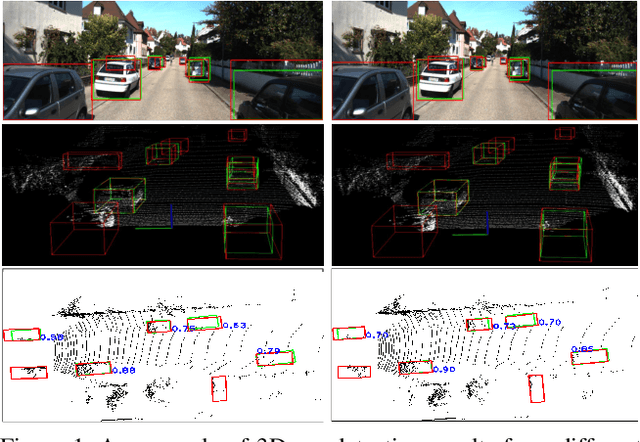

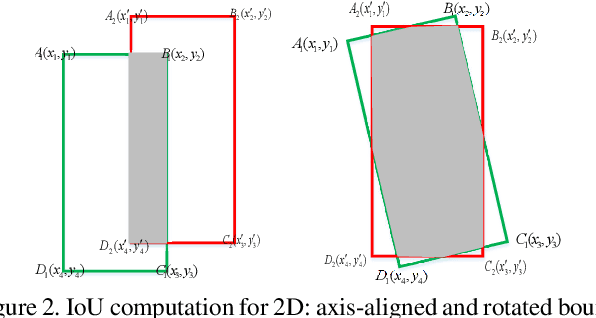
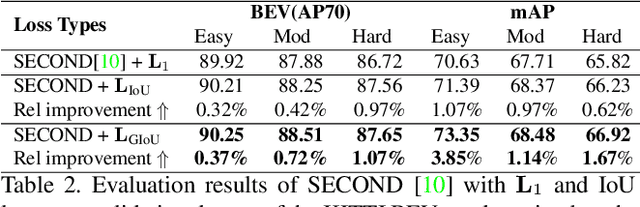
In 2D/3D object detection task, Intersection-over-Union (IoU) has been widely employed as an evaluation metric to evaluate the performance of different detectors in the testing stage. However, during the training stage, the common distance loss (\eg, $L_1$ or $L_2$) is often adopted as the loss function to minimize the discrepancy between the predicted and ground truth Bounding Box (Bbox). To eliminate the performance gap between training and testing, the IoU loss has been introduced for 2D object detection in \cite{yu2016unitbox} and \cite{rezatofighi2019generalized}. Unfortunately, all these approaches only work for axis-aligned 2D Bboxes, which cannot be applied for more general object detection task with rotated Bboxes. To resolve this issue, we investigate the IoU computation for two rotated Bboxes first and then implement a unified framework, IoU loss layer for both 2D and 3D object detection tasks. By integrating the implemented IoU loss into several state-of-the-art 3D object detectors, consistent improvements have been achieved for both bird-eye-view 2D detection and point cloud 3D detection on the public KITTI benchmark.