 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRiCS: A 2D Self-Occlusion Map for Harmonizing Volumetric Objects
May 14, 2022
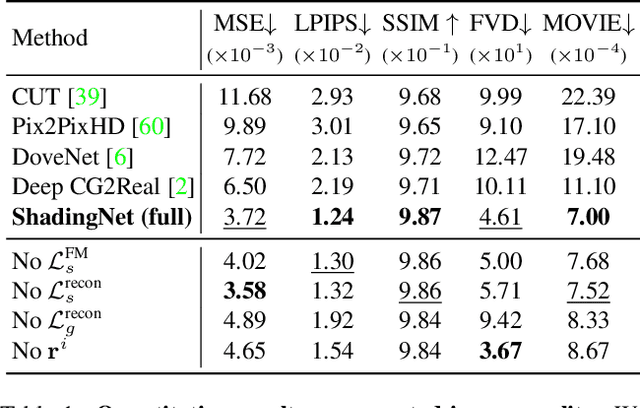
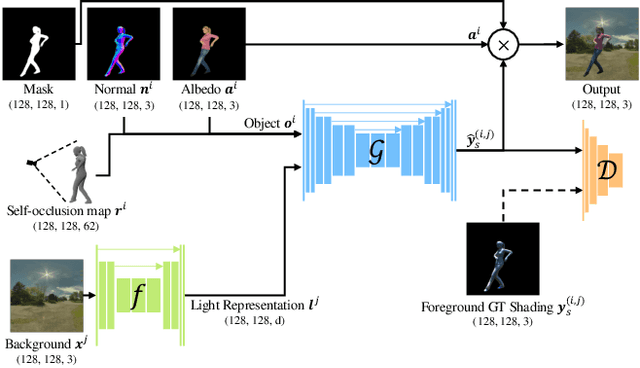
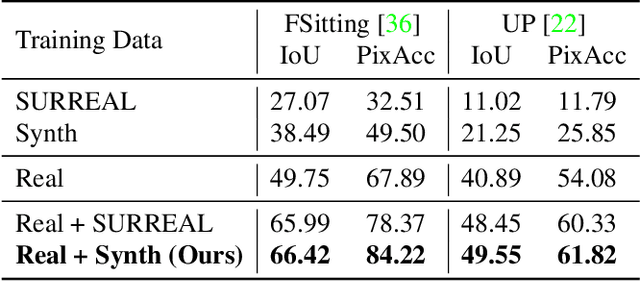
There have been remarkable successes in computer vision with deep learning. While such breakthroughs show robust performance, there have still been many challenges in learning in-depth knowledge, like occlusion or predicting physical interactions. Although some recent works show the potential of 3D data in serving such context, it is unclear how we efficiently provide 3D input to the 2D models due to the misalignment in dimensionality between 2D and 3D. To leverage the successes of 2D models in predicting self-occlusions, we design Ray-marching in Camera Space (RiCS), a new method to represent the self-occlusions of foreground objects in 3D into a 2D self-occlusion map. We test the effectiveness of our representation on the human image harmonization task by predicting shading that is coherent with a given background image. Our experiments demonstrate that our representation map not only allows us to enhance the image quality but also to model temporally coherent complex shadow effects compared with the simulation-to-real and harmonization methods, both quantitatively and qualitatively. We further show that we can significantly improve the performance of human parts segmentation networks trained on existing synthetic datasets by enhancing the harmonization quality with our method.
The Best of Both Worlds: Combining Model-based and Nonparametric Approaches for 3D Human Body Estimation
May 01, 2022

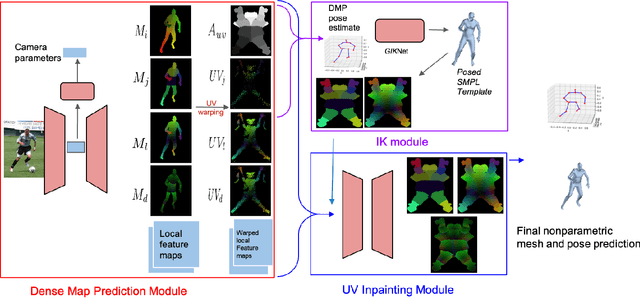
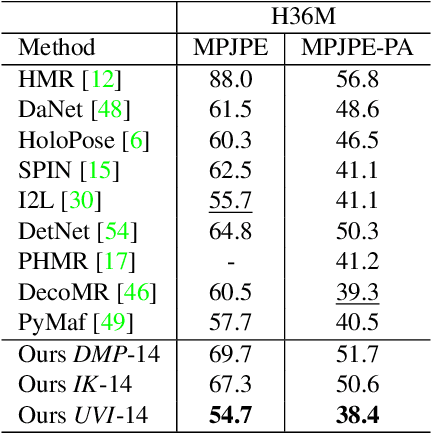
Nonparametric based methods have recently shown promising results in reconstructing human bodies from monocular images while model-based methods can help correct these estimates and improve prediction. However, estimating model parameters from global image features may lead to noticeable misalignment between the estimated meshes and image evidence. To address this issue and leverage the best of both worlds, we propose a framework of three consecutive modules. A dense map prediction module explicitly establishes the dense UV correspondence between the image evidence and each part of the body model. The inverse kinematics module refines the key point prediction and generates a posed template mesh. Finally, a UV inpainting module relies on the corresponding feature, prediction and the posed template, and completes the predictions of occluded body shape. Our framework leverages the best of non-parametric and model-based methods and is also robust to partial occlusion. Experiments demonstrate that our framework outperforms existing 3D human estimation methods on multiple public benchmarks.
Learning Motion-Dependent Appearance for High-Fidelity Rendering of Dynamic Humans from a Single Camera
Mar 24, 2022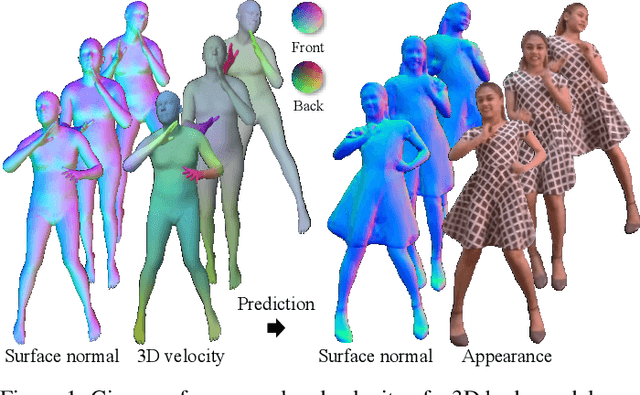

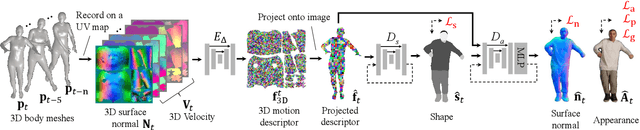

Appearance of dressed humans undergoes a complex geometric transformation induced not only by the static pose but also by its dynamics, i.e., there exists a number of cloth geometric configurations given a pose depending on the way it has moved. Such appearance modeling conditioned on motion has been largely neglected in existing human rendering methods, resulting in rendering of physically implausible motion. A key challenge of learning the dynamics of the appearance lies in the requirement of a prohibitively large amount of observations. In this paper, we present a compact motion representation by enforcing equivariance -- a representation is expected to be transformed in the way that the pose is transformed. We model an equivariant encoder that can generate the generalizable representation from the spatial and temporal derivatives of the 3D body surface. This learned representation is decoded by a compositional multi-task decoder that renders high fidelity time-varying appearance. Our experiments show that our method can generate a temporally coherent video of dynamic humans for unseen body poses and novel views given a single view video.
* CVPR accepted. 15 pages. 17 figures, 5 tables
Contact-Aware Retargeting of Skinned Motion
Sep 15, 2021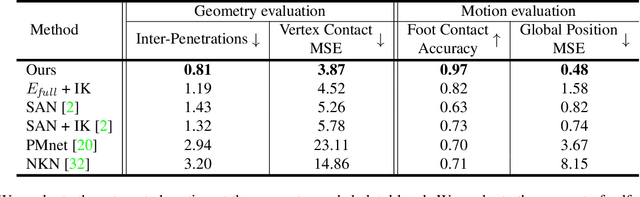
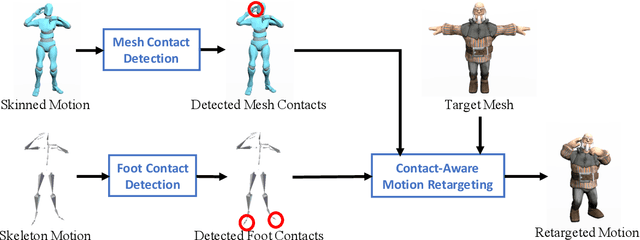

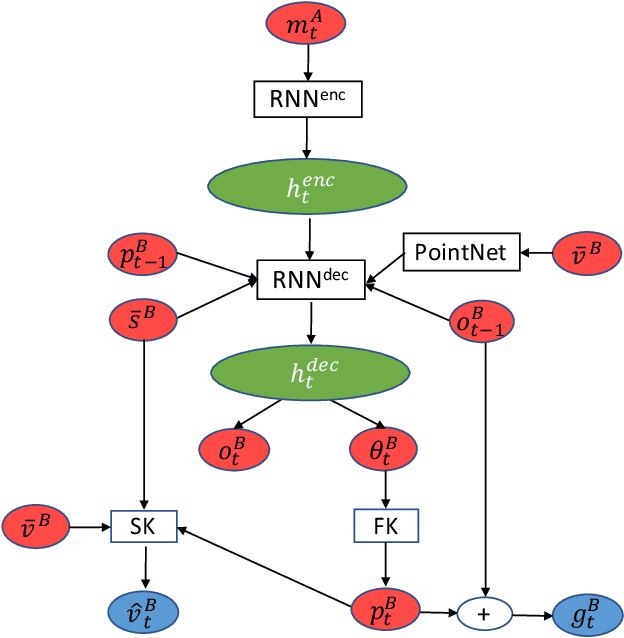
This paper introduces a motion retargeting method that preserves self-contacts and prevents interpenetration. Self-contacts, such as when hands touch each other or the torso or the head, are important attributes of human body language and dynamics, yet existing methods do not model or preserve these contacts. Likewise, interpenetration, such as a hand passing into the torso, are a typical artifact of motion estimation methods. The input to our method is a human motion sequence and a target skeleton and character geometry. The method identifies self-contacts and ground contacts in the input motion, and optimizes the motion to apply to the output skeleton, while preserving these contacts and reducing interpenetration. We introduce a novel geometry-conditioned recurrent network with an encoder-space optimization strategy that achieves efficient retargeting while satisfying contact constraints. In experiments, our results quantitatively outperform previous methods and we conduct a user study where our retargeted motions are rated as higher-quality than those produced by recent works. We also show our method generalizes to motion estimated from human videos where we improve over previous works that produce noticeable interpenetration.
Pose with Style: Detail-Preserving Pose-Guided Image Synthesis with Conditional StyleGAN
Sep 13, 2021
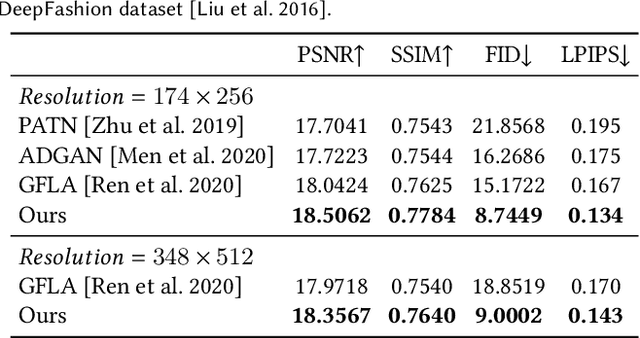


We present an algorithm for re-rendering a person from a single image under arbitrary poses. Existing methods often have difficulties in hallucinating occluded contents photo-realistically while preserving the identity and fine details in the source image. We first learn to inpaint the correspondence field between the body surface texture and the source image with a human body symmetry prior. The inpainted correspondence field allows us to transfer/warp local features extracted from the source to the target view even under large pose changes. Directly mapping the warped local features to an RGB image using a simple CNN decoder often leads to visible artifacts. Thus, we extend the StyleGAN generator so that it takes pose as input (for controlling poses) and introduces a spatially varying modulation for the latent space using the warped local features (for controlling appearances). We show that our method compares favorably against the state-of-the-art algorithms in both quantitative evaluation and visual comparison.
Stochastic Scene-Aware Motion Prediction
Aug 18, 2021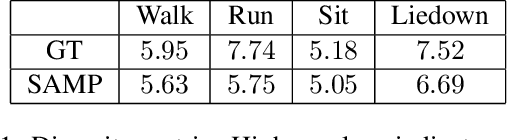

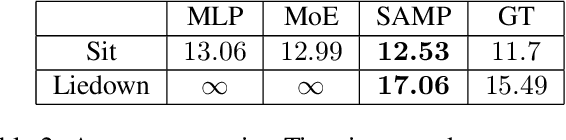

A long-standing goal in computer vision is to capture, model, and realistically synthesize human behavior. Specifically, by learning from data, our goal is to enable virtual humans to navigate within cluttered indoor scenes and naturally interact with objects. Such embodied behavior has applications in virtual reality, computer games, and robotics, while synthesized behavior can be used as a source of training data. This is challenging because real human motion is diverse and adapts to the scene. For example, a person can sit or lie on a sofa in many places and with varying styles. It is necessary to model this diversity when synthesizing virtual humans that realistically perform human-scene interactions. We present a novel data-driven, stochastic motion synthesis method that models different styles of performing a given action with a target object. Our method, called SAMP, for Scene-Aware Motion Prediction, generalizes to target objects of various geometries while enabling the character to navigate in cluttered scenes. To train our method, we collected MoCap data covering various sitting, lying down, walking, and running styles. We demonstrate our method on complex indoor scenes and achieve superior performance compared to existing solutions. Our code and data are available for research at https://samp.is.tue.mpg.de.
Single-image Full-body Human Relighting
Jul 15, 2021


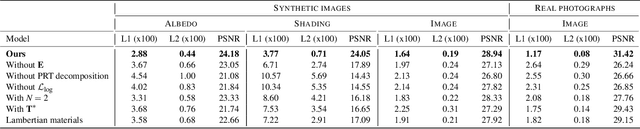
We present a single-image data-driven method to automatically relight images with full-body humans in them. Our framework is based on a realistic scene decomposition leveraging precomputed radiance transfer (PRT) and spherical harmonics (SH) lighting. In contrast to previous work, we lift the assumptions on Lambertian materials and explicitly model diffuse and specular reflectance in our data. Moreover, we introduce an additional light-dependent residual term that accounts for errors in the PRT-based image reconstruction. We propose a new deep learning architecture, tailored to the decomposition performed in PRT, that is trained using a combination of L1, logarithmic, and rendering losses. Our model outperforms the state of the art for full-body human relighting both with synthetic images and photographs.
* 11 pages, 12 figures
Task-Generic Hierarchical Human Motion Prior using VAEs
Jun 07, 2021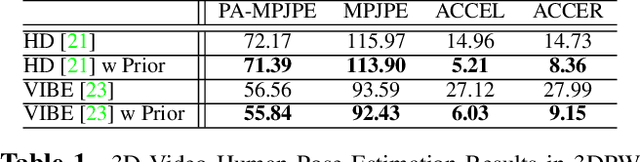
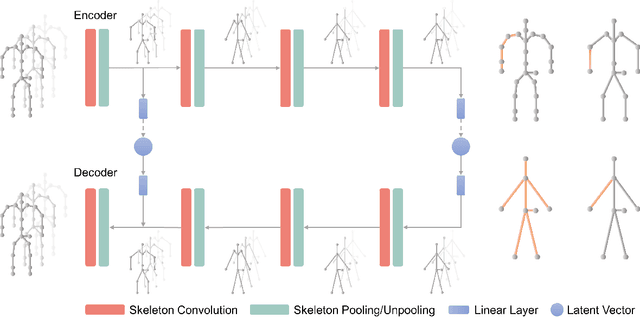
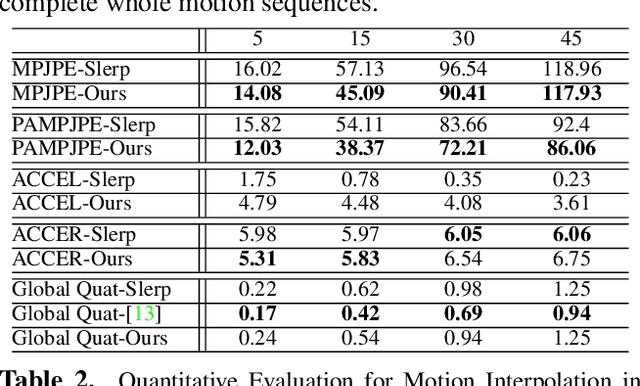
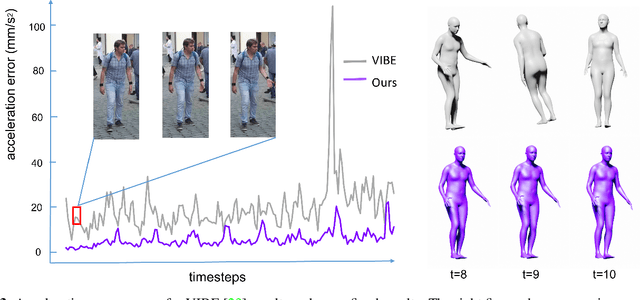
A deep generative model that describes human motions can benefit a wide range of fundamental computer vision and graphics tasks, such as providing robustness to video-based human pose estimation, predicting complete body movements for motion capture systems during occlusions, and assisting key frame animation with plausible movements. In this paper, we present a method for learning complex human motions independent of specific tasks using a combined global and local latent space to facilitate coarse and fine-grained modeling. Specifically, we propose a hierarchical motion variational autoencoder (HM-VAE) that consists of a 2-level hierarchical latent space. While the global latent space captures the overall global body motion, the local latent space enables to capture the refined poses of the different body parts. We demonstrate the effectiveness of our hierarchical motion variational autoencoder in a variety of tasks including video-based human pose estimation, motion completion from partial observations, and motion synthesis from sparse key-frames. Even though, our model has not been trained for any of these tasks specifically, it provides superior performance than task-specific alternatives. Our general-purpose human motion prior model can fix corrupted human body animations and generate complete movements from incomplete observations.
HuMoR: 3D Human Motion Model for Robust Pose Estimation
May 10, 2021



We introduce HuMoR: a 3D Human Motion Model for Robust Estimation of temporal pose and shape. Though substantial progress has been made in estimating 3D human motion and shape from dynamic observations, recovering plausible pose sequences in the presence of noise and occlusions remains a challenge. For this purpose, we propose an expressive generative model in the form of a conditional variational autoencoder, which learns a distribution of the change in pose at each step of a motion sequence. Furthermore, we introduce a flexible optimization-based approach that leverages HuMoR as a motion prior to robustly estimate plausible pose and shape from ambiguous observations. Through extensive evaluations, we demonstrate that our model generalizes to diverse motions and body shapes after training on a large motion capture dataset, and enables motion reconstruction from multiple input modalities including 3D keypoints and RGB(-D) videos.
Attribute-conditioned Layout GAN for Automatic Graphic Design
Sep 11, 2020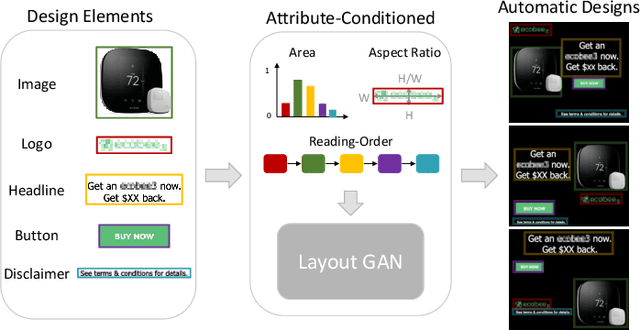
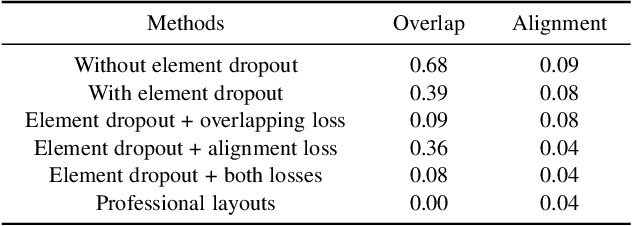
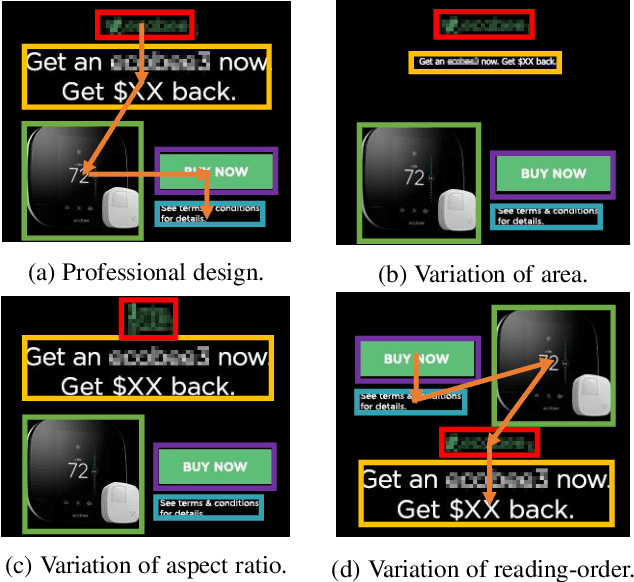
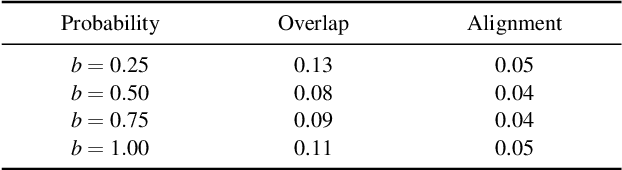
Modeling layout is an important first step for graphic design. Recently, methods for generating graphic layouts have progressed, particularly with Generative Adversarial Networks (GANs). However, the problem of specifying the locations and sizes of design elements usually involves constraints with respect to element attributes, such as area, aspect ratio and reading-order. Automating attribute conditional graphic layouts remains a complex and unsolved problem. In this paper, we introduce Attribute-conditioned Layout GAN to incorporate the attributes of design elements for graphic layout generation by forcing both the generator and the discriminator to meet attribute conditions. Due to the complexity of graphic designs, we further propose an element dropout method to make the discriminator look at partial lists of elements and learn their local patterns. In addition, we introduce various loss designs following different design principles for layout optimization. We demonstrate that the proposed method can synthesize graphic layouts conditioned on different element attributes. It can also adjust well-designed layouts to new sizes while retaining elements' original reading-orders. The effectiveness of our method is validated through a user study.