 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet Storytelling Tell Vivid Stories: An Expressive and Fluent Multimodal Storyteller
Mar 12, 2024



Storytelling aims to generate reasonable and vivid narratives based on an ordered image stream. The fidelity to the image story theme and the divergence of story plots attract readers to keep reading. Previous works iteratively improved the alignment of multiple modalities but ultimately resulted in the generation of simplistic storylines for image streams. In this work, we propose a new pipeline, termed LLaMS, to generate multimodal human-level stories that are embodied in expressiveness and consistency. Specifically, by fully exploiting the commonsense knowledge within the LLM, we first employ a sequence data auto-enhancement strategy to enhance factual content expression and leverage a textual reasoning architecture for expressive story generation and prediction. Secondly, we propose SQ-Adatpter module for story illustration generation which can maintain sequence consistency. Numerical results are conducted through human evaluation to verify the superiority of proposed LLaMS. Evaluations show that LLaMS achieves state-of-the-art storytelling performance and 86% correlation and 100% consistency win rate as compared with previous SOTA methods. Furthermore, ablation experiments are conducted to verify the effectiveness of proposed sequence data enhancement and SQ-Adapter.
Do You Live a Healthy Life? Analyzing Lifestyle by Visual Life Logging
Nov 24, 2020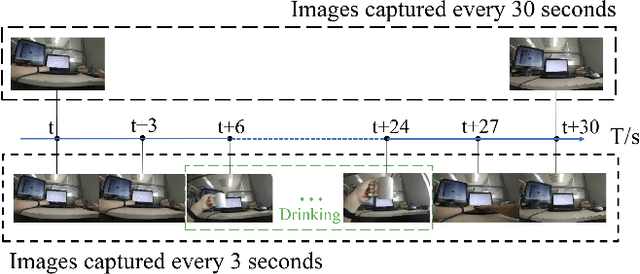

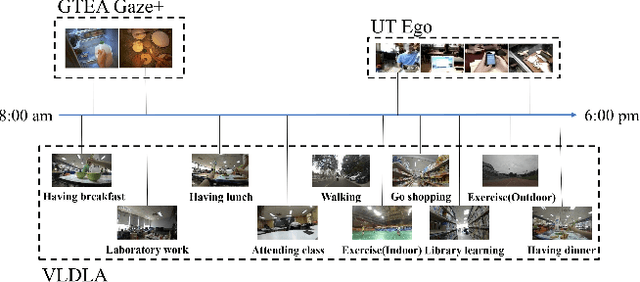

A healthy lifestyle is the key to better health and happiness and has a considerable effect on quality of life and disease prevention. Current lifelogging/egocentric datasets are not suitable for lifestyle analysis; consequently, there is no research on lifestyle analysis in the field of computer vision. In this work, we investigate the problem of lifestyle analysis and build a visual lifelogging dataset for lifestyle analysis (VLDLA). The VLDLA contains images captured by a wearable camera every 3 seconds from 8:00 am to 6:00 pm for seven days. In contrast to current lifelogging/egocentric datasets, our dataset is suitable for lifestyle analysis as images are taken with short intervals to capture activities of short duration; moreover, images are taken continuously from morning to evening to record all the activities performed by a user. Based on our dataset, we classify the user activities in each frame and use three latent fluents of the user, which change over time and are associated with activities, to measure the healthy degree of the user's lifestyle. The scores for the three latent fluents are computed based on recognized activities, and the healthy degree of the lifestyle for the day is determined based on the scores for the latent fluents. Experimental results show that our method can be used to analyze the healthiness of users' lifestyles.
Stitching Videos from a Fisheye Lens Camera and a Wide-Angle Lens Camera for Telepresence Robots
Mar 15, 2019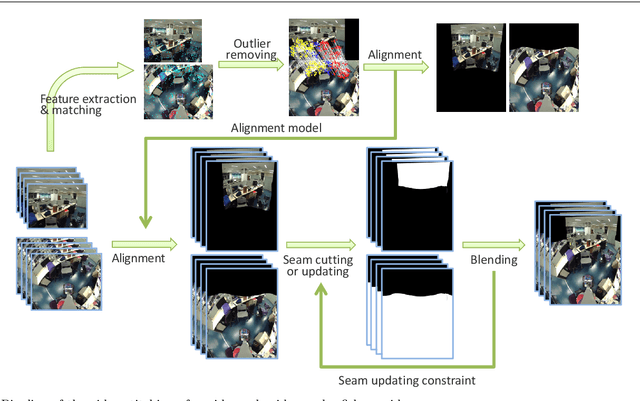
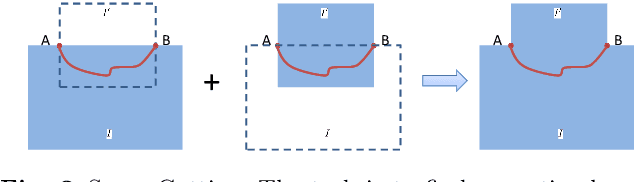

Many telepresence robots are equipped with a forward-facing camera for video communication and a downward-facing camera for navigation. In this paper, we propose to stitch videos from the FF-camera with a wide-angle lens and the DF-camera with a fisheye lens for telepresence robots. We aim at providing more compact and efficient visual feedback for the user interface of telepresence robots with user-friendly interactive experiences. To this end, we present a multi-homography-based video stitching method which stitches videos from a wide-angle camera and a fisheye camera. The method consists of video image alignment, seam cutting, and image blending. We directly align the wide-angle video image and the fisheye video image based on the multi-homography alignment without calibration, distortion correction, and unwarping procedures. Thus, we can obtain a stitched video with shape preservation in the non-overlapping regions and alignment in the overlapping area for telepresence. To alleviate ghosting effects caused by moving objects and/or moving cameras during telepresence robot driving, an optimal seam is found for aligned video composition, and the optimal seam will be updated in subsequent frames, considering spatial and temporal coherence. The final stitched video is created by image blending based on the optimal seam. We conducted a user study to demonstrate the effectiveness of our method and the superiority of telepresence robots with a stitched video as visual feedback.
Face Liveness Detection Based on Client Identity Using Siamese Network
Mar 13, 2019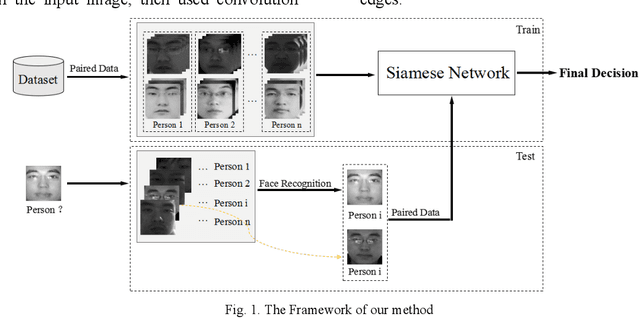
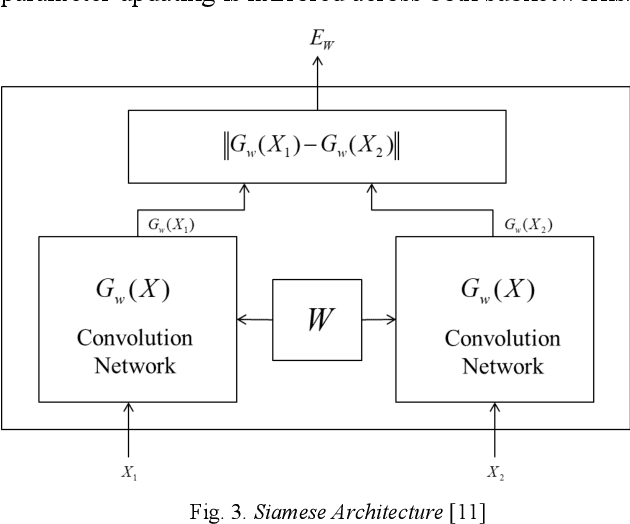
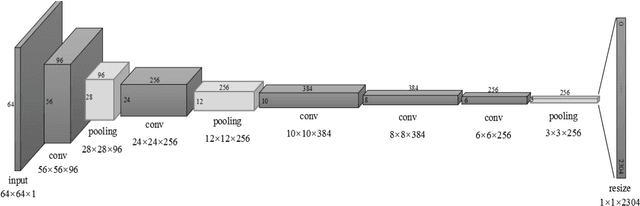

Face liveness detection is an essential prerequisite for face recognition applications. Previous face liveness detection methods usually train a binary classifier to differentiate between a fake face and a real face before face recognition. The client identity information is not utilized in previous face liveness detection methods. However, in practical face recognition applications, face spoofing attacks are always aimed at a specific client, and the client identity information can provide useful clues for face liveness detection. In this paper, we propose a face liveness detection method based on the client identity using Siamese network. We detect face liveness after face recognition instead of before face recognition, that is, we detect face liveness with the client identity information. We train a Siamese network with image pairs. Each image pair consists of two real face images or one real and one fake face images. The face images in each pair come from a same client. Given a test face image, the face image is firstly recognized by face recognition system, then the real face image of the identified client is retrieved to help the face liveness detection. Experiment results demonstrate the effectiveness of our method.
A Low-Cost Tele-Presence Wheelchair System
Aug 23, 2016
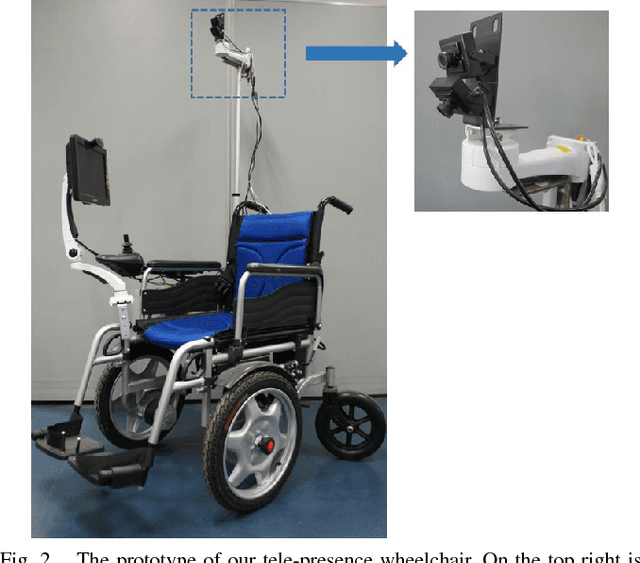
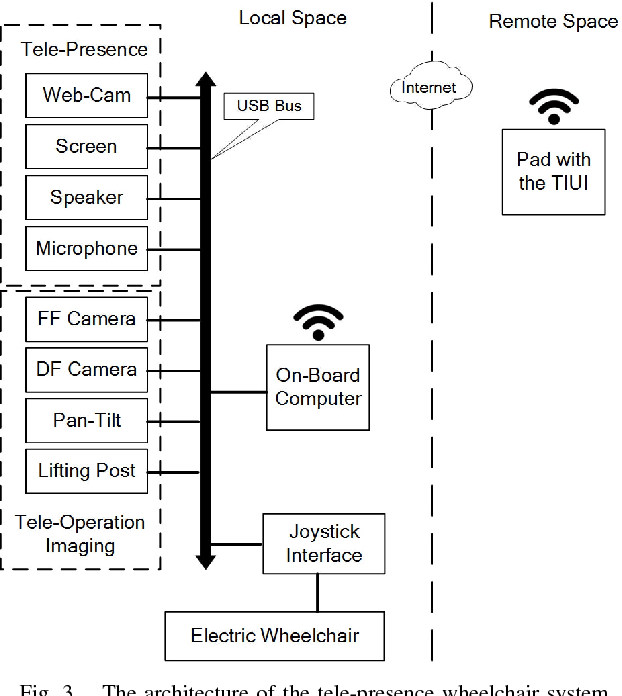

This paper presents the architecture and implementation of a tele-presence wheelchair system based on tele-presence robot, intelligent wheelchair, and touch screen technologies. The tele-presence wheelchair system consists of a commercial electric wheelchair, an add-on tele-presence interaction module, and a touchable live video image based user interface (called TIUI). The tele-presence interaction module is used to provide video-chatting for an elderly or disabled person with the family members or caregivers, and also captures the live video of an environment for tele-operation and semi-autonomous navigation. The user interface developed in our lab allows an operator to access the system anywhere and directly touch the live video image of the wheelchair to push it as if he/she did it in the presence. This paper also discusses the evaluation of the user experience.
Input Aggregated Network for Face Video Representation
Mar 22, 2016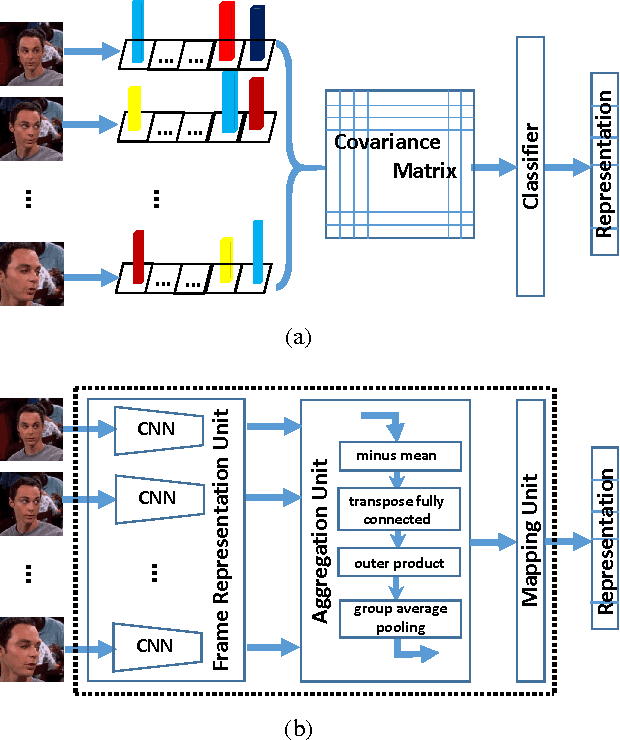

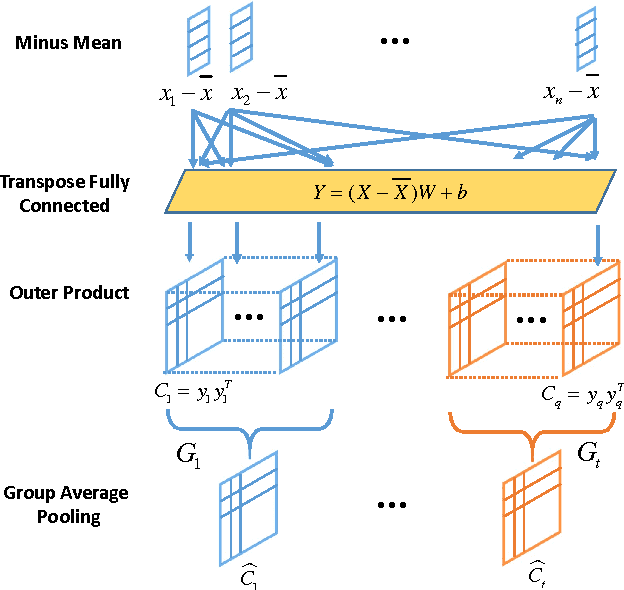
Recently, deep neural network has shown promising performance in face image recognition. The inputs of most networks are face images, and there is hardly any work reported in literature on network with face videos as input. To sufficiently discover the useful information contained in face videos, we present a novel network architecture called input aggregated network which is able to learn fixed-length representations for variable-length face videos. To accomplish this goal, an aggregation unit is designed to model a face video with various frames as a point on a Riemannian manifold, and the mapping unit aims at mapping the point into high-dimensional space where face videos belonging to the same subject are close-by and others are distant. These two units together with the frame representation unit build an end-to-end learning system which can learn representations of face videos for the specific tasks. Experiments on two public face video datasets demonstrate the effectiveness of the proposed network.