 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tutorial on Gaussian Process Learning-based Model Predictive Control
Apr 02, 2024



This tutorial provides a systematic introduction to Gaussian process learning-based model predictive control (GP-MPC), an advanced approach integrating Gaussian process (GP) with model predictive control (MPC) for enhanced control in complex systems. It begins with GP regression fundamentals, illustrating how it enriches MPC with enhanced predictive accuracy and robust handling of uncertainties. A central contribution of this tutorial is the first detailed, systematic mathematical formulation of GP-MPC in literature, focusing on deriving the approximation of means and variances propagation for GP multi-step predictions. Practical applications in robotics control, such as path-following for mobile robots in challenging terrains and mixed-vehicle platooning, are discussed to demonstrate the real-world effectiveness and adaptability of GP-MPC. This tutorial aims to make GP-MPC accessible to researchers and practitioners, enriching the learning-based control field with in-depth theoretical and practical insights and fostering further innovations in complex system control.
Reinforcement Learning-based Recommender Systems with Large Language Models for State Reward and Action Modeling
Mar 25, 2024Reinforcement Learning (RL)-based recommender systems have demonstrated promising performance in meeting user expectations by learning to make accurate next-item recommendations from historical user-item interactions. However, existing offline RL-based sequential recommendation methods face the challenge of obtaining effective user feedback from the environment. Effectively modeling the user state and shaping an appropriate reward for recommendation remains a challenge. In this paper, we leverage language understanding capabilities and adapt large language models (LLMs) as an environment (LE) to enhance RL-based recommenders. The LE is learned from a subset of user-item interaction data, thus reducing the need for large training data, and can synthesise user feedback for offline data by: (i) acting as a state model that produces high quality states that enrich the user representation, and (ii) functioning as a reward model to accurately capture nuanced user preferences on actions. Moreover, the LE allows to generate positive actions that augment the limited offline training data. We propose a LE Augmentation (LEA) method to further improve recommendation performance by optimising jointly the supervised component and the RL policy, using the augmented actions and historical user signals. We use LEA, the state and reward models in conjunction with state-of-the-art RL recommenders and report experimental results on two publicly available datasets.
Non-Convex Robust Hypothesis Testing using Sinkhorn Uncertainty Sets
Mar 21, 2024



We present a new framework to address the non-convex robust hypothesis testing problem, wherein the goal is to seek the optimal detector that minimizes the maximum of worst-case type-I and type-II risk functions. The distributional uncertainty sets are constructed to center around the empirical distribution derived from samples based on Sinkhorn discrepancy. Given that the objective involves non-convex, non-smooth probabilistic functions that are often intractable to optimize, existing methods resort to approximations rather than exact solutions. To tackle the challenge, we introduce an exact mixed-integer exponential conic reformulation of the problem, which can be solved into a global optimum with a moderate amount of input data. Subsequently, we propose a convex approximation, demonstrating its superiority over current state-of-the-art methodologies in literature. Furthermore, we establish connections between robust hypothesis testing and regularized formulations of non-robust risk functions, offering insightful interpretations. Our numerical study highlights the satisfactory testing performance and computational efficiency of the proposed framework.
PipeRAG: Fast Retrieval-Augmented Generation via Algorithm-System Co-design
Mar 08, 2024



Retrieval-augmented generation (RAG) can enhance the generation quality of large language models (LLMs) by incorporating external token databases. However, retrievals from large databases can constitute a substantial portion of the overall generation time, particularly when retrievals are periodically performed to align the retrieved content with the latest states of generation. In this paper, we introduce PipeRAG, a novel algorithm-system co-design approach to reduce generation latency and enhance generation quality. PipeRAG integrates (1) pipeline parallelism to enable concurrent retrieval and generation processes, (2) flexible retrieval intervals to maximize the efficiency of pipeline parallelism, and (3) a performance model to automatically balance retrieval quality and latency based on the generation states and underlying hardware. Our evaluation shows that, by combining the three aforementioned methods, PipeRAG achieves up to 2.6$\times$ speedup in end-to-end generation latency while improving generation quality. These promising results showcase the effectiveness of co-designing algorithms with underlying systems, paving the way for the adoption of PipeRAG in future RAG systems.
OSSAR: Towards Open-Set Surgical Activity Recognition in Robot-assisted Surgery
Feb 10, 2024



In the realm of automated robotic surgery and computer-assisted interventions, understanding robotic surgical activities stands paramount. Existing algorithms dedicated to surgical activity recognition predominantly cater to pre-defined closed-set paradigms, ignoring the challenges of real-world open-set scenarios. Such algorithms often falter in the presence of test samples originating from classes unseen during training phases. To tackle this problem, we introduce an innovative Open-Set Surgical Activity Recognition (OSSAR) framework. Our solution leverages the hyperspherical reciprocal point strategy to enhance the distinction between known and unknown classes in the feature space. Additionally, we address the issue of over-confidence in the closed set by refining model calibration, avoiding misclassification of unknown classes as known ones. To support our assertions, we establish an open-set surgical activity benchmark utilizing the public JIGSAWS dataset. Besides, we also collect a novel dataset on endoscopic submucosal dissection for surgical activity tasks. Extensive comparisons and ablation experiments on these datasets demonstrate the significant outperformance of our method over existing state-of-the-art approaches. Our proposed solution can effectively address the challenges of real-world surgical scenarios. Our code is publicly accessible at https://github.com/longbai1006/OSSAR.
Accelerating PDE Data Generation via Differential Operator Action in Solution Space
Feb 04, 2024



Recent advancements in data-driven approaches, such as Neural Operator (NO), have demonstrated their effectiveness in reducing the solving time of Partial Differential Equations (PDEs). However, one major challenge faced by these approaches is the requirement for a large amount of high-precision training data, which needs significant computational costs during the generation process. To address this challenge, we propose a novel PDE dataset generation algorithm, namely Differential Operator Action in Solution space (DiffOAS), which speeds up the data generation process and enhances the precision of the generated data simultaneously. Specifically, DiffOAS obtains a few basic PDE solutions and then combines them to get solutions. It applies differential operators on these solutions, a process we call 'operator action', to efficiently generate precise PDE data points. Theoretical analysis shows that the time complexity of DiffOAS method is one order lower than the existing generation method. Experimental results show that DiffOAS accelerates the generation of large-scale datasets with 10,000 instances by 300 times. Even with just 5% of the generation time, NO trained on the data generated by DiffOAS exhibits comparable performance to that using the existing generation method, which highlights the efficiency of DiffOAS.
Learning to Stop Cut Generation for Efficient Mixed-Integer Linear Programming
Feb 02, 2024



Cutting planes (cuts) play an important role in solving mixed-integer linear programs (MILPs), as they significantly tighten the dual bounds and improve the solving performance. A key problem for cuts is when to stop cuts generation, which is important for the efficiency of solving MILPs. However, many modern MILP solvers employ hard-coded heuristics to tackle this problem, which tends to neglect underlying patterns among MILPs from certain applications. To address this challenge, we formulate the cuts generation stopping problem as a reinforcement learning problem and propose a novel hybrid graph representation model (HYGRO) to learn effective stopping strategies. An appealing feature of HYGRO is that it can effectively capture both the dynamic and static features of MILPs, enabling dynamic decision-making for the stopping strategies. To the best of our knowledge, HYGRO is the first data-driven method to tackle the cuts generation stopping problem. By integrating our approach with modern solvers, experiments demonstrate that HYGRO significantly improves the efficiency of solving MILPs compared to competitive baselines, achieving up to 31% improvement.
PointGL: A Simple Global-Local Framework for Efficient Point Cloud Analysis
Jan 22, 2024Efficient analysis of point clouds holds paramount significance in real-world 3D applications. Currently, prevailing point-based models adhere to the PointNet++ methodology, which involves embedding and abstracting point features within a sequence of spatially overlapping local point sets, resulting in noticeable computational redundancy. Drawing inspiration from the streamlined paradigm of pixel embedding followed by regional pooling in Convolutional Neural Networks (CNNs), we introduce a novel, uncomplicated yet potent architecture known as PointGL, crafted to facilitate efficient point cloud analysis. PointGL employs a hierarchical process of feature acquisition through two recursive steps. First, the Global Point Embedding leverages straightforward residual Multilayer Perceptrons (MLPs) to effectuate feature embedding for each individual point. Second, the novel Local Graph Pooling technique characterizes point-to-point relationships and abstracts regional representations through succinct local graphs. The harmonious fusion of one-time point embedding and parameter-free graph pooling contributes to PointGL's defining attributes of minimized model complexity and heightened efficiency. Our PointGL attains state-of-the-art accuracy on the ScanObjectNN dataset while exhibiting a runtime that is more than 5 times faster and utilizing only approximately 4% of the FLOPs and 30% of the parameters compared to the recent PointMLP model. The code for PointGL is available at https://github.com/Roywangj/PointGL.
Accelerating Data Generation for Neural Operators via Krylov Subspace Recycling
Jan 17, 2024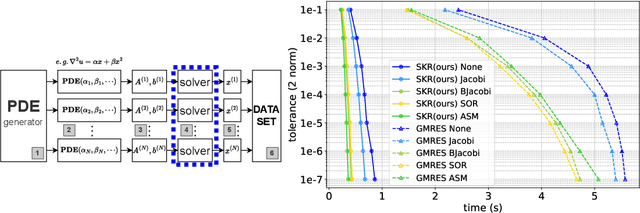

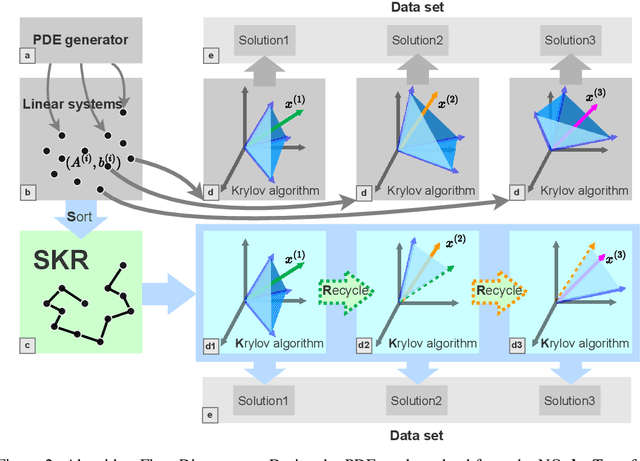
Learning neural operators for solving partial differential equations (PDEs) has attracted great attention due to its high inference efficiency. However, training such operators requires generating a substantial amount of labeled data, i.e., PDE problems together with their solutions. The data generation process is exceptionally time-consuming, as it involves solving numerous systems of linear equations to obtain numerical solutions to the PDEs. Many existing methods solve these systems independently without considering their inherent similarities, resulting in extremely redundant computations. To tackle this problem, we propose a novel method, namely Sorting Krylov Recycling (SKR), to boost the efficiency of solving these systems, thus significantly accelerating data generation for neural operators training. To the best of our knowledge, SKR is the first attempt to address the time-consuming nature of data generation for learning neural operators. The working horse of SKR is Krylov subspace recycling, a powerful technique for solving a series of interrelated systems by leveraging their inherent similarities. Specifically, SKR employs a sorting algorithm to arrange these systems in a sequence, where adjacent systems exhibit high similarities. Then it equips a solver with Krylov subspace recycling to solve the systems sequentially instead of independently, thus effectively enhancing the solving efficiency. Both theoretical analysis and extensive experiments demonstrate that SKR can significantly accelerate neural operator data generation, achieving a remarkable speedup of up to 13.9 times.
Machine Learning Insides OptVerse AI Solver: Design Principles and Applications
Jan 17, 2024



In an era of digital ubiquity, efficient resource management and decision-making are paramount across numerous industries. To this end, we present a comprehensive study on the integration of machine learning (ML) techniques into Huawei Cloud's OptVerse AI Solver, which aims to mitigate the scarcity of real-world mathematical programming instances, and to surpass the capabilities of traditional optimization techniques. We showcase our methods for generating complex SAT and MILP instances utilizing generative models that mirror multifaceted structures of real-world problem. Furthermore, we introduce a training framework leveraging augmentation policies to maintain solvers' utility in dynamic environments. Besides the data generation and augmentation, our proposed approaches also include novel ML-driven policies for personalized solver strategies, with an emphasis on applications like graph convolutional networks for initial basis selection and reinforcement learning for advanced presolving and cut selection. Additionally, we detail the incorporation of state-of-the-art parameter tuning algorithms which markedly elevate solver performance. Compared with traditional solvers such as Cplex and SCIP, our ML-augmented OptVerse AI Solver demonstrates superior speed and precision across both established benchmarks and real-world scenarios, reinforcing the practical imperative and effectiveness of machine learning techniques in mathematical programming solvers.