 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject Permanence Emerges in a Random Walk along Memory
Apr 04, 2022
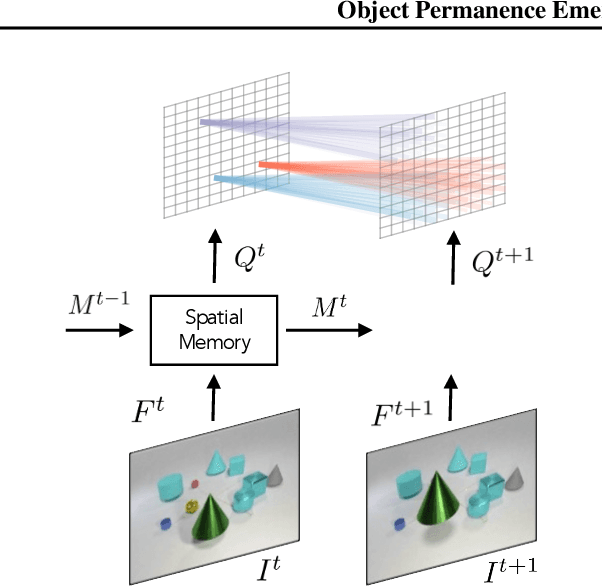

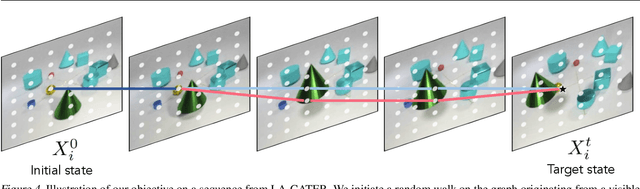
This paper proposes a self-supervised objective for learning representations that localize objects under occlusion - a property known as object permanence. A central question is the choice of learning signal in cases of total occlusion. Rather than directly supervising the locations of invisible objects, we propose a self-supervised objective that requires neither human annotation, nor assumptions about object dynamics. We show that object permanence can emerge by optimizing for temporal coherence of memory: we fit a Markov walk along a space-time graph of memories, where the states in each time step are non-Markovian features from a sequence encoder. This leads to a memory representation that stores occluded objects and predicts their motion, to better localize them. The resulting model outperforms existing approaches on several datasets of increasing complexity and realism, despite requiring minimal supervision and assumptions, and hence being broadly applicable.
Passive Motion Detection via mmWave Communication System
Mar 28, 2022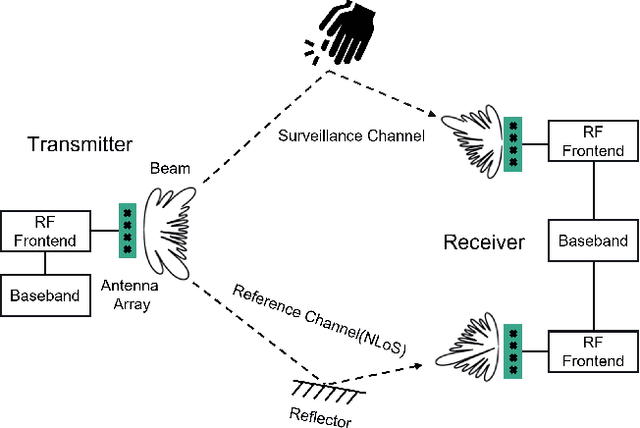
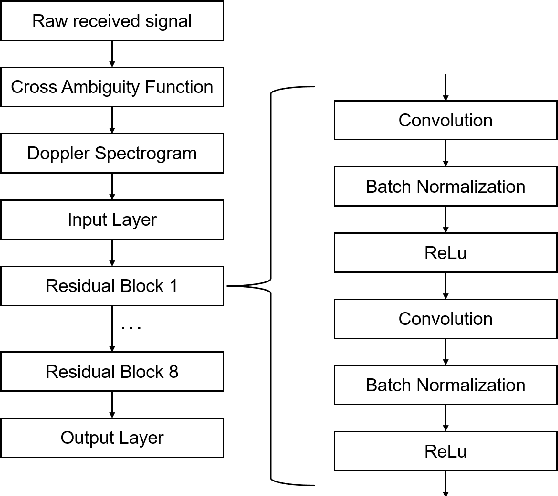
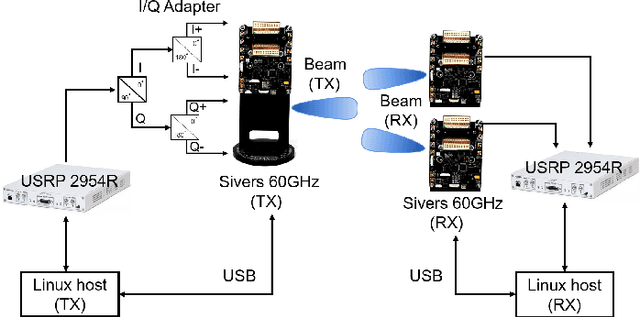
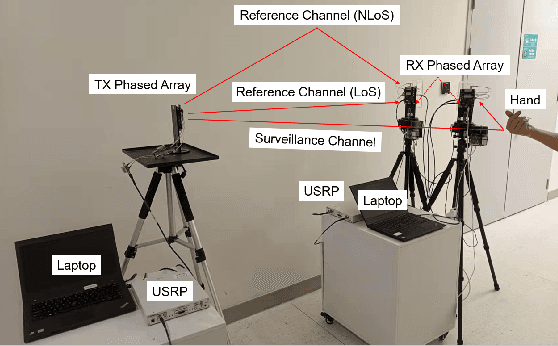
In this paper, an integrated passive sensing and communication system working in 60 GHz band is elaborated, and the sensing performance is investigated in an application of hand gesture recognition. Specifically, in this integrated system, there are two radio frequency (RF) chains at the receiver and one at the transmitter. Each RF chain is connected with one phased array for analog beamforming. To facilitate simultaneous sensing and communication, the transmitter delivers one stream of information-bearing signals via two beam lobes, one is aligned with the main signal propagation path and the other is directed to the sensing target. Signals from the two lobes are received by the two RF chains at the receiver, respectively. By cross ambiguity coherent processing, the time-Doppler spectrograms of hand gestures can be obtained. Relying on the passive sensing system, a dataset of received signals, where three types of hand gestures are sensed, is collected by using Line-of-Sight (LoS) and Non-Line-of-Sight (NLoS) paths as the reference channel respectively. Then a neural network is trained by the dataset for motion detection. It is shown that the classification accuracy rate is high as long as sufficient sensing time is assured. Finally, an empirical model characterizing the relation between the classification accuracy and sensing duration is derived analytically.
GraphCoCo: Graph Complementary Contrastive Learning
Mar 24, 2022
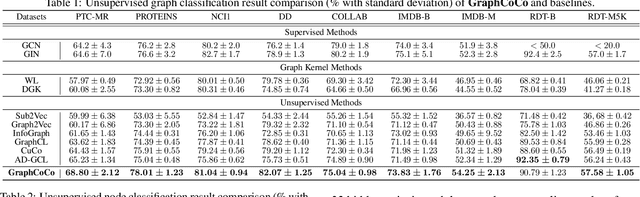
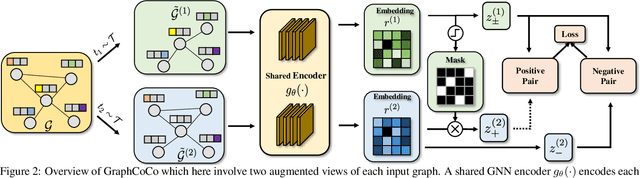
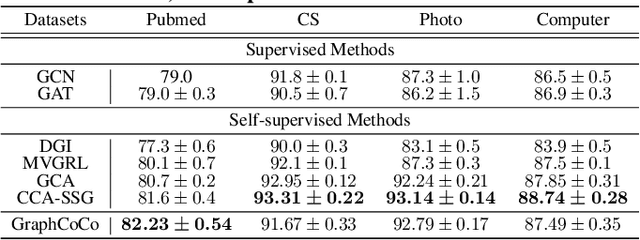
Graph Contrastive Learning (GCL) has shown promising performance in graph representation learning (GRL) without the supervision of manual annotations. GCL can generate graph-level embeddings by maximizing the Mutual Information (MI) between different augmented views of the same graph (positive pairs). However, we identify an obstacle that the optimization of InfoNCE loss only concentrates on a few embeddings dimensions, limiting the distinguishability of embeddings in downstream graph classification tasks. This paper proposes an effective graph complementary contrastive learning approach named GraphCoCo to tackle the above issue. Specifically, we set the embedding of the first augmented view as the anchor embedding to localize "highlighted" dimensions (i.e., the dimensions contribute most in similarity measurement). Then remove these dimensions in the embeddings of the second augmented view to discover neglected complementary representations. Therefore, the combination of anchor and complementary embeddings significantly improves the performance in downstream tasks. Comprehensive experiments on various benchmark datasets are conducted to demonstrate the effectiveness of GraphCoCo, and the results show that our model outperforms the state-of-the-art methods. Source code will be made publicly available.
Spherical Convolution empowered FoV Prediction in 360-degree Video Multicast with Limited FoV Feedback
Jan 29, 2022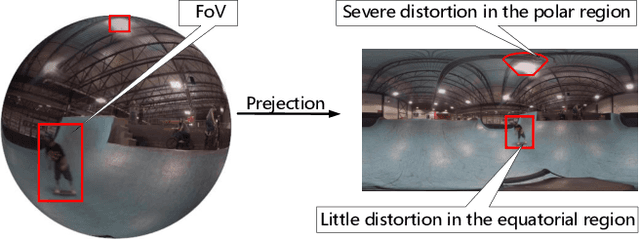

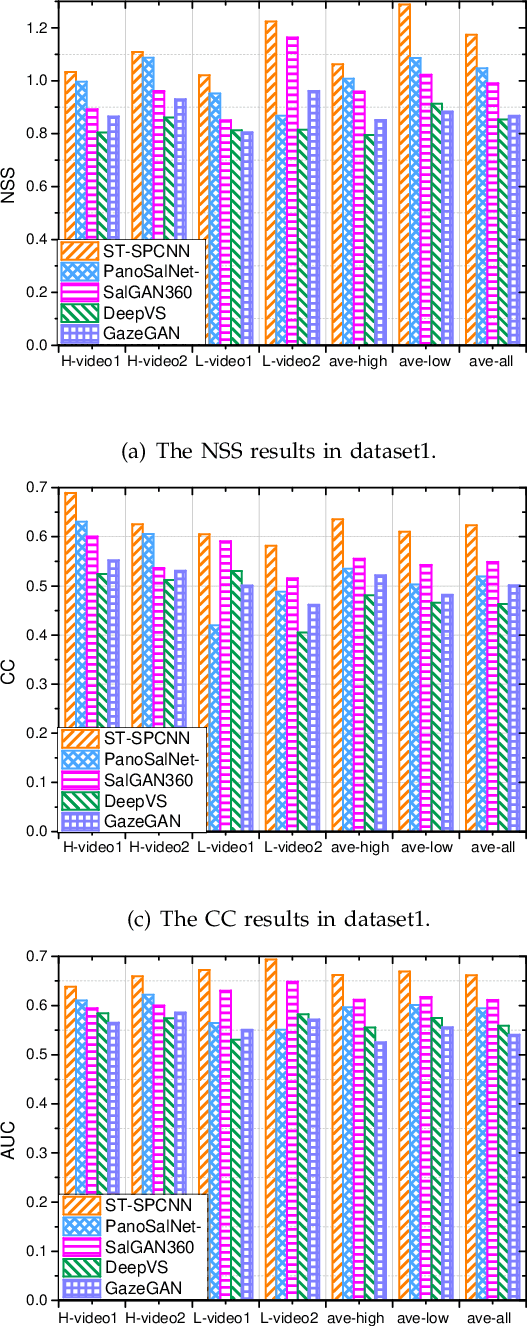
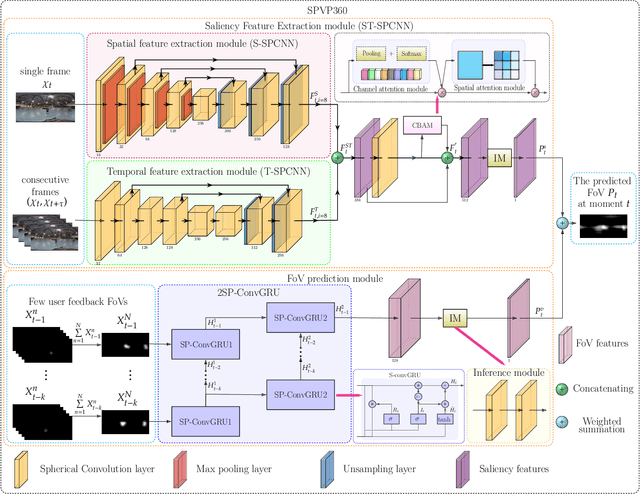
Field of view (FoV) prediction is critical in 360-degree video multicast, which is a key component of the emerging Virtual Reality (VR) and Augmented Reality (AR) applications. Most of the current prediction methods combining saliency detection and FoV information neither take into account that the distortion of projected 360-degree videos can invalidate the weight sharing of traditional convolutional networks, nor do they adequately consider the difficulty of obtaining complete multi-user FoV information, which degrades the prediction performance. This paper proposes a spherical convolution-empowered FoV prediction method, which is a multi-source prediction framework combining salient features extracted from 360-degree video with limited FoV feedback information. A spherical convolution neural network (CNN) is used instead of a traditional two-dimensional CNN to eliminate the problem of weight sharing failure caused by video projection distortion. Specifically, salient spatial-temporal features are extracted through a spherical convolution-based saliency detection model, after which the limited feedback FoV information is represented as a time-series model based on a spherical convolution-empowered gated recurrent unit network. Finally, the extracted salient video features are combined to predict future user FoVs. The experimental results show that the performance of the proposed method is better than other prediction methods.
Input-Specific Robustness Certification for Randomized Smoothing
Dec 21, 2021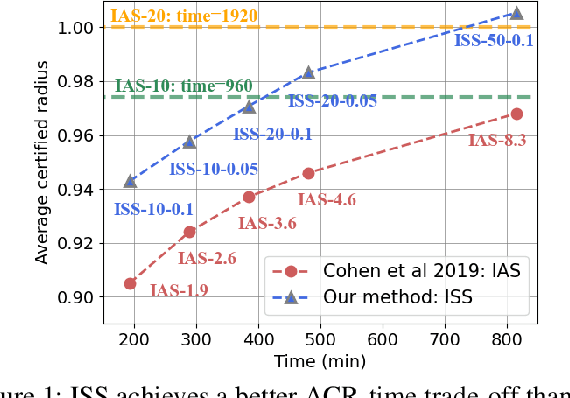
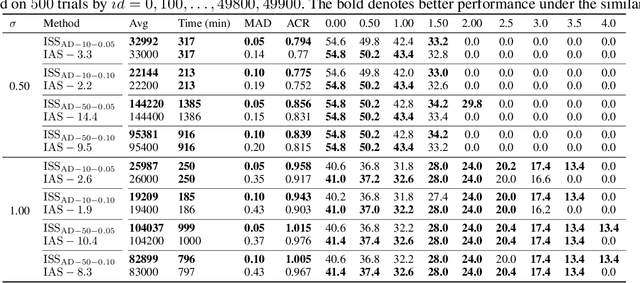
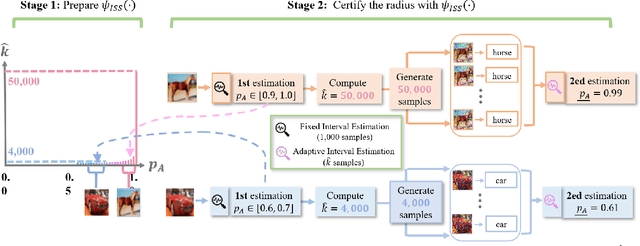
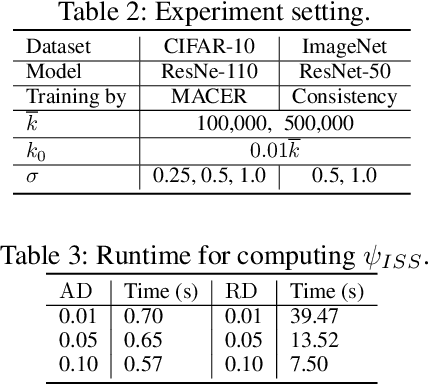
Although randomized smoothing has demonstrated high certified robustness and superior scalability to other certified defenses, the high computational overhead of the robustness certification bottlenecks the practical applicability, as it depends heavily on the large sample approximation for estimating the confidence interval. In existing works, the sample size for the confidence interval is universally set and agnostic to the input for prediction. This Input-Agnostic Sampling (IAS) scheme may yield a poor Average Certified Radius (ACR)-runtime trade-off which calls for improvement. In this paper, we propose Input-Specific Sampling (ISS) acceleration to achieve the cost-effectiveness for robustness certification, in an adaptive way of reducing the sampling size based on the input characteristic. Furthermore, our method universally controls the certified radius decline from the ISS sample size reduction. The empirical results on CIFAR-10 and ImageNet show that ISS can speed up the certification by more than three times at a limited cost of 0.05 certified radius. Meanwhile, ISS surpasses IAS on the average certified radius across the extensive hyperparameter settings. Specifically, ISS achieves ACR=0.958 on ImageNet ($\sigma=1.0$) in 250 minutes, compared to ACR=0.917 by IAS under the same condition. We release our code in \url{https://github.com/roy-ch/Input-Specific-Certification}.
Predicting Axillary Lymph Node Metastasis in Early Breast Cancer Using Deep Learning on Primary Tumor Biopsy Slides
Dec 12, 2021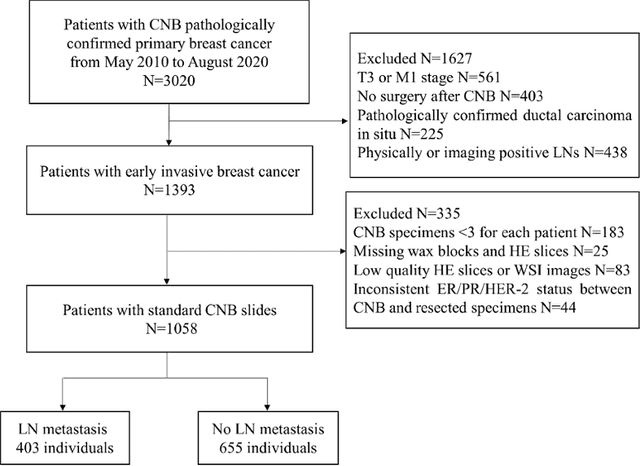
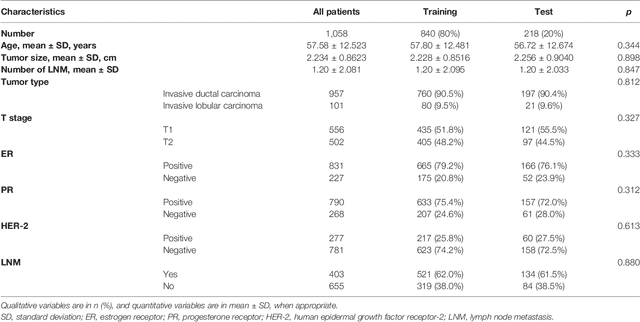
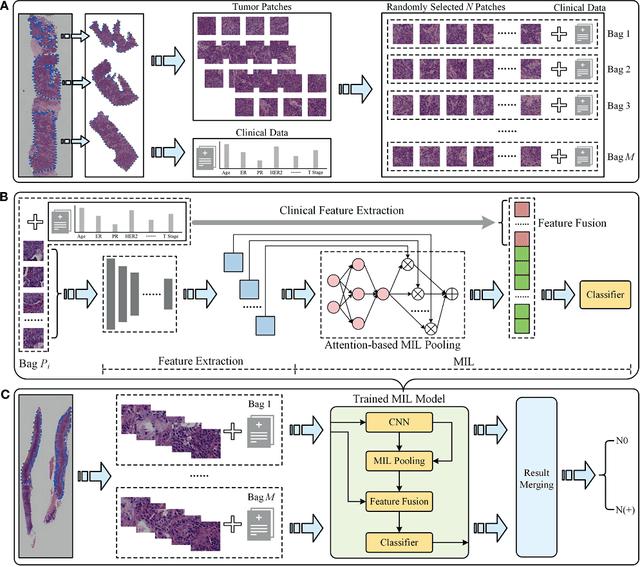
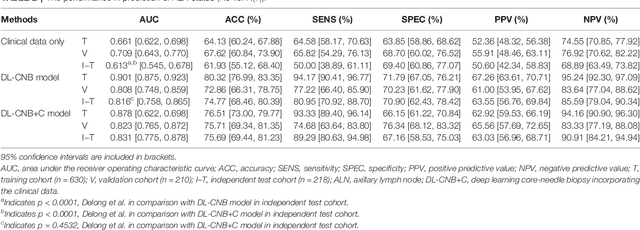
Objectives: To develop and validate a deep learning (DL)-based primary tumor biopsy signature for predicting axillary lymph node (ALN) metastasis preoperatively in early breast cancer (EBC) patients with clinically negative ALN. Methods: A total of 1,058 EBC patients with pathologically confirmed ALN status were enrolled from May 2010 to August 2020. A DL core-needle biopsy (DL-CNB) model was built on the attention-based multiple instance-learning (AMIL) framework to predict ALN status utilizing the DL features, which were extracted from the cancer areas of digitized whole-slide images (WSIs) of breast CNB specimens annotated by two pathologists. Accuracy, sensitivity, specificity, receiver operating characteristic (ROC) curves, and areas under the ROC curve (AUCs) were analyzed to evaluate our model. Results: The best-performing DL-CNB model with VGG16_BN as the feature extractor achieved an AUC of 0.816 (95% confidence interval (CI): 0.758, 0.865) in predicting positive ALN metastasis in the independent test cohort. Furthermore, our model incorporating the clinical data, which was called DL-CNB+C, yielded the best accuracy of 0.831 (95%CI: 0.775, 0.878), especially for patients younger than 50 years (AUC: 0.918, 95%CI: 0.825, 0.971). The interpretation of DL-CNB model showed that the top signatures most predictive of ALN metastasis were characterized by the nucleus features including density ($p$ = 0.015), circumference ($p$ = 0.009), circularity ($p$ = 0.010), and orientation ($p$ = 0.012). Conclusion: Our study provides a novel DL-based biomarker on primary tumor CNB slides to predict the metastatic status of ALN preoperatively for patients with EBC. The codes and dataset are available at https://github.com/bupt-ai-cz/BALNMP
* Accepted by Frontiers in Oncology, for more details, please see https://github.com/bupt-ai-cz/BALNMP
Learning to Learn Transferable Attack
Dec 10, 2021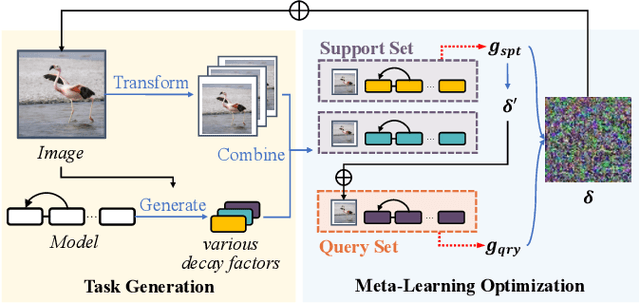
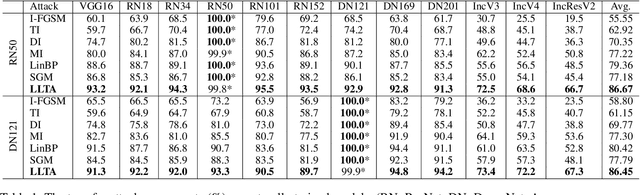
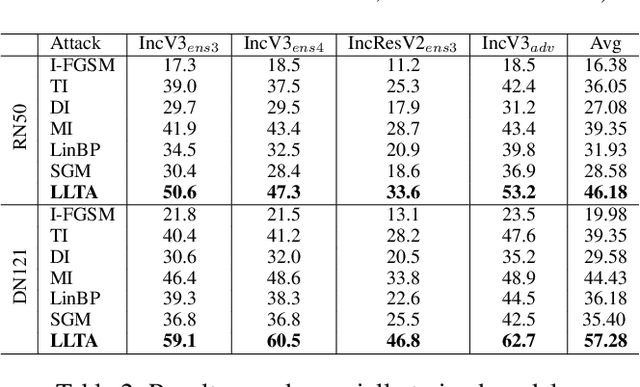
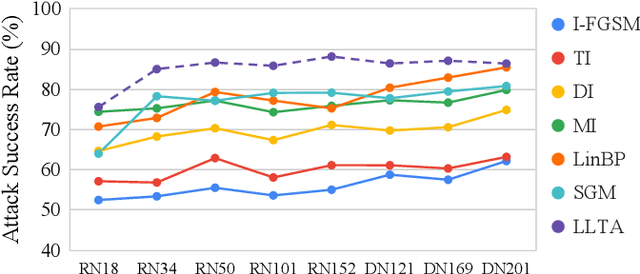
Transfer adversarial attack is a non-trivial black-box adversarial attack that aims to craft adversarial perturbations on the surrogate model and then apply such perturbations to the victim model. However, the transferability of perturbations from existing methods is still limited, since the adversarial perturbations are easily overfitting with a single surrogate model and specific data pattern. In this paper, we propose a Learning to Learn Transferable Attack (LLTA) method, which makes the adversarial perturbations more generalized via learning from both data and model augmentation. For data augmentation, we adopt simple random resizing and padding. For model augmentation, we randomly alter the back propagation instead of the forward propagation to eliminate the effect on the model prediction. By treating the attack of both specific data and a modified model as a task, we expect the adversarial perturbations to adopt enough tasks for generalization. To this end, the meta-learning algorithm is further introduced during the iteration of perturbation generation. Empirical results on the widely-used dataset demonstrate the effectiveness of our attack method with a 12.85% higher success rate of transfer attack compared with the state-of-the-art methods. We also evaluate our method on the real-world online system, i.e., Google Cloud Vision API, to further show the practical potentials of our method.
Fully Attentional Network for Semantic Segmentation
Dec 08, 2021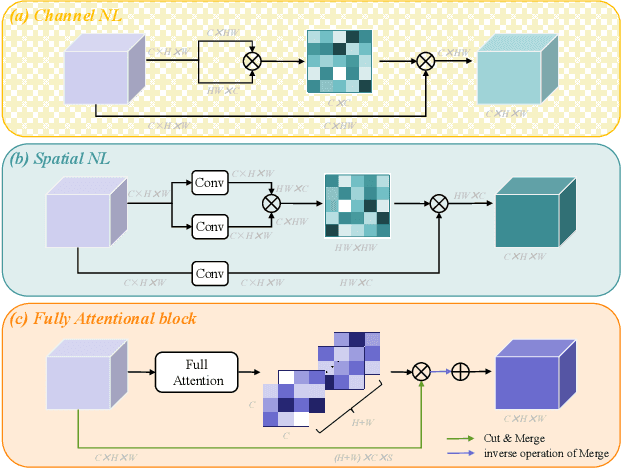
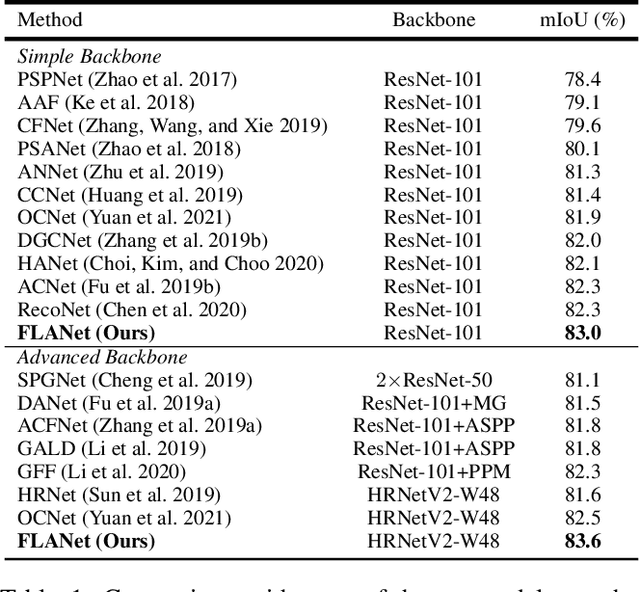
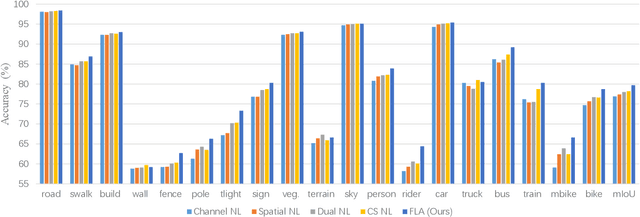

Recent non-local self-attention methods have proven to be effective in capturing long-range dependencies for semantic segmentation. These methods usually form a similarity map of RC*C (by compressing spatial dimensions) or RHW*HW (by compressing channels) to describe the feature relations along either channel or spatial dimensions, where C is the number of channels, H and W are the spatial dimensions of the input feature map. However, such practices tend to condense feature dependencies along the other dimensions,hence causing attention missing, which might lead to inferior results for small/thin categories or inconsistent segmentation inside large objects. To address this problem, we propose anew approach, namely Fully Attentional Network (FLANet),to encode both spatial and channel attentions in a single similarity map while maintaining high computational efficiency. Specifically, for each channel map, our FLANet can harvest feature responses from all other channel maps, and the associated spatial positions as well, through a novel fully attentional module. Our new method has achieved state-of-the-art performance on three challenging semantic segmentation datasets,i.e., 83.6%, 46.99%, and 88.5% on the Cityscapes test set,the ADE20K validation set, and the PASCAL VOC test set,respectively.
Image-specific Convolutional Kernel Modulation for Single Image Super-resolution
Nov 16, 2021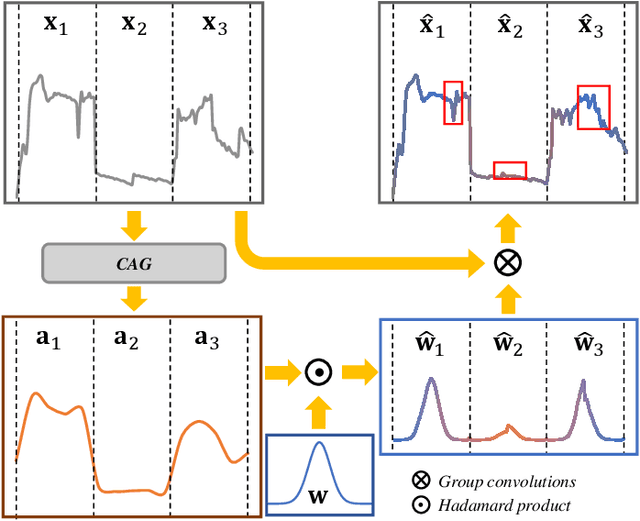
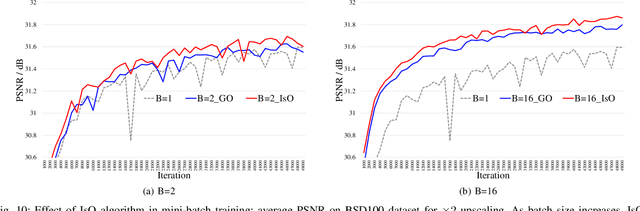
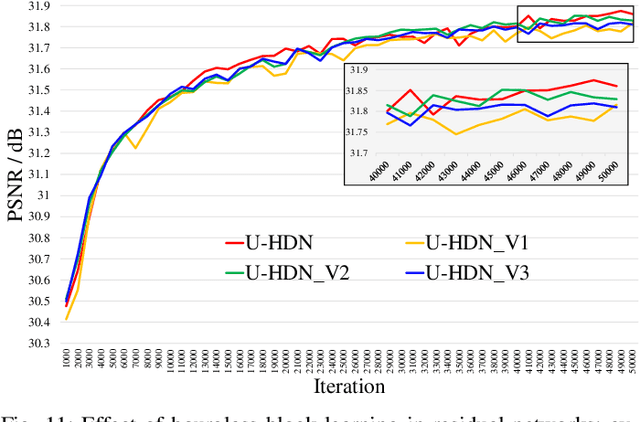
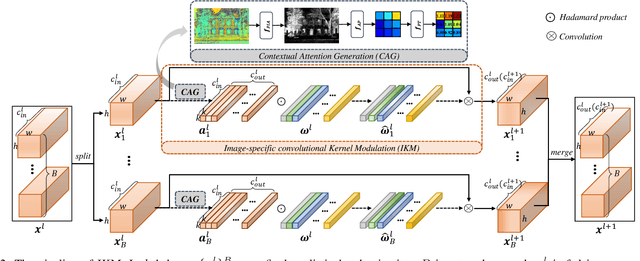
Recently, deep-learning-based super-resolution methods have achieved excellent performances, but mainly focus on training a single generalized deep network by feeding numerous samples. Yet intuitively, each image has its representation, and is expected to acquire an adaptive model. For this issue, we propose a novel image-specific convolutional kernel modulation (IKM) by exploiting the global contextual information of image or feature to generate an attention weight for adaptively modulating the convolutional kernels, which outperforms the vanilla convolution and several existing attention mechanisms while embedding into the state-of-the-art architectures without any additional parameters. Particularly, to optimize our IKM in mini-batch training, we introduce an image-specific optimization (IsO) algorithm, which is more effective than the conventional mini-batch SGD optimization. Furthermore, we investigate the effect of IKM on the state-of-the-art architectures and exploit a new backbone with U-style residual learning and hourglass dense block learning, terms U-Hourglass Dense Network (U-HDN), which is an appropriate architecture to utmost improve the effectiveness of IKM theoretically and experimentally. Extensive experiments on single image super-resolution show that the proposed methods achieve superior performances over state-of-the-art methods. Code is available at github.com/YuanfeiHuang/IKM.
A QoE Model in Point Cloud Video Streaming
Nov 09, 2021

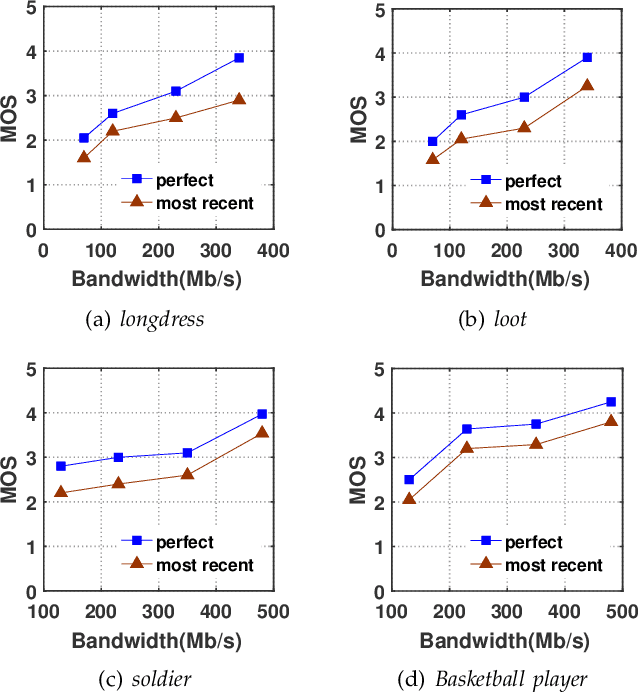

Point cloud video has been widely used by augmented reality (AR) and virtual reality (VR) applications as it allows users to have an immersive experience of six degrees of freedom (6DoFs). Yet there is still a lack of research on quality of experience (QoE) model of point cloud video streaming, which cannot provide optimization metric for streaming systems. Besides, position and color information contained in each pixel of point cloud video, and viewport distance effect caused by 6DoFs viewing procedure make the traditional objective quality evaluation metric cannot be directly used in point cloud video streaming system. In this paper we first analyze the subjective and objective factors related to QoE model. Then an experimental system to simulate point cloud video streaming is setup and detailed subjective quality evaluation experiments are carried out. Based on collected mean opinion score (MOS) data, we propose a QoE model for point cloud video streaming. We also verify the model by actual subjective scoring, and the results show that the proposed QoE model can accurately reflect users' visual perception. We also make the experimental database public to promote the QoE research of point cloud video streaming.