 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstruction of compressed spectral imaging based on global structure and spectral correlation
Oct 27, 2022

In this paper, a convolution sparse coding method based on global structure characteristics and spectral correlation is proposed for the reconstruction of compressive spectral images. The proposed method uses the convolution kernel to operate the global image, which can better preserve image structure information in the spatial dimension. To take full exploration of the constraints between spectra, the coefficients corresponding to the convolution kernel are constrained by the norm to improve spectral accuracy. And, to solve the problem that convolutional sparse coding is insensitive to low frequency, the global total-variation (TV) constraint is added to estimate the low-frequency components. It not only ensures the effective estimation of the low-frequency but also transforms the convolutional sparse coding into a de-noising process, which makes the reconstructing process simpler. Simulations show that compared with the current mainstream optimization methods (DeSCI and Gap-TV), the proposed method improves the reconstruction quality by up to 7 dB in PSNR and 10% in SSIM, and has a great improvement in the details of the reconstructed image.
Depth Is All You Need for Monocular 3D Detection
Oct 05, 2022
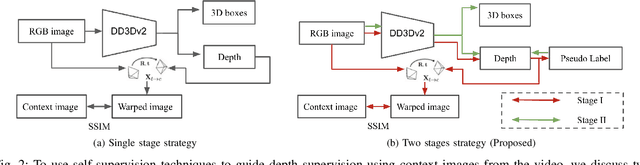

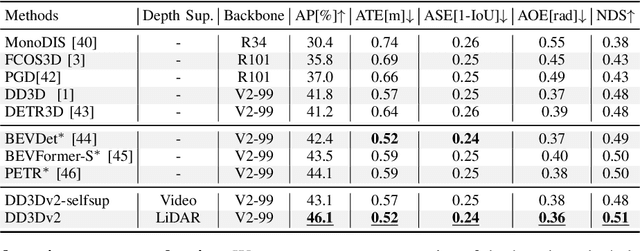
A key contributor to recent progress in 3D detection from single images is monocular depth estimation. Existing methods focus on how to leverage depth explicitly, by generating pseudo-pointclouds or providing attention cues for image features. More recent works leverage depth prediction as a pretraining task and fine-tune the depth representation while training it for 3D detection. However, the adaptation is insufficient and is limited in scale by manual labels. In this work, we propose to further align depth representation with the target domain in unsupervised fashions. Our methods leverage commonly available LiDAR or RGB videos during training time to fine-tune the depth representation, which leads to improved 3D detectors. Especially when using RGB videos, we show that our two-stage training by first generating pseudo-depth labels is critical because of the inconsistency in loss distribution between the two tasks. With either type of reference data, our multi-task learning approach improves over the state of the art on both KITTI and NuScenes, while matching the test-time complexity of its single task sub-network.
Seen to Unseen: When Fuzzy Inference System Predicts IoT Device Positioning Labels That Had Not Appeared in Training Phase
Sep 21, 2022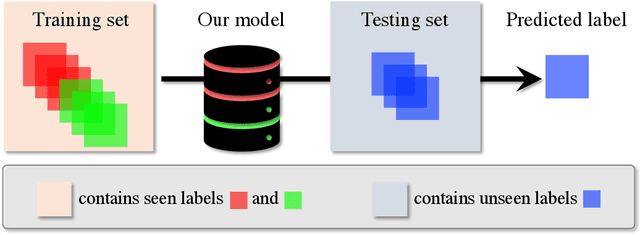
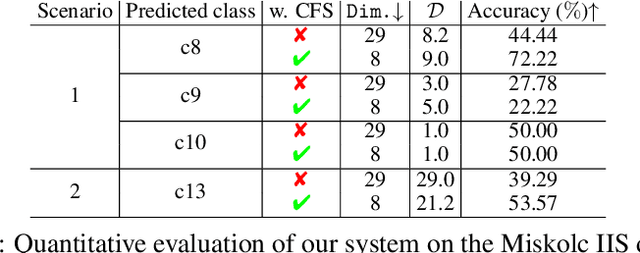
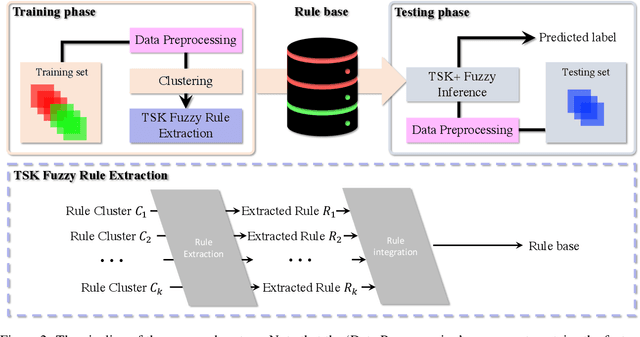
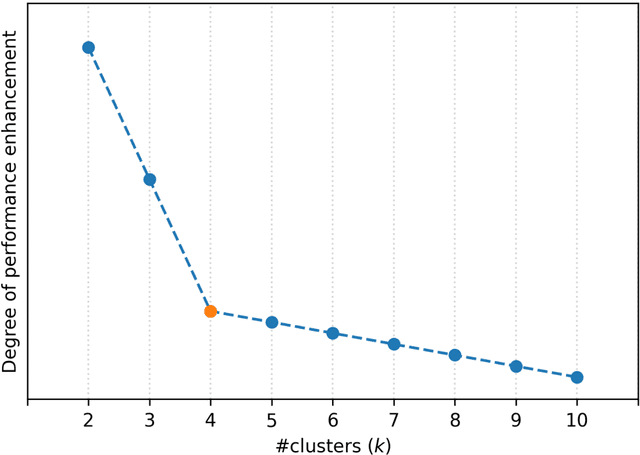
Situating at the core of Artificial Intelligence (AI), Machine Learning (ML), and more specifically, Deep Learning (DL) have embraced great success in the past two decades. However, unseen class label prediction is far less explored due to missing classes being invisible in training ML or DL models. In this work, we propose a fuzzy inference system to cope with such a challenge by adopting TSK+ fuzzy inference engine in conjunction with the Curvature-based Feature Selection (CFS) method. The practical feasibility of our system has been evaluated by predicting the positioning labels of networking devices within the realm of the Internet of Things (IoT). Competitive prediction performance confirms the efficiency and efficacy of our system, especially when a large number of continuous class labels are unseen during the model training stage.
Parameter-Efficient Conformers via Sharing Sparsely-Gated Experts for End-to-End Speech Recognition
Sep 17, 2022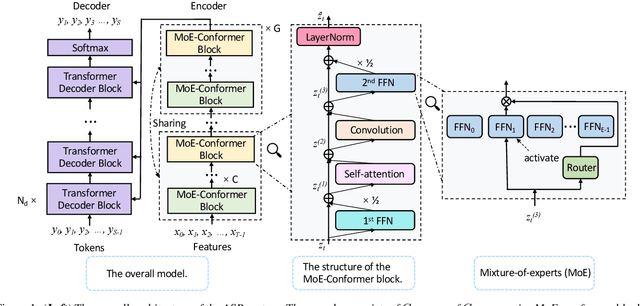
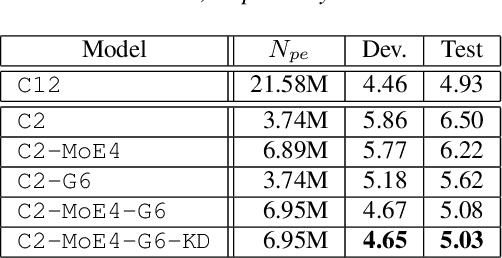
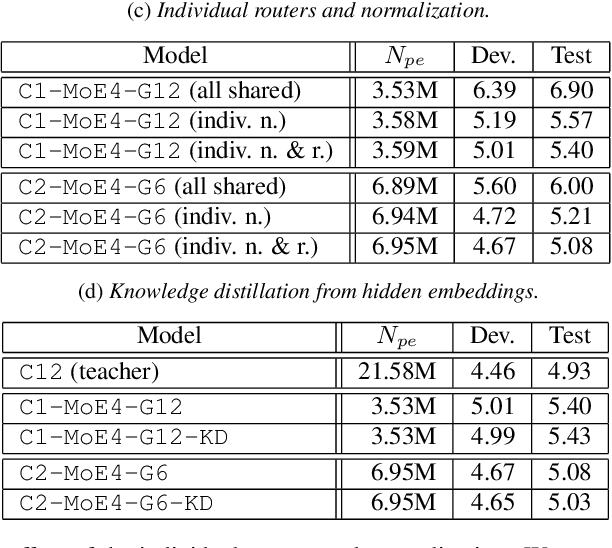
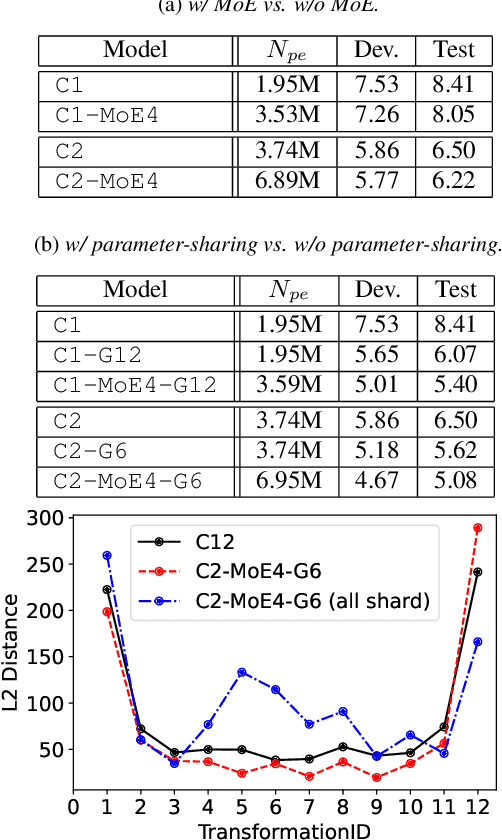
While transformers and their variant conformers show promising performance in speech recognition, the parameterized property leads to much memory cost during training and inference. Some works use cross-layer weight-sharing to reduce the parameters of the model. However, the inevitable loss of capacity harms the model performance. To address this issue, this paper proposes a parameter-efficient conformer via sharing sparsely-gated experts. Specifically, we use sparsely-gated mixture-of-experts (MoE) to extend the capacity of a conformer block without increasing computation. Then, the parameters of the grouped conformer blocks are shared so that the number of parameters is reduced. Next, to ensure the shared blocks with the flexibility of adapting representations at different levels, we design the MoE routers and normalization individually. Moreover, we use knowledge distillation to further improve the performance. Experimental results show that the proposed model achieves competitive performance with 1/3 of the parameters of the encoder, compared with the full-parameter model.
Seeking Subjectivity in Visual Emotion Distribution Learning
Jul 25, 2022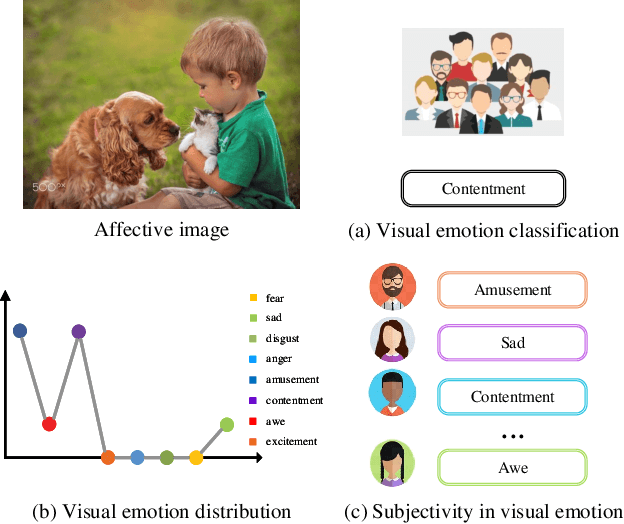
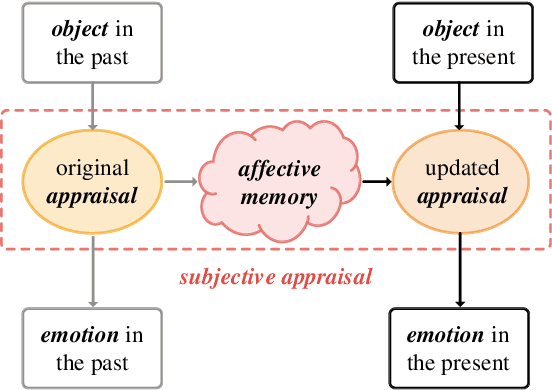
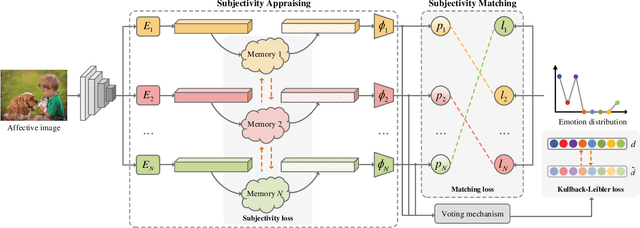
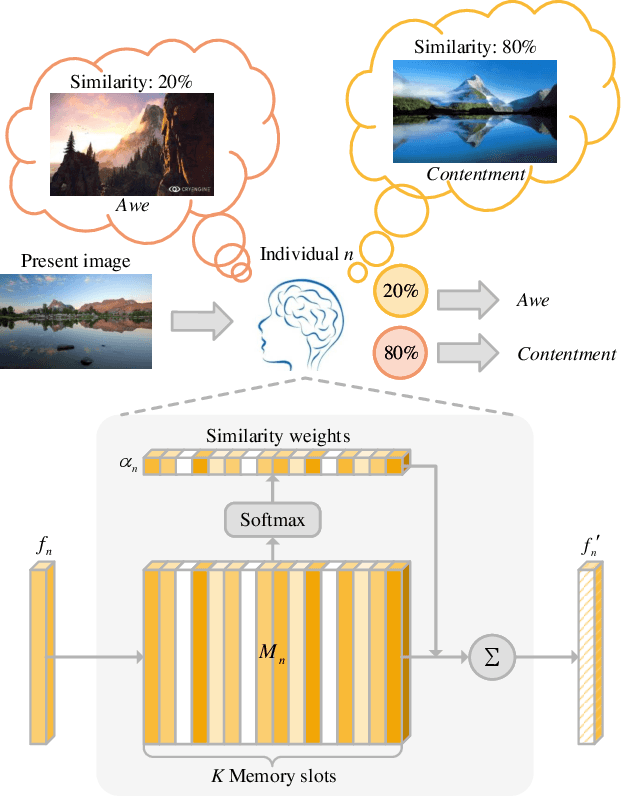
Visual Emotion Analysis (VEA), which aims to predict people's emotions towards different visual stimuli, has become an attractive research topic recently. Rather than a single label classification task, it is more rational to regard VEA as a Label Distribution Learning (LDL) problem by voting from different individuals. Existing methods often predict visual emotion distribution in a unified network, neglecting the inherent subjectivity in its crowd voting process. In psychology, the \textit{Object-Appraisal-Emotion} model has demonstrated that each individual's emotion is affected by his/her subjective appraisal, which is further formed by the affective memory. Inspired by this, we propose a novel \textit{Subjectivity Appraise-and-Match Network (SAMNet)} to investigate the subjectivity in visual emotion distribution. To depict the diversity in crowd voting process, we first propose the \textit{Subjectivity Appraising} with multiple branches, where each branch simulates the emotion evocation process of a specific individual. Specifically, we construct the affective memory with an attention-based mechanism to preserve each individual's unique emotional experience. A subjectivity loss is further proposed to guarantee the divergence between different individuals. Moreover, we propose the \textit{Subjectivity Matching} with a matching loss, aiming at assigning unordered emotion labels to ordered individual predictions in a one-to-one correspondence with the Hungarian algorithm. Extensive experiments and comparisons are conducted on public visual emotion distribution datasets, and the results demonstrate that the proposed SAMNet consistently outperforms the state-of-the-art methods. Ablation study verifies the effectiveness of our method and visualization proves its interpretability.
SpOT: Spatiotemporal Modeling for 3D Object Tracking
Jul 12, 2022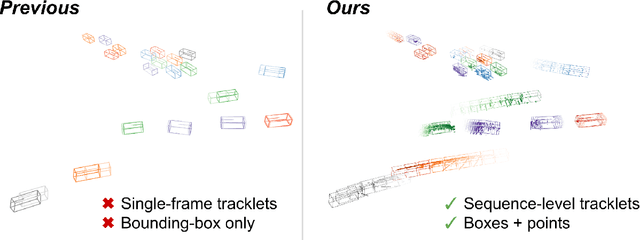
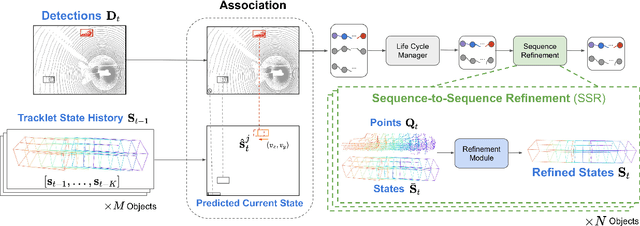
3D multi-object tracking aims to uniquely and consistently identify all mobile entities through time. Despite the rich spatiotemporal information available in this setting, current 3D tracking methods primarily rely on abstracted information and limited history, e.g. single-frame object bounding boxes. In this work, we develop a holistic representation of traffic scenes that leverages both spatial and temporal information of the actors in the scene. Specifically, we reformulate tracking as a spatiotemporal problem by representing tracked objects as sequences of time-stamped points and bounding boxes over a long temporal history. At each timestamp, we improve the location and motion estimates of our tracked objects through learned refinement over the full sequence of object history. By considering time and space jointly, our representation naturally encodes fundamental physical priors such as object permanence and consistency across time. Our spatiotemporal tracking framework achieves state-of-the-art performance on the Waymo and nuScenes benchmarks.
TransFA: Transformer-based Representation for Face Attribute Evaluation
Jul 12, 2022
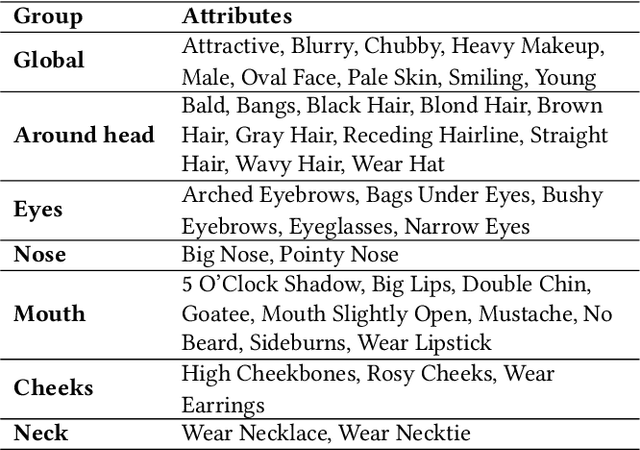
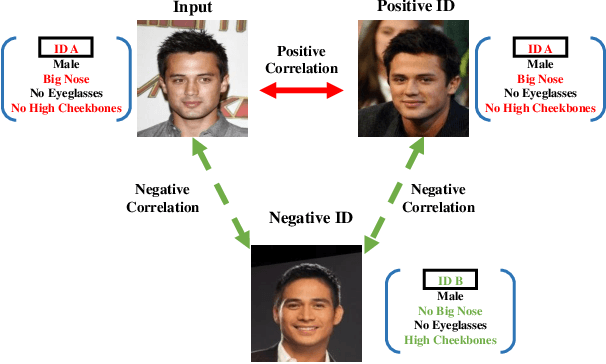
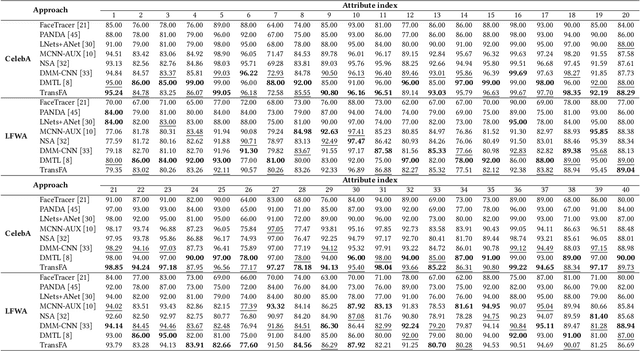
Face attribute evaluation plays an important role in video surveillance and face analysis. Although methods based on convolution neural networks have made great progress, they inevitably only deal with one local neighborhood with convolutions at a time. Besides, existing methods mostly regard face attribute evaluation as the individual multi-label classification task, ignoring the inherent relationship between semantic attributes and face identity information. In this paper, we propose a novel \textbf{trans}former-based representation for \textbf{f}ace \textbf{a}ttribute evaluation method (\textbf{TransFA}), which could effectively enhance the attribute discriminative representation learning in the context of attention mechanism. The multiple branches transformer is employed to explore the inter-correlation between different attributes in similar semantic regions for attribute feature learning. Specially, the hierarchical identity-constraint attribute loss is designed to train the end-to-end architecture, which could further integrate face identity discriminative information to boost performance. Experimental results on multiple face attribute benchmarks demonstrate that the proposed TransFA achieves superior performances compared with state-of-the-art methods.
Digital-twin-enhanced metal tube bending forming real-time prediction method based on Multi-source-input MTL
Jul 03, 2022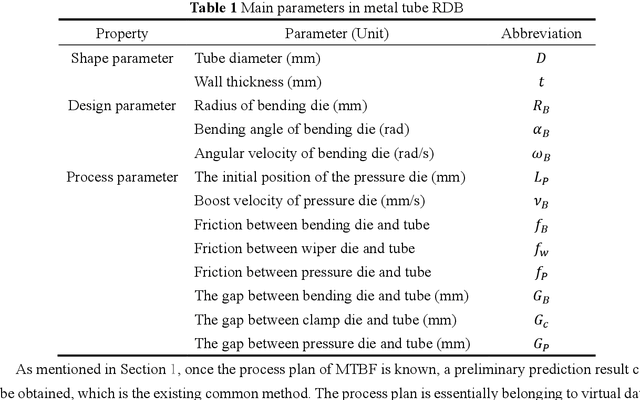
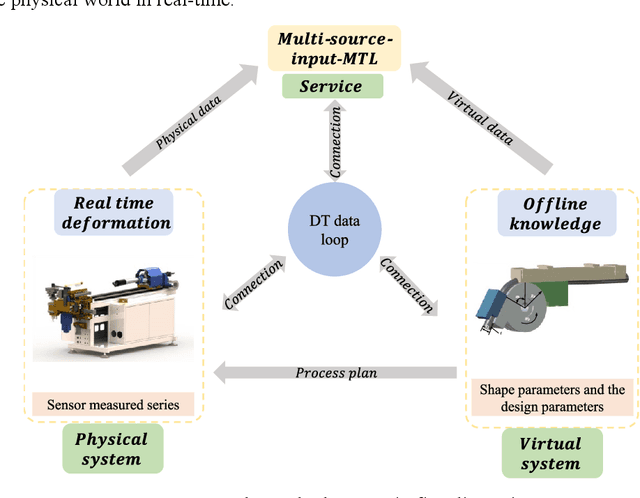

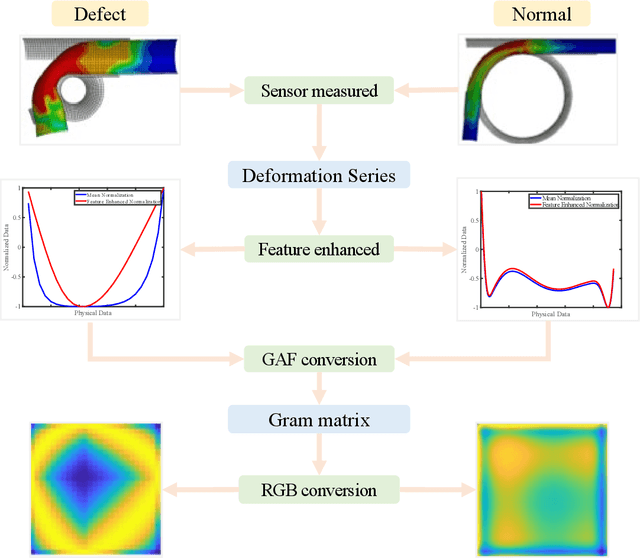
As one of the most widely used metal tube bending methods, the rotary draw bending (RDB) process enables reliable and high-precision metal tube bending forming (MTBF). The forming accuracy is seriously affected by the springback and other potential forming defects, of which the mechanism analysis is difficult to deal with. At the same time, the existing methods are mainly conducted in offline space, ignoring the real-time information in the physical world, which is unreliable and inefficient. To address this issue, a digital-twin-enhanced (DT-enhanced) metal tube bending forming real-time prediction method based on multi-source-input multi-task learning (MTL) is proposed. The new method can achieve comprehensive MTBF real-time prediction. By sharing the common feature of the multi-close domain and adopting group regularization strategy on feature sharing and accepting layers, the accuracy and efficiency of the multi-source-input MTL can be guaranteed. Enhanced by DT, the physical real-time deformation data is aligned in the image dimension by an improved Grammy Angle Field (GAF) conversion, realizing the reflection of the actual processing. Different from the traditional offline prediction methods, the new method integrates the virtual and physical data to achieve a more efficient and accurate real-time prediction result. and the DT mapping connection between virtual and physical systems can be achieved. To exclude the effects of equipment errors, the effectiveness of the proposed method is verified on the physical experiment-verified FE simulation scenarios. At the same time, the common pre-training networks are compared with the proposed method. The results show that the proposed DT-enhanced prediction method is more accurate and efficient.
A Simple Baseline for BEV Perception Without LiDAR
Jun 16, 2022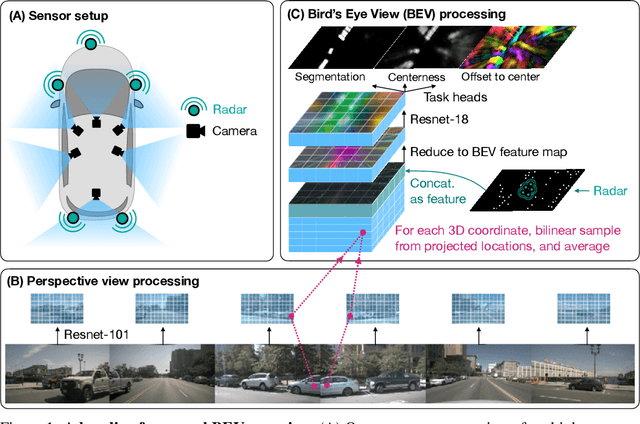



Building 3D perception systems for autonomous vehicles that do not rely on LiDAR is a critical research problem because of the high expense of LiDAR systems compared to cameras and other sensors. Current methods use multi-view RGB data collected from cameras around the vehicle and neurally "lift" features from the perspective images to the 2D ground plane, yielding a "bird's eye view" (BEV) feature representation of the 3D space around the vehicle. Recent research focuses on the way the features are lifted from images to the BEV plane. We instead propose a simple baseline model, where the "lifting" step simply averages features from all projected image locations, and find that it outperforms the current state-of-the-art in BEV vehicle segmentation. Our ablations show that batch size, data augmentation, and input resolution play a large part in performance. Additionally, we reconsider the utility of radar input, which has previously been either ignored or found non-helpful by recent works. With a simple RGB-radar fusion module, we obtain a sizable boost in performance, approaching the accuracy of a LiDAR-enabled system.
An Indoor Environment Sensing and Localization System via mmWave Phased Array
Jun 07, 2022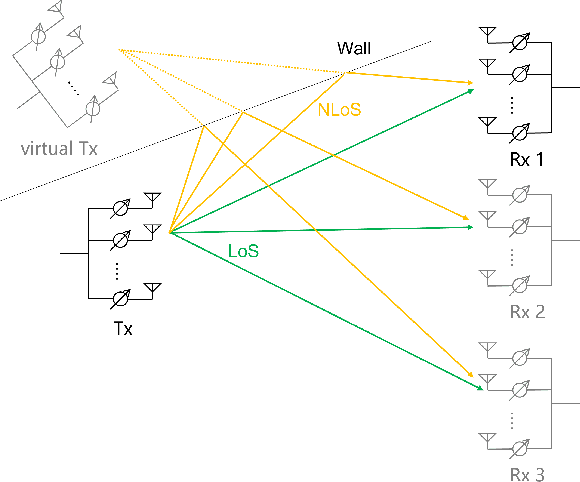
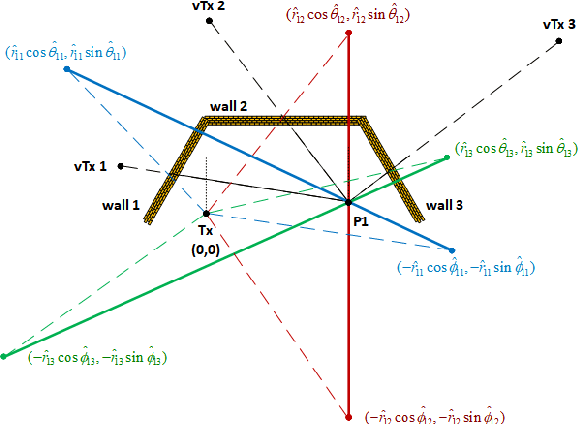
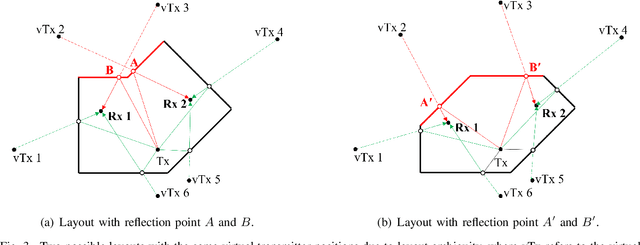
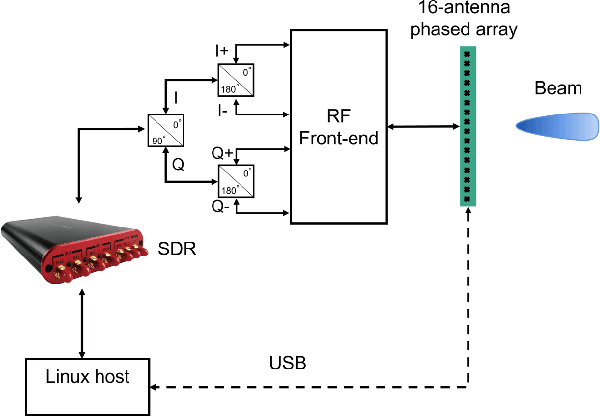
An indoor layout sensing and localization system in 60GHz millimeter wave (mmWave) band, named mmReality, is elaborated in this paper. The mmReality system consists of one transmitter and one mobile receiver, each with a phased array and a single radio frequency (RF) chain. To reconstruct the room layout, the pilot signal is delivered from the transmitter to the receiver via different pairs of transmission and receiving beams, so that the signals at all antenna elements can be resolved. Then, the spatial smoothing and two-dimensional multiple signal classification (MUSIC) algorithm is applied to detect the angle-of-arrival (AoAs) and angle-of-departure (AoDs) of the rays from the transmitter to the receiver. Moreover, the technique of multi-carrier ranging is adopted to measure the distance of each propagation path. Synthesizing the above geometrical parameters, the location of receiver relative to the transmitter can be pinpointed, both line-of-sight (LoS) and non-line-of-sight (NLoS) paths can also be determined. Therefore, the room layout can be reconstructed by moving the receiver and repeating the above measurement in different locations of the room. At the end, we show that the reconstructed room layout can be utilized to locate a mobile device according to its AoA spectrum, even with single access point.