 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoLifter: Lifting Videos to 3D with Fast Hierarchical Stereo Alignment
Jan 03, 2025



Efficiently reconstructing accurate 3D models from monocular video is a key challenge in computer vision, critical for advancing applications in virtual reality, robotics, and scene understanding. Existing approaches typically require pre-computed camera parameters and frame-by-frame reconstruction pipelines, which are prone to error accumulation and entail significant computational overhead. To address these limitations, we introduce VideoLifter, a novel framework that leverages geometric priors from a learnable model to incrementally optimize a globally sparse to dense 3D representation directly from video sequences. VideoLifter segments the video sequence into local windows, where it matches and registers frames, constructs consistent fragments, and aligns them hierarchically to produce a unified 3D model. By tracking and propagating sparse point correspondences across frames and fragments, VideoLifter incrementally refines camera poses and 3D structure, minimizing reprojection error for improved accuracy and robustness. This approach significantly accelerates the reconstruction process, reducing training time by over 82% while surpassing current state-of-the-art methods in visual fidelity and computational efficiency.
Dynamic Gaussian Marbles for Novel View Synthesis of Casual Monocular Videos
Jun 26, 2024



Gaussian splatting has become a popular representation for novel-view synthesis, exhibiting clear strengths in efficiency, photometric quality, and compositional edibility. Following its success, many works have extended Gaussians to 4D, showing that dynamic Gaussians maintain these benefits while also tracking scene geometry far better than alternative representations. Yet, these methods assume dense multi-view videos as supervision, constraining their use to controlled capture settings. In this work, we extend the capability of Gaussian scene representations to casually captured monocular videos. We show that existing 4D Gaussian methods dramatically fail in this setup because the monocular setting is underconstrained. Building off this finding, we propose Dynamic Gaussian Marbles (DGMarbles), consisting of three core modifications that target the difficulties of the monocular setting. First, DGMarbles uses isotropic Gaussian "marbles", reducing the degrees of freedom of each Gaussian, and constraining the optimization to focus on motion and appearance over local shape. Second, DGMarbles employs a hierarchical divide-and-conquer learning strategy to guide the optimization towards solutions with coherent motion. Finally, DGMarbles adds image-level and geometry-level priors into the optimization, including a tracking loss that takes advantage of recent progress in point tracking. By constraining the optimization in these ways, DGMarbles learns Gaussian trajectories that enable novel-view rendering and accurately capture the 3D motion of the scene elements. We evaluate on the (monocular) Nvidia Dynamic Scenes dataset and the Dycheck iPhone dataset, and show that DGMarbles significantly outperforms other Gaussian baselines in quality, and is on-par with non-Gaussian representations, all while maintaining the efficiency, compositionality, editability, and tracking benefits of Gaussians.
View-Consistent Hierarchical 3D SegmentationUsing Ultrametric Feature Fields
May 30, 2024Large-scale vision foundation models such as Segment Anything (SAM) demonstrate impressive performance in zero-shot image segmentation at multiple levels of granularity. However, these zero-shot predictions are rarely 3D-consistent. As the camera viewpoint changes in a scene, so do the segmentation predictions, as well as the characterizations of ``coarse" or ``fine" granularity. In this work, we address the challenging task of lifting multi-granular and view-inconsistent image segmentations into a hierarchical and 3D-consistent representation. We learn a novel feature field within a Neural Radiance Field (NeRF) representing a 3D scene, whose segmentation structure can be revealed at different scales by simply using different thresholds on feature distance. Our key idea is to learn an ultrametric feature space, which unlike a Euclidean space, exhibits transitivity in distance-based grouping, naturally leading to a hierarchical clustering. Put together, our method takes view-inconsistent multi-granularity 2D segmentations as input and produces a hierarchy of 3D-consistent segmentations as output. We evaluate our method and several baselines on synthetic datasets with multi-view images and multi-granular segmentation, showcasing improved accuracy and viewpoint-consistency. We additionally provide qualitative examples of our model's 3D hierarchical segmentations in real world scenes.\footnote{The code and dataset are available at:
CurveCloudNet: Processing Point Clouds with 1D Structure
Mar 21, 2023



Modern depth sensors such as LiDAR operate by sweeping laser-beams across the scene, resulting in a point cloud with notable 1D curve-like structures. In this work, we introduce a new point cloud processing scheme and backbone, called CurveCloudNet, which takes advantage of the curve-like structure inherent to these sensors. While existing backbones discard the rich 1D traversal patterns and rely on Euclidean operations, CurveCloudNet parameterizes the point cloud as a collection of polylines (dubbed a "curve cloud"), establishing a local surface-aware ordering on the points. Our method applies curve-specific operations to process the curve cloud, including a symmetric 1D convolution, a ball grouping for merging points along curves, and an efficient 1D farthest point sampling algorithm on curves. By combining these curve operations with existing point-based operations, CurveCloudNet is an efficient, scalable, and accurate backbone with low GPU memory requirements. Evaluations on the ShapeNet, Kortx, Audi Driving, and nuScenes datasets demonstrate that CurveCloudNet outperforms both point-based and sparse-voxel backbones in various segmentation settings, notably scaling better to large scenes than point-based alternatives while exhibiting better single object performance than sparse-voxel alternatives.
SpOT: Spatiotemporal Modeling for 3D Object Tracking
Jul 12, 2022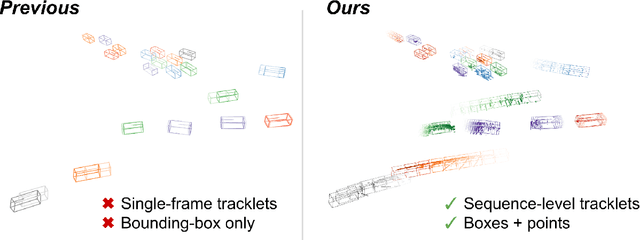
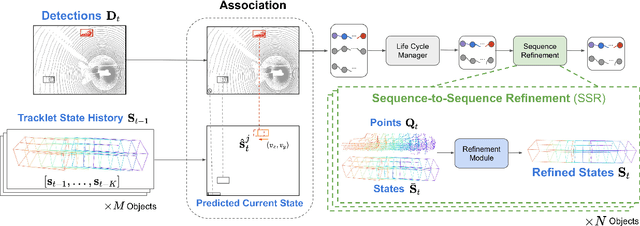
3D multi-object tracking aims to uniquely and consistently identify all mobile entities through time. Despite the rich spatiotemporal information available in this setting, current 3D tracking methods primarily rely on abstracted information and limited history, e.g. single-frame object bounding boxes. In this work, we develop a holistic representation of traffic scenes that leverages both spatial and temporal information of the actors in the scene. Specifically, we reformulate tracking as a spatiotemporal problem by representing tracked objects as sequences of time-stamped points and bounding boxes over a long temporal history. At each timestamp, we improve the location and motion estimates of our tracked objects through learned refinement over the full sequence of object history. By considering time and space jointly, our representation naturally encodes fundamental physical priors such as object permanence and consistency across time. Our spatiotemporal tracking framework achieves state-of-the-art performance on the Waymo and nuScenes benchmarks.