 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Cross-Language Investigation into Jailbreak Attacks in Large Language Models
Jan 30, 2024Large Language Models (LLMs) have become increasingly popular for their advanced text generation capabilities across various domains. However, like any software, they face security challenges, including the risk of 'jailbreak' attacks that manipulate LLMs to produce prohibited content. A particularly underexplored area is the Multilingual Jailbreak attack, where malicious questions are translated into various languages to evade safety filters. Currently, there is a lack of comprehensive empirical studies addressing this specific threat. To address this research gap, we conducted an extensive empirical study on Multilingual Jailbreak attacks. We developed a novel semantic-preserving algorithm to create a multilingual jailbreak dataset and conducted an exhaustive evaluation on both widely-used open-source and commercial LLMs, including GPT-4 and LLaMa. Additionally, we performed interpretability analysis to uncover patterns in Multilingual Jailbreak attacks and implemented a fine-tuning mitigation method. Our findings reveal that our mitigation strategy significantly enhances model defense, reducing the attack success rate by 96.2%. This study provides valuable insights into understanding and mitigating Multilingual Jailbreak attacks.
Progress and Prospects in 3D Generative AI: A Technical Overview including 3D human
Jan 05, 2024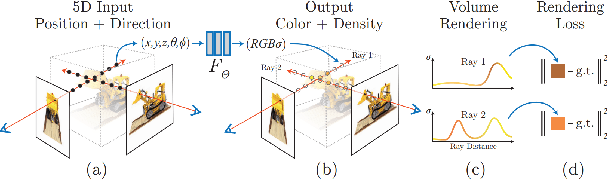


While AI-generated text and 2D images continue to expand its territory, 3D generation has gradually emerged as a trend that cannot be ignored. Since the year 2023 an abundant amount of research papers has emerged in the domain of 3D generation. This growth encompasses not just the creation of 3D objects, but also the rapid development of 3D character and motion generation. Several key factors contribute to this progress. The enhanced fidelity in stable diffusion, coupled with control methods that ensure multi-view consistency, and realistic human models like SMPL-X, contribute synergistically to the production of 3D models with remarkable consistency and near-realistic appearances. The advancements in neural network-based 3D storing and rendering models, such as Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS), have accelerated the efficiency and realism of neural rendered models. Furthermore, the multimodality capabilities of large language models have enabled language inputs to transcend into human motion outputs. This paper aims to provide a comprehensive overview and summary of the relevant papers published mostly during the latter half year of 2023. It will begin by discussing the AI generated object models in 3D, followed by the generated 3D human models, and finally, the generated 3D human motions, culminating in a conclusive summary and a vision for the future.
DeLR: Active Learning for Detection with Decoupled Localization and Recognition Query
Dec 28, 2023Active learning has been demonstrated effective to reduce labeling cost, while most progress has been designed for image recognition, there still lacks instance-level active learning for object detection. In this paper, we rethink two key components, i.e., localization and recognition, for object detection, and find that the correctness of them are highly related, therefore, it is not necessary to annotate both boxes and classes if we are given pseudo annotations provided with the trained model. Motivated by this, we propose an efficient query strategy, termed as DeLR, that Decoupling the Localization and Recognition for active query. In this way, we are probably free of class annotations when the localization is correct, and able to assign the labeling budget for more informative samples. There are two main differences in DeLR: 1) Unlike previous methods mostly focus on image-level annotations, where the queried samples are selected and exhausted annotated. In DeLR, the query is based on region-level, and we only annotate the object region that is queried; 2) Instead of directly providing both localization and recognition annotations, we separately query the two components, and thus reduce the recognition budget with the pseudo class labels provided by the model. Experiments on several benchmarks demonstrate its superiority. We hope our proposed query strategy would shed light on researches in active learning in object detection.
A Dual Domain Multi-exposure Image Fusion Network based on the Spatial-Frequency Integration
Dec 17, 2023Multi-exposure image fusion aims to generate a single high-dynamic image by integrating images with different exposures. Existing deep learning-based multi-exposure image fusion methods primarily focus on spatial domain fusion, neglecting the global modeling ability of the frequency domain. To effectively leverage the global illumination modeling ability of the frequency domain, we propose a novelty perspective on multi-exposure image fusion via the Spatial-Frequency Integration Framework, named MEF-SFI. Initially, we revisit the properties of the Fourier transform on the 2D image, and verify the feasibility of multi-exposure image fusion on the frequency domain where the amplitude and phase component is able to guide the integration of the illumination information. Subsequently, we present the deep Fourier-based multi-exposure image fusion framework, which consists of a spatial path and frequency path for local and global modeling separately. Specifically, we introduce a Spatial-Frequency Fusion Block to facilitate efficient interaction between dual domains and capture complementary information from input images with different exposures. Finally, we combine a dual domain loss function to ensure the retention of complementary information in both the spatial and frequency domains. Extensive experiments on the PQA-MEF dataset demonstrate that our method achieves visual-appealing fusion results against state-of-the-art multi-exposure image fusion approaches. Our code is available at https://github.com/SSyangguang/MEF-freq.
Multi-Scene Generalized Trajectory Global Graph Solver with Composite Nodes for Multiple Object Tracking
Dec 14, 2023The global multi-object tracking (MOT) system can consider interaction, occlusion, and other ``visual blur'' scenarios to ensure effective object tracking in long videos. Among them, graph-based tracking-by-detection paradigms achieve surprising performance. However, their fully-connected nature poses storage space requirements that challenge algorithm handling long videos. Currently, commonly used methods are still generated trajectories by building one-forward associations across frames. Such matches produced under the guidance of first-order similarity information may not be optimal from a longer-time perspective. Moreover, they often lack an end-to-end scheme for correcting mismatches. This paper proposes the Composite Node Message Passing Network (CoNo-Link), a multi-scene generalized framework for modeling ultra-long frames information for association. CoNo-Link's solution is a low-storage overhead method for building constrained connected graphs. In addition to the previous method of treating objects as nodes, the network innovatively treats object trajectories as nodes for information interaction, improving the graph neural network's feature representation capability. Specifically, we formulate the graph-building problem as a top-k selection task for some reliable objects or trajectories. Our model can learn better predictions on longer-time scales by adding composite nodes. As a result, our method outperforms the state-of-the-art in several commonly used datasets.
A Multi-scale Information Integration Framework for Infrared and Visible Image Fusion
Dec 07, 2023



Infrared and visible image fusion aims at generating a fused image containing the intensity and detail information of source images, and the key issue is effectively measuring and integrating the complementary information of multi-modality images from the same scene. Existing methods mostly adopt a simple weight in the loss function to decide the information retention of each modality rather than adaptively measuring complementary information for different image pairs. In this study, we propose a multi-scale dual attention (MDA) framework for infrared and visible image fusion, which is designed to measure and integrate complementary information in both structure and loss function at the image and patch level. In our method, the residual downsample block decomposes source images into three scales first. Then, dual attention fusion block integrates complementary information and generates a spatial and channel attention map at each scale for feature fusion. Finally, the output image is reconstructed by the residual reconstruction block. Loss function consists of image-level, feature-level and patch-level three parts, of which the calculation of the image-level and patch-level two parts are based on the weights generated by the complementary information measurement. Indeed, to constrain the pixel intensity distribution between the output and infrared image, a style loss is added. Our fusion results perform robust and informative across different scenarios. Qualitative and quantitative results on two datasets illustrate that our method is able to preserve both thermal radiation and detailed information from two modalities and achieve comparable results compared with the other state-of-the-art methods. Ablation experiments show the effectiveness of our information integration architecture and adaptively measure complementary information retention in the loss function.
EtC: Temporal Boundary Expand then Clarify for Weakly Supervised Video Grounding with Multimodal Large Language Model
Dec 05, 2023



Early weakly supervised video grounding (WSVG) methods often struggle with incomplete boundary detection due to the absence of temporal boundary annotations. To bridge the gap between video-level and boundary-level annotation, explicit-supervision methods, i.e., generating pseudo-temporal boundaries for training, have achieved great success. However, data augmentations in these methods might disrupt critical temporal information, yielding poor pseudo boundaries. In this paper, we propose a new perspective that maintains the integrity of the original temporal content while introducing more valuable information for expanding the incomplete boundaries. To this end, we propose EtC (Expand then Clarify), first use the additional information to expand the initial incomplete pseudo boundaries, and subsequently refine these expanded ones to achieve precise boundaries. Motivated by video continuity, i.e., visual similarity across adjacent frames, we use powerful multimodal large language models (MLLMs) to annotate each frame within initial pseudo boundaries, yielding more comprehensive descriptions for expanded boundaries. To further clarify the noise of expanded boundaries, we combine mutual learning with a tailored proposal-level contrastive objective to use a learnable approach to harmonize a balance between incomplete yet clean (initial) and comprehensive yet noisy (expanded) boundaries for more precise ones. Experiments demonstrate the superiority of our method on two challenging WSVG datasets.
Viewport Prediction for Volumetric Video Streaming by Exploring Video Saliency and Trajectory Information
Nov 28, 2023Volumetric video, also known as hologram video, is a novel medium that portrays natural content in Virtual Reality (VR), Augmented Reality (AR), and Mixed Reality (MR). It is expected to be the next-gen video technology and a prevalent use case for 5G and beyond wireless communication. Considering that each user typically only watches a section of the volumetric video, known as the viewport, it is essential to have precise viewport prediction for optimal performance. However, research on this topic is still in its infancy. In the end, this paper presents and proposes a novel approach, named Saliency and Trajectory Viewport Prediction (STVP), which aims to improve the precision of viewport prediction in volumetric video streaming. The STVP extensively utilizes video saliency information and viewport trajectory. To our knowledge, this is the first comprehensive study of viewport prediction in volumetric video streaming. In particular, we introduce a novel sampling method, Uniform Random Sampling (URS), to reduce computational complexity while still preserving video features in an efficient manner. Then we present a saliency detection technique that incorporates both spatial and temporal information for detecting static, dynamic geometric, and color salient regions. Finally, we intelligently fuse saliency and trajectory information to achieve more accurate viewport prediction. We conduct extensive simulations to evaluate the effectiveness of our proposed viewport prediction methods using state-of-the-art volumetric video sequences. The experimental results show the superiority of the proposed method over existing schemes. The dataset and source code will be publicly accessible after acceptance.
Joint Design of ISAC Waveform under PAPR Constraints
Nov 20, 2023



In this paper, we formulate the precoding problem of integrated sensing and communication (ISAC) waveform as a non-convex quadratically constrainted quadratic program (QCQP), in which the weighted sum of communication multi-user interference (MUI) and the gap between dual-use waveform and ideal radar waveform is minimized with peak-to-average power ratio (PAPR) constraints. We propose an efficient algorithm based on alternating direction method of multipliers (ADMM), which is able to decouple multiple variables and provide a closed-form solution for each subproblem. In addition, to improve the sensing performance in both spatial and temporal domains, we propose a new criteria to design the ideal radar waveform, in which the beam pattern is made similar to the ideal one and the integrated sidelobe level of the ambiguity function in each target direction is minimized in the region of interest. The limited memory Broyden-Fletcher-Goldfarb-Shanno (L-BFGS) algorithm is applied to the design of the ideal radar waveform which works as a reference in the design of the dual-function waveform. Numerical results indicate that the designed dual-function waveform is capable of offering good communication quality of service (QoS) and sensing performance.
Audio-visual Saliency for Omnidirectional Videos
Nov 09, 2023Visual saliency prediction for omnidirectional videos (ODVs) has shown great significance and necessity for omnidirectional videos to help ODV coding, ODV transmission, ODV rendering, etc.. However, most studies only consider visual information for ODV saliency prediction while audio is rarely considered despite its significant influence on the viewing behavior of ODV. This is mainly due to the lack of large-scale audio-visual ODV datasets and corresponding analysis. Thus, in this paper, we first establish the largest audio-visual saliency dataset for omnidirectional videos (AVS-ODV), which comprises the omnidirectional videos, audios, and corresponding captured eye-tracking data for three video sound modalities including mute, mono, and ambisonics. Then we analyze the visual attention behavior of the observers under various omnidirectional audio modalities and visual scenes based on the AVS-ODV dataset. Furthermore, we compare the performance of several state-of-the-art saliency prediction models on the AVS-ODV dataset and construct a new benchmark. Our AVS-ODV datasets and the benchmark will be released to facilitate future research.