 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Distance Field Demonstration of Imaging-Free Drone Identification in Intracity Environments
Apr 26, 2025



Detecting small objects, such as drones, over long distances presents a significant challenge with broad implications for security, surveillance, environmental monitoring, and autonomous systems. Traditional imaging-based methods rely on high-resolution image acquisition, but are often constrained by range, power consumption, and cost. In contrast, data-driven single-photon-single-pixel light detection and ranging (\text{D\textsuperscript{2}SP\textsuperscript{2}-LiDAR}) provides an imaging-free alternative, directly enabling target identification while reducing system complexity and cost. However, its detection range has been limited to a few hundred meters. Here, we introduce a novel integration of residual neural networks (ResNet) with \text{D\textsuperscript{2}SP\textsuperscript{2}-LiDAR}, incorporating a refined observation model to extend the detection range to 5~\si{\kilo\meter} in an intracity environment while enabling high-accuracy identification of drone poses and types. Experimental results demonstrate that our approach not only outperforms conventional imaging-based recognition systems, but also achieves 94.93\% pose identification accuracy and 97.99\% type classification accuracy, even under weak signal conditions with long distances and low signal-to-noise ratios (SNRs). These findings highlight the potential of imaging-free methods for robust long-range detection of small targets in real-world scenarios.
Merit-based Fair Combinatorial Semi-Bandit with Unrestricted Feedback Delays
Jul 29, 2024



We study the stochastic combinatorial semi-bandit problem with unrestricted feedback delays under merit-based fairness constraints. This is motivated by applications such as crowdsourcing, and online advertising, where immediate feedback is not immediately available and fairness among different choices (or arms) is crucial. We consider two types of unrestricted feedback delays: reward-independent delays where the feedback delays are independent of the rewards, and reward-dependent delays where the feedback delays are correlated with the rewards. Furthermore, we introduce merit-based fairness constraints to ensure a fair selection of the arms. We define the reward regret and the fairness regret and present new bandit algorithms to select arms under unrestricted feedback delays based on their merits. We prove that our algorithms all achieve sublinear expected reward regret and expected fairness regret, with a dependence on the quantiles of the delay distribution. We also conduct extensive experiments using synthetic and real-world data and show that our algorithms can fairly select arms with different feedback delays.
Fair Distributed Cooperative Bandit Learning on Networks for Intelligent Internet of Things Systems (Technical Report)
Mar 18, 2024
In intelligent Internet of Things (IoT) systems, edge servers within a network exchange information with their neighbors and collect data from sensors to complete delivered tasks. In this paper, we propose a multiplayer multi-armed bandit model for intelligent IoT systems to facilitate data collection and incorporate fairness considerations. In our model, we establish an effective communication protocol that helps servers cooperate with their neighbors. Then we design a distributed cooperative bandit algorithm, DC-ULCB, enabling servers to collaboratively select sensors to maximize data rates while maintaining fairness in their choices. We conduct an analysis of the reward regret and fairness regret of DC-ULCB, and prove that both regrets have logarithmic instance-dependent upper bounds. Additionally, through extensive simulations, we validate that DC-ULCB outperforms existing algorithms in maximizing reward and ensuring fairness.
Optimization-driven Machine Learning for Intelligent Reflecting Surfaces Assisted Wireless Networks
Aug 29, 2020
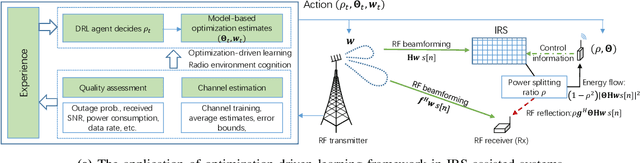
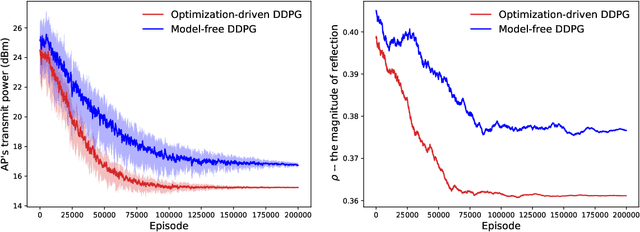
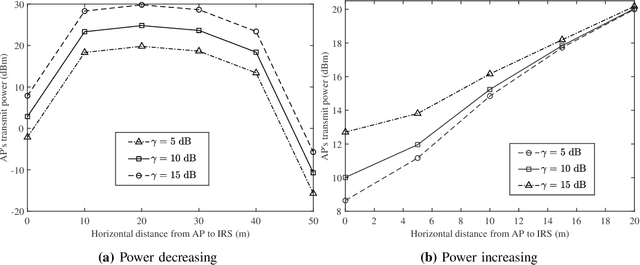
Intelligent reflecting surface (IRS) has been recently employed to reshape the wireless channels by controlling individual scattering elements' phase shifts, namely, passive beamforming. Due to the large size of scattering elements, the passive beamforming is typically challenged by the high computational complexity and inexact channel information. In this article, we focus on machine learning (ML) approaches for performance maximization in IRS-assisted wireless networks. In general, ML approaches provide enhanced flexibility and robustness against uncertain information and imprecise modeling. Practical challenges still remain mainly due to the demand for a large dataset in offline training and slow convergence in online learning. These observations motivate us to design a novel optimization-driven ML framework for IRS-assisted wireless networks, which takes both advantages of the efficiency in model-based optimization and the robustness in model-free ML approaches. By splitting the decision variables into two parts, one part is obtained by the outer-loop ML approach, while the other part is optimized efficiently by solving an approximate problem. Numerical results verify that the optimization-driven ML approach can improve both the convergence and the reward performance compared to conventional model-free learning approaches.