 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracking Objects as Pixel-wise Distributions
Jul 15, 2022
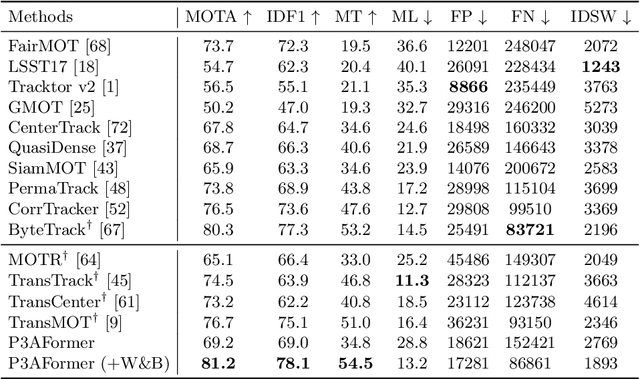
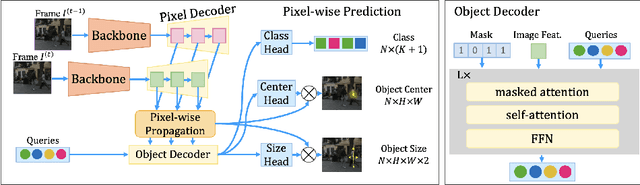
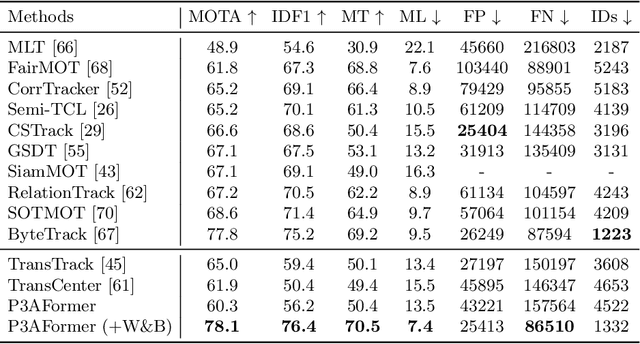
Multi-object tracking (MOT) requires detecting and associating objects through frames. Unlike tracking via detected bounding boxes or tracking objects as points, we propose tracking objects as pixel-wise distributions. We instantiate this idea on a transformer-based architecture, P3AFormer, with pixel-wise propagation, prediction, and association. P3AFormer propagates pixel-wise features guided by flow information to pass messages between frames. Furthermore, P3AFormer adopts a meta-architecture to produce multi-scale object feature maps. During inference, a pixel-wise association procedure is proposed to recover object connections through frames based on the pixel-wise prediction. P3AFormer yields 81.2\% in terms of MOTA on the MOT17 benchmark -- the first among all transformer networks to reach 80\% MOTA in literature. P3AFormer also outperforms state-of-the-arts on the MOT20 and KITTI benchmarks.
Deep Parametric 3D Filters for Joint Video Denoising and Illumination Enhancement in Video Super Resolution
Jul 05, 2022

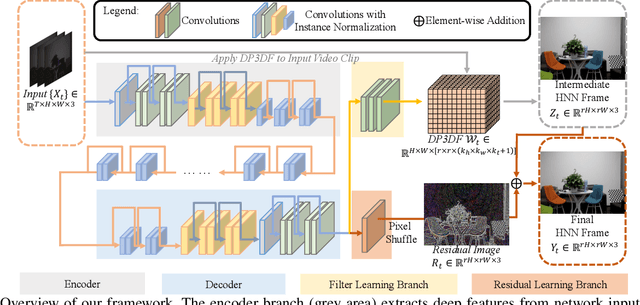
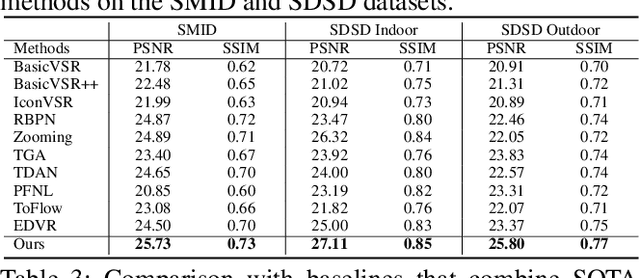
Despite the quality improvement brought by the recent methods, video super-resolution (SR) is still very challenging, especially for videos that are low-light and noisy. The current best solution is to subsequently employ best models of video SR, denoising, and illumination enhancement, but doing so often lowers the image quality, due to the inconsistency between the models. This paper presents a new parametric representation called the Deep Parametric 3D Filters (DP3DF), which incorporates local spatiotemporal information to enable simultaneous denoising, illumination enhancement, and SR efficiently in a single encoder-and-decoder network. Also, a dynamic residual frame is jointly learned with the DP3DF via a shared backbone to further boost the SR quality. We performed extensive experiments, including a large-scale user study, to show our method's effectiveness. Our method consistently surpasses the best state-of-the-art methods on all the challenging real datasets with top PSNR and user ratings, yet having a very fast run time.
PVDD: A Practical Video Denoising Dataset with Real-World Dynamic Scenes
Jul 04, 2022


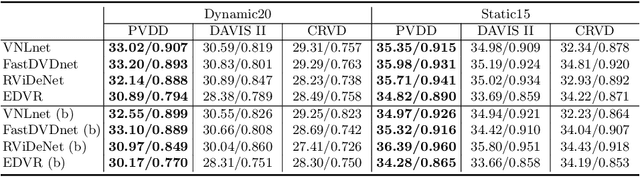
To facilitate video denoising research, we construct a compelling dataset, namely, "Practical Video Denoising Dataset" (PVDD), containing 200 noisy-clean dynamic video pairs in both sRGB and RAW format. Compared with existing datasets consisting of limited motion information, PVDD covers dynamic scenes with varying and natural motion. Different from datasets using primary Gaussian or Poisson distributions to synthesize noise in the sRGB domain, PVDD synthesizes realistic noise from the RAW domain with a physically meaningful sensor noise model followed by ISP processing. Moreover, based on this dataset, we propose a shuffle-based practical degradation model to enhance the performance of video denoising networks on real-world sRGB videos. Extensive experiments demonstrate that models trained on PVDD achieve superior denoising performance on many challenging real-world videos than on models trained on other existing datasets.
Scaling up Kernels in 3D CNNs
Jun 21, 2022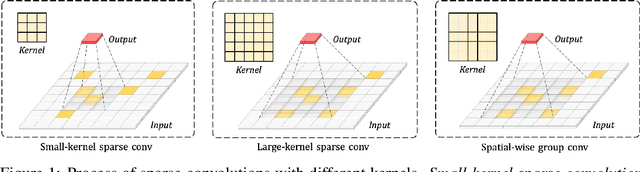
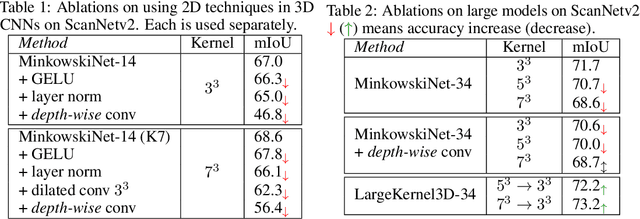

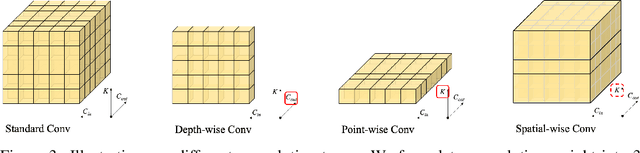
Recent advances in 2D CNNs and vision transformers (ViTs) reveal that large kernels are essential for enough receptive fields and high performance. Inspired by this literature, we examine the feasibility and challenges of 3D large-kernel designs. We demonstrate that applying large convolutional kernels in 3D CNNs has more difficulties in both performance and efficiency. Existing techniques that work well in 2D CNNs are ineffective in 3D networks, including the popular depth-wise convolutions. To overcome these obstacles, we present the spatial-wise group convolution and its large-kernel module (SW-LK block). It avoids the optimization and efficiency issues of naive 3D large kernels. Our large-kernel 3D CNN network, i.e., LargeKernel3D, yields non-trivial improvements on various 3D tasks, including semantic segmentation and object detection. Notably, it achieves 73.9% mIoU on the ScanNetv2 semantic segmentation and 72.8% NDS nuScenes object detection benchmarks, ranking 1st on the nuScenes LIDAR leaderboard. It is further boosted to 74.2% NDS with a simple multi-modal fusion. LargeKernel3D attains comparable or superior results than its CNN and transformer counterparts. For the first time, we show that large kernels are feasible and essential for 3D networks.
EfficientNeRF: Efficient Neural Radiance Fields
Jun 02, 2022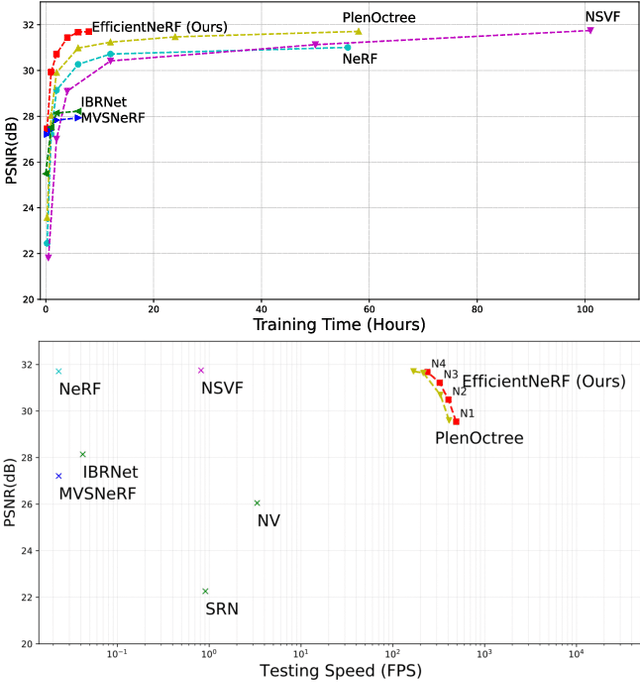

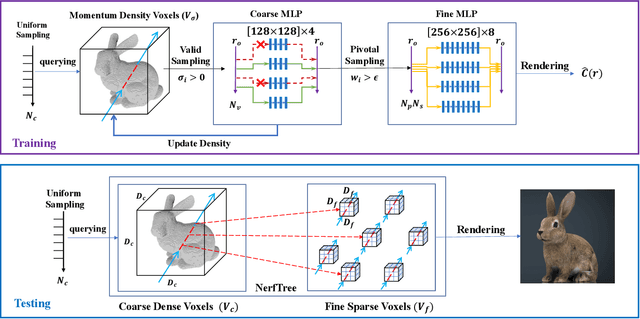
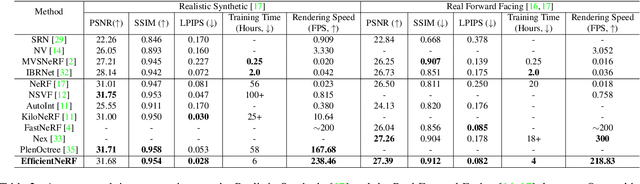
Neural Radiance Fields (NeRF) has been wildly applied to various tasks for its high-quality representation of 3D scenes. It takes long per-scene training time and per-image testing time. In this paper, we present EfficientNeRF as an efficient NeRF-based method to represent 3D scene and synthesize novel-view images. Although several ways exist to accelerate the training or testing process, it is still difficult to much reduce time for both phases simultaneously. We analyze the density and weight distribution of the sampled points then propose valid and pivotal sampling at the coarse and fine stage, respectively, to significantly improve sampling efficiency. In addition, we design a novel data structure to cache the whole scene during testing to accelerate the rendering speed. Overall, our method can reduce over 88\% of training time, reach rendering speed of over 200 FPS, while still achieving competitive accuracy. Experiments prove that our method promotes the practicality of NeRF in the real world and enables many applications.
Unifying Voxel-based Representation with Transformer for 3D Object Detection
Jun 01, 2022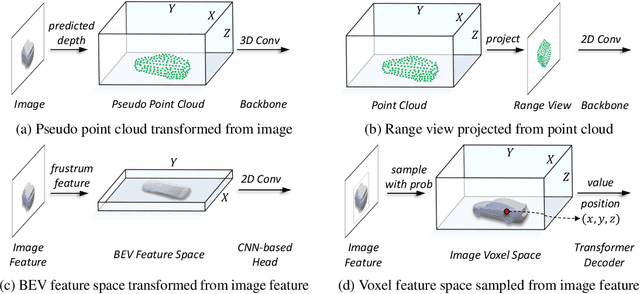
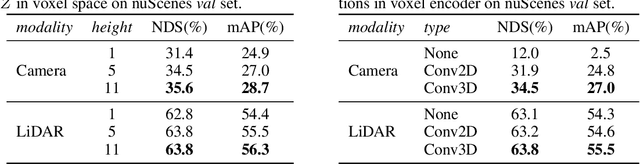
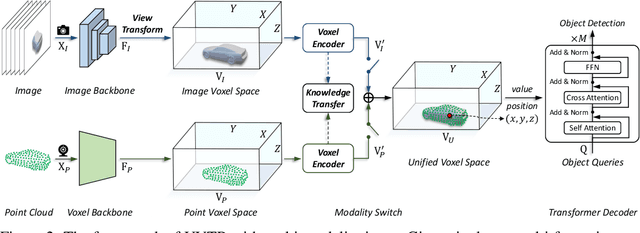
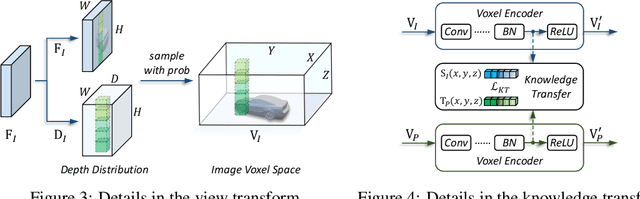
In this work, we present a unified framework for multi-modality 3D object detection, named UVTR. The proposed method aims to unify multi-modality representations in the voxel space for accurate and robust single- or cross-modality 3D detection. To this end, the modality-specific space is first designed to represent different inputs in the voxel feature space. Different from previous work, our approach preserves the voxel space without height compression to alleviate semantic ambiguity and enable spatial interactions. Benefit from the unified manner, cross-modality interaction is then proposed to make full use of inherent properties from different sensors, including knowledge transfer and modality fusion. In this way, geometry-aware expressions in point clouds and context-rich features in images are well utilized for better performance and robustness. The transformer decoder is applied to efficiently sample features from the unified space with learnable positions, which facilitates object-level interactions. In general, UVTR presents an early attempt to represent different modalities in a unified framework. It surpasses previous work in single- and multi-modality entries and achieves leading performance in the nuScenes test set with 69.7%, 55.1%, and 71.1% NDS for LiDAR, camera, and multi-modality inputs, respectively. Code is made available at https://github.com/dvlab-research/UVTR.
Voxel Field Fusion for 3D Object Detection
May 31, 2022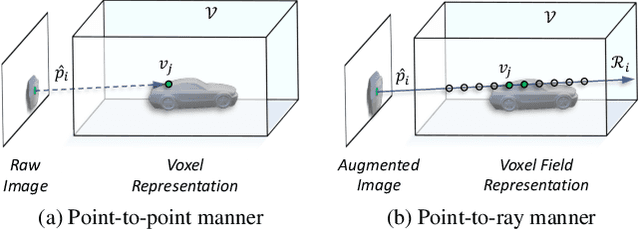

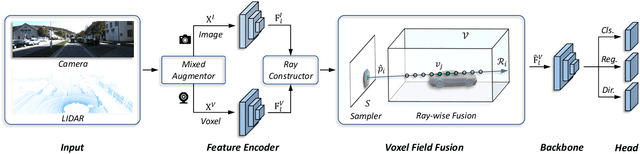
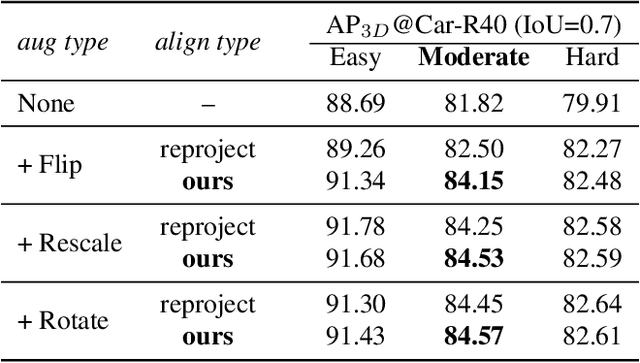
In this work, we present a conceptually simple yet effective framework for cross-modality 3D object detection, named voxel field fusion. The proposed approach aims to maintain cross-modality consistency by representing and fusing augmented image features as a ray in the voxel field. To this end, the learnable sampler is first designed to sample vital features from the image plane that are projected to the voxel grid in a point-to-ray manner, which maintains the consistency in feature representation with spatial context. In addition, ray-wise fusion is conducted to fuse features with the supplemental context in the constructed voxel field. We further develop mixed augmentor to align feature-variant transformations, which bridges the modality gap in data augmentation. The proposed framework is demonstrated to achieve consistent gains in various benchmarks and outperforms previous fusion-based methods on KITTI and nuScenes datasets. Code is made available at https://github.com/dvlab-research/VFF.
Video Frame Interpolation with Transformer
May 15, 2022
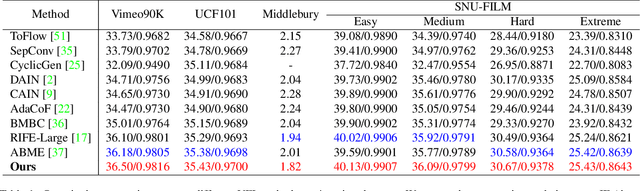
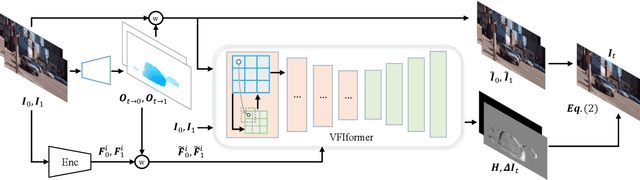

Video frame interpolation (VFI), which aims to synthesize intermediate frames of a video, has made remarkable progress with development of deep convolutional networks over past years. Existing methods built upon convolutional networks generally face challenges of handling large motion due to the locality of convolution operations. To overcome this limitation, we introduce a novel framework, which takes advantage of Transformer to model long-range pixel correlation among video frames. Further, our network is equipped with a novel cross-scale window-based attention mechanism, where cross-scale windows interact with each other. This design effectively enlarges the receptive field and aggregates multi-scale information. Extensive quantitative and qualitative experiments demonstrate that our method achieves new state-of-the-art results on various benchmarks.
Focal Sparse Convolutional Networks for 3D Object Detection
Apr 26, 2022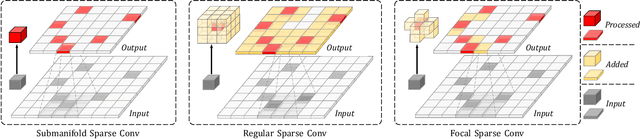
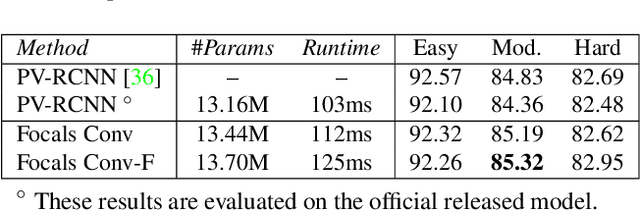

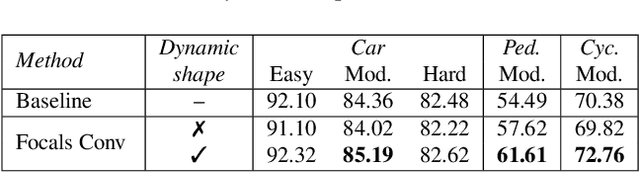
Non-uniformed 3D sparse data, e.g., point clouds or voxels in different spatial positions, make contribution to the task of 3D object detection in different ways. Existing basic components in sparse convolutional networks (Sparse CNNs) process all sparse data, regardless of regular or submanifold sparse convolution. In this paper, we introduce two new modules to enhance the capability of Sparse CNNs, both are based on making feature sparsity learnable with position-wise importance prediction. They are focal sparse convolution (Focals Conv) and its multi-modal variant of focal sparse convolution with fusion, or Focals Conv-F for short. The new modules can readily substitute their plain counterparts in existing Sparse CNNs and be jointly trained in an end-to-end fashion. For the first time, we show that spatially learnable sparsity in sparse convolution is essential for sophisticated 3D object detection. Extensive experiments on the KITTI, nuScenes and Waymo benchmarks validate the effectiveness of our approach. Without bells and whistles, our results outperform all existing single-model entries on the nuScenes test benchmark at the paper submission time. Code and models are at https://github.com/dvlab-research/FocalsConv.
DSGN++: Exploiting Visual-Spatial Relation for Stereo-based 3D Detectors
Apr 09, 2022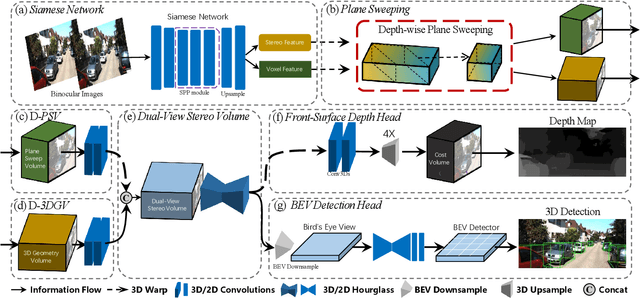
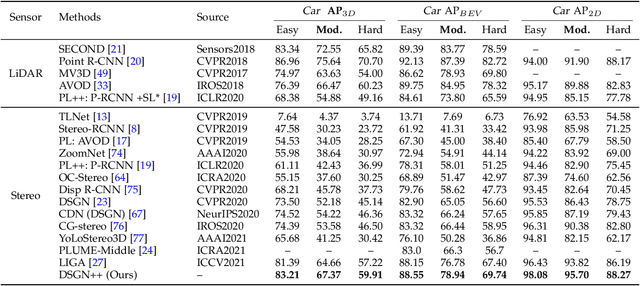
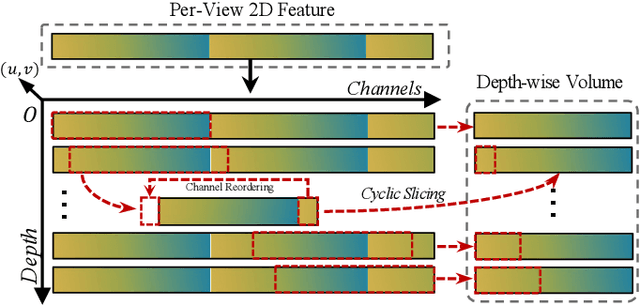
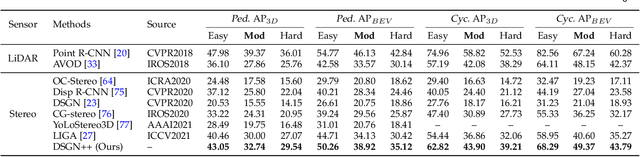
Camera-based 3D object detectors are welcome due to their wider deployment and lower price than LiDAR sensors. We revisit the prior stereo modeling DSGN about the stereo volume constructions for representing both 3D geometry and semantics. We polish the stereo modeling and propose our approach, DSGN++, aiming for improving information flow throughout the 2D-to-3D pipeline in the following three main aspects. First, to effectively lift the 2D information to stereo volume, we propose depth-wise plane sweeping (DPS) that allows denser connections and extracts depth-guided features. Second, for better grasping differently spaced features, we present a novel stereo volume -- Dual-view Stereo Volume (DSV) that integrates front-view and top-view features and reconstructs sub-voxel depth in the camera frustum. Third, as the foreground region becomes less dominant in 3D space, we firstly propose a multi-modal data editing strategy -- Stereo-LiDAR Copy-Paste, which ensures cross-modal alignment and improves data efficiency. Without bells and whistles, extensive experiments in various modality setups on the popular KITTI benchmark show that our method consistently outperforms other camera-based 3D detectors for all categories. Code will be released at https://github.com/chenyilun95/DSGN2.