 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShiftLUT: Spatial Shift Enhanced Look-Up Tables for Efficient Image Restoration
Mar 03, 2026Look-Up Table based methods have emerged as a promising direction for efficient image restoration tasks. Recent LUT-based methods focus on improving their performance by expanding the receptive field. However, they inevitably introduce extra computational and storage overhead, which hinders their deployment in edge devices. To address this issue, we propose ShiftLUT, a novel framework that attains the largest receptive field among all LUT-based methods while maintaining high efficiency. Our key insight lies in three complementary components. First, Learnable Spatial Shift module (LSS) is introduced to expand the receptive field by applying learnable, channel-wise spatial offsets on feature maps. Second, we propose an asymmetric dual-branch architecture that allocates more computation to the information-dense branch, substantially reducing inference latency without compromising restoration quality. Finally, we incorporate a feature-level LUT compression strategy called Error-bounded Adaptive Sampling (EAS) to minimize the storage overhead. Compared to the previous state-of-the-art method TinyLUT, ShiftLUT achieves a 3.8$\times$ larger receptive field and improves an average PSNR by over 0.21 dB across multiple standard benchmarks, while maintaining a small storage size and inference time. The code is available at: https://github.com/Sailor-t/ShiftLUT .
PVDD: A Practical Video Denoising Dataset with Real-World Dynamic Scenes
Jul 04, 2022


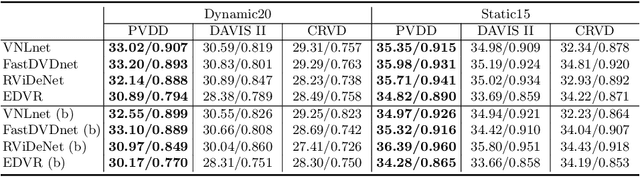
To facilitate video denoising research, we construct a compelling dataset, namely, "Practical Video Denoising Dataset" (PVDD), containing 200 noisy-clean dynamic video pairs in both sRGB and RAW format. Compared with existing datasets consisting of limited motion information, PVDD covers dynamic scenes with varying and natural motion. Different from datasets using primary Gaussian or Poisson distributions to synthesize noise in the sRGB domain, PVDD synthesizes realistic noise from the RAW domain with a physically meaningful sensor noise model followed by ISP processing. Moreover, based on this dataset, we propose a shuffle-based practical degradation model to enhance the performance of video denoising networks on real-world sRGB videos. Extensive experiments demonstrate that models trained on PVDD achieve superior denoising performance on many challenging real-world videos than on models trained on other existing datasets.