 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Agent Traces to Trust: Evidence Tracing and Execution Provenance in LLM Agents
Jun 03, 2026Large language model (LLM)-based agents increasingly solve complex tasks by interacting with external tools, retrieval systems, memory modules, environments, and other agents. These capabilities expand agent autonomy, but also make agent behavior harder to verify, debug, and audit. Final-answer accuracy alone cannot explain how an output was produced, which evidence supported each claim, whether tool calls were justified, how memory influenced later decisions, or where execution failures originated. Evidence tracing and execution provenance address this gap by modeling how retrieved evidence, tool outputs, memory items, environment observations, intermediate claims, actions, and final answers are connected throughout agent execution. This survey provides a systematic review and conceptual framework for evidence tracing and execution provenance in LLM agents. We organize related work around a unified provenance perspective that connects retrieval grounding, claim support, tool-use safety, memory lineage, observability, debugging, audit, and recovery. We introduce a taxonomy covering trace sources, evidence and execution units, provenance relations, tracing granularity and timing, representation forms, and trust functions. We review key methodological directions, including provenance representation, evidence attribution, tool-use provenance, runtime guardrails, provenance-bearing memory, trace-based observability, and failure diagnosis. We also map existing benchmarks, datasets, and evaluation metrics to provenance-related capabilities, and discuss how evaluation can move from final-answer correctness toward process-level accountability. Finally, we outline open challenges, including unified trace schemas, claim-level and semantic provenance, provenance-aware safety mechanisms, realistic execution-trace benchmarks, recovery-oriented evaluation, and privacy-aware audit infrastructure.
Distance-Aware Joint Spatio-Temporal Graph Contrastive Learning for Major Depressive Disorder Diagnosis
May 22, 2026Major depressive disorder (MDD) is a common neuropsychiatric condition whose accurate diagnosis from resting-state functional magnetic resonance imaging (rs-fMRI) remains difficult. Dynamic functional connectivity (DFC) captures time-varying interactions among brain regions and provides rich spatio-temporal information, yet current DFC-based methods face three limitations: sliding-window Pearson correlation yields noisy estimates sensitive to window length and motion artifacts; correlation-derived node features do not fully exploit frequency-domain properties of blood-oxygen-level-dependent (BOLD) signals; and most spatio-temporal graph models handle spatial structure and temporal dynamics in separate stages, restricting their ability to represent coupled brain network evolution. To overcome these issues, we reformulate DFC learning as joint spatio-temporal graph representation learning under a Hawkes-process-inspired temporal dependency prior and propose HWSTCL, a two-stage framework built on a reliability-refined joint spatio-temporal graph with a kernel-weighted pretraining objective. Within each temporal window, BOLD signals are encoded as spectral node descriptors and functional edges are refined by an exponential distance-decay prior that down-weights less reliable long-range connections. The joint graph is then formed by linking each region to itself across future windows through a Hawkes-inspired exponential kernel, allowing spatial and temporal information to be propagated together during message passing. A kernel-weighted contrastive objective further promotes temporal consistency for each region across windows while reducing redundant similarity between different regions. Experiments on a benchmark rs-fMRI dataset show that HWSTCL outperforms recent baselines and yields coherent spatio-temporal representations for MDD diagnosis.
fMRI-Diffusion: Generating fMRI Time Series Via a Temporal Transformer Diffusion Model for Major Depressive Disorder Diagnosis
May 22, 2026Diagnosing Major Depressive Disorder (MDD) from functional magnetic resonance imaging (fMRI) using functional connectivity (FC) analysis requires large amounts of labeled data that are scarce in clinical settings. Existing augmentation methods synthesize FC matrices, which compress fMRI recordings into static pairwise summaries and discard temporal information. We propose fMRI-Diffusion, a framework that synthesizes region-of-interest (ROI)-level fMRI time series rather than FC matrices. A Temporal Transformer serves as the denoising network within a denoising diffusion probabilistic model, treating each time point as a token to capture temporal dependencies through self-attention. A supervised pretraining strategy initializes the Transformer with task-relevant representations before diffusion training, and FC matrices are derived from the synthesized time series for classification. Experiments on the REST-meta-MDD dataset show that augmenting training data with synthetic time series consistently improves diagnostic accuracy across ten classifiers, six parcellation atlases, and three acquisition sites. The method outperforms five recent FC-based synthesis approaches, with accuracy gains of up to 3.7 percentage points over the strongest baseline. Ablation studies confirm the contributions of both the Transformer-based denoiser and the pretraining strategy. Distributional fidelity metrics remain below 0.06 across all conditions, indicating close agreement between real and synthetic distributions. These findings suggest that synthesizing fMRI time series before FC computation preserves temporal information lost in matrix-level augmentation and provides a practical strategy for MDD diagnosis under limited data.
NCSTR: Node-Centric Decoupled Spatio-Temporal Reasoning for Video-based Human Pose Estimation
Mar 20, 2026Video-based human pose estimation remains challenged by motion blur, occlusion, and complex spatiotemporal dynamics. Existing methods often rely on heatmaps or implicit spatio-temporal feature aggregation, which limits joint topology expressiveness and weakens cross-frame consistency. To address these problems, we propose a novel node-centric framework that explicitly integrates visual, temporal, and structural reasoning for accurate pose estimation. First, we design a visuo-temporal velocity-based joint embedding that fuses sub-pixel joint cues and inter-frame motion to build appearance- and motion-aware representations. Then, we introduce an attention-driven pose-query encoder, which applies attention over joint-wise heatmaps and frame-wise features to map the joint representations into a pose-aware node space, generating image-conditioned joint-aware node embeddings. Building upon these node embeddings, we propose a dual-branch decoupled spatio-temporal attention graph that models temporal propagation and spatial constraint reasoning in specialized local and global branches. Finally, a node-space expert fusion module is proposed to adaptively fuse the complementary outputs from both branches, integrating local and global cues for final joint predictions. Extensive experiments on three widely used video pose benchmarks demonstrate that our method outperforms state-of-the-art methods. The results highlight the value of explicit node-centric reasoning, offering a new perspective for advancing video-based human pose estimation.
Prompt-Free Lightweight SAM Adaptation for Histopathology Nuclei Segmentation with Strong Cross-Dataset Generalization
Mar 20, 2026Histopathology nuclei segmentation is crucial for quantitative tissue analysis and cancer diagnosis. Although existing segmentation methods have achieved strong performance, they are often computationally heavy and show limited generalization across datasets, which constrains their practical deployment. Recent SAM-based approaches have shown great potential in general and medical imaging, but typically rely on prompt guidance or complex decoders, making them less suitable for histopathology images with dense nuclei and heterogeneous appearances. We propose a prompt-free and lightweight SAM adaptation that leverages multi-level encoder features and residual decoding for accurate and efficient nuclei segmentation. The framework fine-tunes only LoRA modules within the frozen SAM encoder, requiring just 4.1M trainable parameters. Experiments on three benchmark datasets TNBC, MoNuSeg, and PanNuke demonstrate state-of-the-art performance and strong cross-dataset generalization, highlighting the effectiveness and practicality of the proposed framework for histopathology applications.
DCG-Net: Dual Cross-Attention with Concept-Value Graph Reasoning for Interpretable Medical Diagnosis
Mar 20, 2026Deep learning models have achieved strong performance in medical image analysis, but their internal decision processes remain difficult to interpret. Concept Bottleneck Models (CBMs) partially address this limitation by structuring predictions through human-interpretable clinical concepts. However, existing CBMs typically overlook the contextual dependencies among concepts. To address these issues, we propose an end-to-end interpretable framework \emph{DCG-Net} that integrates multimodal alignment with structured concept reasoning. DCG-Net introduces a Dual Cross-Attention module that replaces cosine similarity matching with bidirectional attention between visual tokens and canonicalized textual concept-value prototypes, enabling spatially localized evidence attribution. To capture the relational structure inherent to clinical concepts, we develop a Parametric Concept Graph initialized with Positive Pointwise Mutual Information priors and refined through sparsity-controlled message passing. This formulation models inter-concept dependencies in a manner consistent with clinical domain knowledge. Experiments on white blood cell morphology and skin lesion diagnosis demonstrate that DCG-Net achieves state-of-the-art classification performance while producing clinically interpretable diagnostic explanations.
SR3R: Rethinking Super-Resolution 3D Reconstruction With Feed-Forward Gaussian Splatting
Feb 27, 20263D super-resolution (3DSR) aims to reconstruct high-resolution (HR) 3D scenes from low-resolution (LR) multi-view images. Existing methods rely on dense LR inputs and per-scene optimization, which restricts the high-frequency priors for constructing HR 3D Gaussian Splatting (3DGS) to those inherited from pretrained 2D super-resolution (2DSR) models. This severely limits reconstruction fidelity, cross-scene generalization, and real-time usability. We propose to reformulate 3DSR as a direct feed-forward mapping from sparse LR views to HR 3DGS representations, enabling the model to autonomously learn 3D-specific high-frequency geometry and appearance from large-scale, multi-scene data. This fundamentally changes how 3DSR acquires high-frequency knowledge and enables robust generalization to unseen scenes. Specifically, we introduce SR3R, a feed-forward framework that directly predicts HR 3DGS representations from sparse LR views via the learned mapping network. To further enhance reconstruction fidelity, we introduce Gaussian offset learning and feature refinement, which stabilize reconstruction and sharpen high-frequency details. SR3R is plug-and-play and can be paired with any feed-forward 3DGS reconstruction backbone: the backbone provides an LR 3DGS scaffold, and SR3R upscales it to an HR 3DGS. Extensive experiments across three 3D benchmarks demonstrate that SR3R surpasses state-of-the-art (SOTA) 3DSR methods and achieves strong zero-shot generalization, even outperforming SOTA per-scene optimization methods on unseen scenes.
Intention Knowledge Graph Construction for User Intention Relation Modeling
Dec 16, 2024Understanding user intentions is challenging for online platforms. Recent work on intention knowledge graphs addresses this but often lacks focus on connecting intentions, which is crucial for modeling user behavior and predicting future actions. This paper introduces a framework to automatically generate an intention knowledge graph, capturing connections between user intentions. Using the Amazon m2 dataset, we construct an intention graph with 351 million edges, demonstrating high plausibility and acceptance. Our model effectively predicts new session intentions and enhances product recommendations, outperforming previous state-of-the-art methods and showcasing the approach's practical utility.
Privacy-Preserving in Medical Image Analysis: A Review of Methods and Applications
Dec 05, 2024
With the rapid advancement of artificial intelligence and deep learning, medical image analysis has become a critical tool in modern healthcare, significantly improving diagnostic accuracy and efficiency. However, AI-based methods also raise serious privacy concerns, as medical images often contain highly sensitive patient information. This review offers a comprehensive overview of privacy-preserving techniques in medical image analysis, including encryption, differential privacy, homomorphic encryption, federated learning, and generative adversarial networks. We explore the application of these techniques across various medical image analysis tasks, such as diagnosis, pathology, and telemedicine. Notably, we organizes the review based on specific challenges and their corresponding solutions in different medical image analysis applications, so that technical applications are directly aligned with practical issues, addressing gaps in the current research landscape. Additionally, we discuss emerging trends, such as zero-knowledge proofs and secure multi-party computation, offering insights for future research. This review serves as a valuable resource for researchers and practitioners and can help advance privacy-preserving in medical image analysis.
PowerFDNet: Deep Learning-Based Stealthy False Data Injection Attack Detection for AC-model Transmission Systems
Jul 15, 2022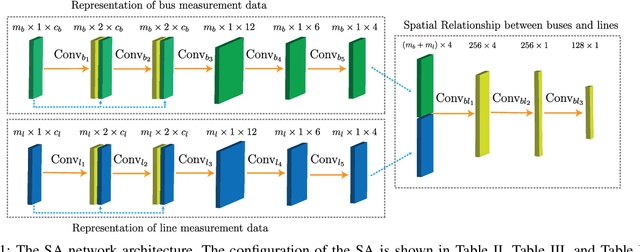
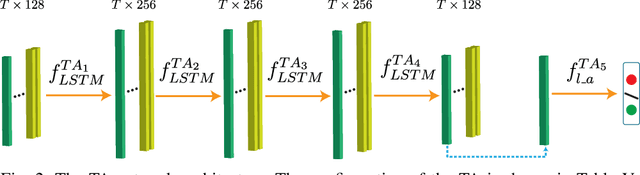
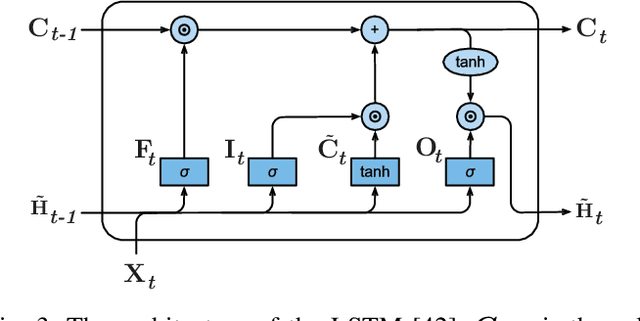
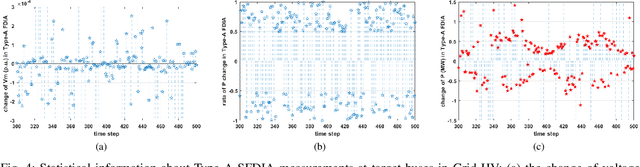
Recent studies have demonstrated that smart grids are vulnerable to stealthy false data injection attacks (SFDIAs), as SFDIAs can bypass residual-based bad data detection mechanisms. The SFDIA detection has become one of the focuses of smart grid research. Methods based on deep learning technology have shown promising accuracy in the detection of SFDIAs. However, most existing methods rely on the temporal structure of a sequence of measurements but do not take account of the spatial structure between buses and transmission lines. To address this issue, we propose a spatiotemporal deep network, PowerFDNet, for the SFDIA detection in AC-model power grids. The PowerFDNet consists of two sub-architectures: spatial architecture (SA) and temporal architecture (TA). The SA is aimed at extracting representations of bus/line measurements and modeling the spatial structure based on their representations. The TA is aimed at modeling the temporal structure of a sequence of measurements. Therefore, the proposed PowerFDNet can effectively model the spatiotemporal structure of measurements. Case studies on the detection of SFDIAs on the benchmark smart grids show that the PowerFDNet achieved significant improvement compared with the state-of-the-art SFDIA detection methods. In addition, an IoT-oriented lightweight prototype of size 52 MB is implemented and tested for mobile devices, which demonstrates the potential applications on mobile devices. The trained model will be available at \textit{https://github.com/FrankYinXF/PowerFDNet}.