 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuardAgent: Safeguard LLM Agents by a Guard Agent via Knowledge-Enabled Reasoning
Jun 13, 2024



The rapid advancement of large language models (LLMs) has catalyzed the deployment of LLM-powered agents across numerous applications, raising new concerns regarding their safety and trustworthiness. Existing methods for enhancing the safety of LLMs are not directly transferable to LLM-powered agents due to their diverse objectives and output modalities. In this paper, we propose GuardAgent, the first LLM agent as a guardrail to other LLM agents. Specifically, GuardAgent oversees a target LLM agent by checking whether its inputs/outputs satisfy a set of given guard requests defined by the users. GuardAgent comprises two steps: 1) creating a task plan by analyzing the provided guard requests, and 2) generating guardrail code based on the task plan and executing the code by calling APIs or using external engines. In both steps, an LLM is utilized as the core reasoning component, supplemented by in-context demonstrations retrieved from a memory module. Such knowledge-enabled reasoning allows GuardAgent to understand various textual guard requests and accurately "translate" them into executable code that provides reliable guardrails. Furthermore, GuardAgent is equipped with an extendable toolbox containing functions and APIs and requires no additional LLM training, which underscores its generalization capabilities and low operational overhead. Additionally, we propose two novel benchmarks: an EICU-AC benchmark for assessing privacy-related access control for healthcare agents and a Mind2Web-SC benchmark for safety evaluation for web agents. We show the effectiveness of GuardAgent on these two benchmarks with 98.7% and 90.0% accuracy in moderating invalid inputs and outputs for the two types of agents, respectively. We also show that GuardAgent is able to define novel functions in adaption to emergent LLM agents and guard requests, which underscores its strong generalization capabilities.
Chemistry3D: Robotic Interaction Benchmark for Chemistry Experiments
Jun 12, 2024The advent of simulation engines has revolutionized learning and operational efficiency for robots, offering cost-effective and swift pipelines. However, the lack of a universal simulation platform tailored for chemical scenarios impedes progress in robotic manipulation and visualization of reaction processes. Addressing this void, we present Chemistry3D, an innovative toolkit that integrates extensive chemical and robotic knowledge. Chemistry3D not only enables robots to perform chemical experiments but also provides real-time visualization of temperature, color, and pH changes during reactions. Built on the NVIDIA Omniverse platform, Chemistry3D offers interfaces for robot operation, visual inspection, and liquid flow control, facilitating the simulation of special objects such as liquids and transparent entities. Leveraging this toolkit, we have devised RL tasks, object detection, and robot operation scenarios. Additionally, to discern disparities between the rendering engine and the real world, we conducted transparent object detection experiments using Sim2Real, validating the toolkit's exceptional simulation performance. The source code is available at https://github.com/huangyan28/Chemistry3D, and a related tutorial can be found at https://www.omni-chemistry.com.
Unleashing the Denoising Capability of Diffusion Prior for Solving Inverse Problems
Jun 11, 2024The recent emergence of diffusion models has significantly advanced the precision of learnable priors, presenting innovative avenues for addressing inverse problems. Since inverse problems inherently entail maximum a posteriori estimation, previous works have endeavored to integrate diffusion priors into the optimization frameworks. However, prevailing optimization-based inverse algorithms primarily exploit the prior information within the diffusion models while neglecting their denoising capability. To bridge this gap, this work leverages the diffusion process to reframe noisy inverse problems as a two-variable constrained optimization task by introducing an auxiliary optimization variable. By employing gradient truncation, the projection gradient descent method is efficiently utilized to solve the corresponding optimization problem. The proposed algorithm, termed ProjDiff, effectively harnesses the prior information and the denoising capability of a pre-trained diffusion model within the optimization framework. Extensive experiments on the image restoration tasks and source separation and partial generation tasks demonstrate that ProjDiff exhibits superior performance across various linear and nonlinear inverse problems, highlighting its potential for practical applications. Code is available at https://github.com/weigerzan/ProjDiff/.
ChatGPT as the Marketplace of Ideas: Should Truth-Seeking Be the Goal of AI Content Governance?
May 28, 2024As one of the most enduring metaphors within legal discourse, the marketplace of ideas has wielded considerable influence over the jurisprudential landscape for decades. A century after the inception of this theory, ChatGPT emerged as a revolutionary technological advancement in the twenty-first century. This research finds that ChatGPT effectively manifests the marketplace metaphor. It not only instantiates the promises envisaged by generations of legal scholars but also lays bare the perils discerned through sustained academic critique. Specifically, the workings of ChatGPT and the marketplace of ideas theory exhibit at least four common features: arena, means, objectives, and flaws. These shared attributes are sufficient to render ChatGPT historically the most qualified engine for actualizing the marketplace of ideas theory. The comparison of the marketplace theory and ChatGPT merely marks a starting point. A more meaningful undertaking entails reevaluating and reframing both internal and external AI policies by referring to the accumulated experience, insights, and suggestions researchers have raised to fix the marketplace theory. Here, a pivotal issue is: should truth-seeking be set as the goal of AI content governance? Given the unattainability of the absolute truth-seeking goal, I argue against adopting zero-risk policies. Instead, a more judicious approach would be to embrace a knowledge-based alternative wherein large language models (LLMs) are trained to generate competing and divergent viewpoints based on sufficient justifications. This research also argues that so-called AI content risks are not created by AI companies but are inherent in the entire information ecosystem. Thus, the burden of managing these risks should be distributed among different social actors, rather than being solely shouldered by chatbot companies.
* 27 pages, 3 figures
ChatScene: Knowledge-Enabled Safety-Critical Scenario Generation for Autonomous Vehicles
May 22, 2024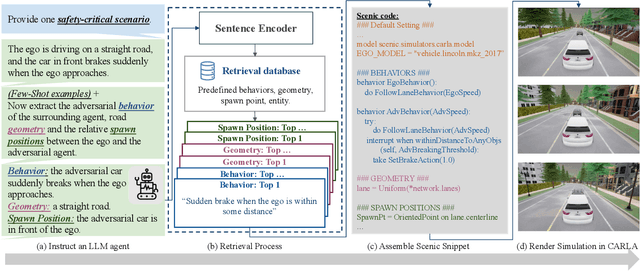
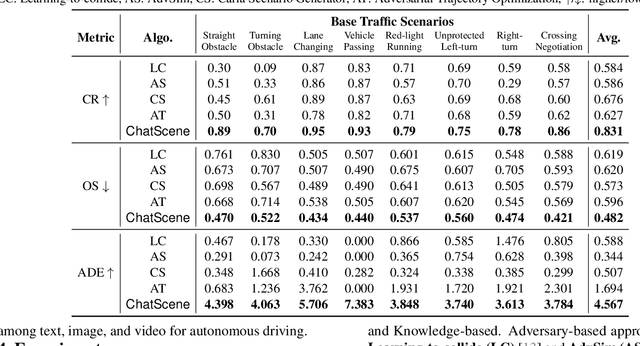
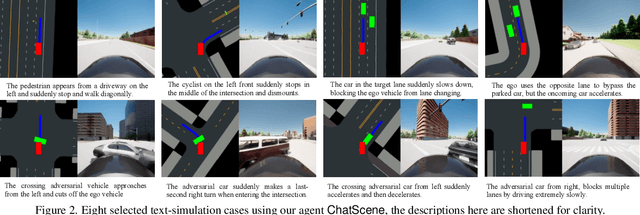
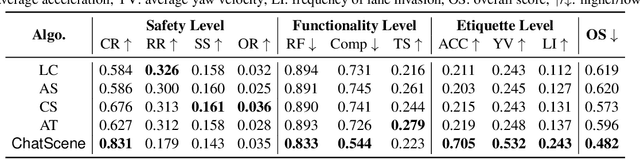
We present ChatScene, a Large Language Model (LLM)-based agent that leverages the capabilities of LLMs to generate safety-critical scenarios for autonomous vehicles. Given unstructured language instructions, the agent first generates textually described traffic scenarios using LLMs. These scenario descriptions are subsequently broken down into several sub-descriptions for specified details such as behaviors and locations of vehicles. The agent then distinctively transforms the textually described sub-scenarios into domain-specific languages, which then generate actual code for prediction and control in simulators, facilitating the creation of diverse and complex scenarios within the CARLA simulation environment. A key part of our agent is a comprehensive knowledge retrieval component, which efficiently translates specific textual descriptions into corresponding domain-specific code snippets by training a knowledge database containing the scenario description and code pairs. Extensive experimental results underscore the efficacy of ChatScene in improving the safety of autonomous vehicles. For instance, the scenarios generated by ChatScene show a 15% increase in collision rates compared to state-of-the-art baselines when tested against different reinforcement learning-based ego vehicles. Furthermore, we show that by using our generated safety-critical scenarios to fine-tune different RL-based autonomous driving models, they can achieve a 9% reduction in collision rates, surpassing current SOTA methods. ChatScene effectively bridges the gap between textual descriptions of traffic scenarios and practical CARLA simulations, providing a unified way to conveniently generate safety-critical scenarios for safety testing and improvement for AVs.
A Unified Linear Programming Framework for Offline Reward Learning from Human Demonstrations and Feedback
May 20, 2024

Inverse Reinforcement Learning (IRL) and Reinforcement Learning from Human Feedback (RLHF) are pivotal methodologies in reward learning, which involve inferring and shaping the underlying reward function of sequential decision-making problems based on observed human demonstrations and feedback. Most prior work in reward learning has relied on prior knowledge or assumptions about decision or preference models, potentially leading to robustness issues. In response, this paper introduces a novel linear programming (LP) framework tailored for offline reward learning. Utilizing pre-collected trajectories without online exploration, this framework estimates a feasible reward set from the primal-dual optimality conditions of a suitably designed LP, and offers an optimality guarantee with provable sample efficiency. Our LP framework also enables aligning the reward functions with human feedback, such as pairwise trajectory comparison data, while maintaining computational tractability and sample efficiency. We demonstrate that our framework potentially achieves better performance compared to the conventional maximum likelihood estimation (MLE) approach through analytical examples and numerical experiments.
CoR-GS: Sparse-View 3D Gaussian Splatting via Co-Regularization
May 20, 2024



3D Gaussian Splatting (3DGS) creates a radiance field consisting of 3D Gaussians to represent a scene. With sparse training views, 3DGS easily suffers from overfitting, negatively impacting the reconstruction quality. This paper introduces a new co-regularization perspective for improving sparse-view 3DGS. When training two 3D Gaussian radiance fields with the same sparse views of a scene, we observe that the two radiance fields exhibit \textit{point disagreement} and \textit{rendering disagreement} that can unsupervisedly predict reconstruction quality, stemming from the sampling implementation in densification. We further quantify the point disagreement and rendering disagreement by evaluating the registration between Gaussians' point representations and calculating differences in their rendered pixels. The empirical study demonstrates the negative correlation between the two disagreements and accurate reconstruction, which allows us to identify inaccurate reconstruction without accessing ground-truth information. Based on the study, we propose CoR-GS, which identifies and suppresses inaccurate reconstruction based on the two disagreements: (\romannumeral1) Co-pruning considers Gaussians that exhibit high point disagreement in inaccurate positions and prunes them. (\romannumeral2) Pseudo-view co-regularization considers pixels that exhibit high rendering disagreement are inaccurately rendered and suppress the disagreement. Results on LLFF, Mip-NeRF360, DTU, and Blender demonstrate that CoR-GS effectively regularizes the scene geometry, reconstructs the compact representations, and achieves state-of-the-art novel view synthesis quality under sparse training views.
Additive-Effect Assisted Learning
May 13, 2024It is quite popular nowadays for researchers and data analysts holding different datasets to seek assistance from each other to enhance their modeling performance. We consider a scenario where different learners hold datasets with potentially distinct variables, and their observations can be aligned by a nonprivate identifier. Their collaboration faces the following difficulties: First, learners may need to keep data values or even variable names undisclosed due to, e.g., commercial interest or privacy regulations; second, there are restrictions on the number of transmission rounds between them due to e.g., communication costs. To address these challenges, we develop a two-stage assisted learning architecture for an agent, Alice, to seek assistance from another agent, Bob. In the first stage, we propose a privacy-aware hypothesis testing-based screening method for Alice to decide on the usefulness of the data from Bob, in a way that only requires Bob to transmit sketchy data. Once Alice recognizes Bob's usefulness, Alice and Bob move to the second stage, where they jointly apply a synergistic iterative model training procedure. With limited transmissions of summary statistics, we show that Alice can achieve the oracle performance as if the training were from centralized data, both theoretically and numerically.
Uniformly Stable Algorithms for Adversarial Training and Beyond
May 03, 2024



In adversarial machine learning, neural networks suffer from a significant issue known as robust overfitting, where the robust test accuracy decreases over epochs (Rice et al., 2020). Recent research conducted by Xing et al.,2021; Xiao et al., 2022 has focused on studying the uniform stability of adversarial training. Their investigations revealed that SGD-based adversarial training fails to exhibit uniform stability, and the derived stability bounds align with the observed phenomenon of robust overfitting in experiments. This motivates us to develop uniformly stable algorithms specifically tailored for adversarial training. To this aim, we introduce Moreau envelope-$\mathcal{A}$, a variant of the Moreau Envelope-type algorithm. We employ a Moreau envelope function to reframe the original problem as a min-min problem, separating the non-strong convexity and non-smoothness of the adversarial loss. Then, this approach alternates between solving the inner and outer minimization problems to achieve uniform stability without incurring additional computational overhead. In practical scenarios, we show the efficacy of ME-$\mathcal{A}$ in mitigating the issue of robust overfitting. Beyond its application in adversarial training, this represents a fundamental result in uniform stability analysis, as ME-$\mathcal{A}$ is the first algorithm to exhibit uniform stability for weakly-convex, non-smooth problems.
TalkingGaussian: Structure-Persistent 3D Talking Head Synthesis via Gaussian Splatting
Apr 23, 2024



Radiance fields have demonstrated impressive performance in synthesizing lifelike 3D talking heads. However, due to the difficulty in fitting steep appearance changes, the prevailing paradigm that presents facial motions by directly modifying point appearance may lead to distortions in dynamic regions. To tackle this challenge, we introduce TalkingGaussian, a deformation-based radiance fields framework for high-fidelity talking head synthesis. Leveraging the point-based Gaussian Splatting, facial motions can be represented in our method by applying smooth and continuous deformations to persistent Gaussian primitives, without requiring to learn the difficult appearance change like previous methods. Due to this simplification, precise facial motions can be synthesized while keeping a highly intact facial feature. Under such a deformation paradigm, we further identify a face-mouth motion inconsistency that would affect the learning of detailed speaking motions. To address this conflict, we decompose the model into two branches separately for the face and inside mouth areas, therefore simplifying the learning tasks to help reconstruct more accurate motion and structure of the mouth region. Extensive experiments demonstrate that our method renders high-quality lip-synchronized talking head videos, with better facial fidelity and higher efficiency compared with previous methods.