 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Variance Reduced Primal Dual Algorithms for Empirical Composition Optimization
Jul 22, 2019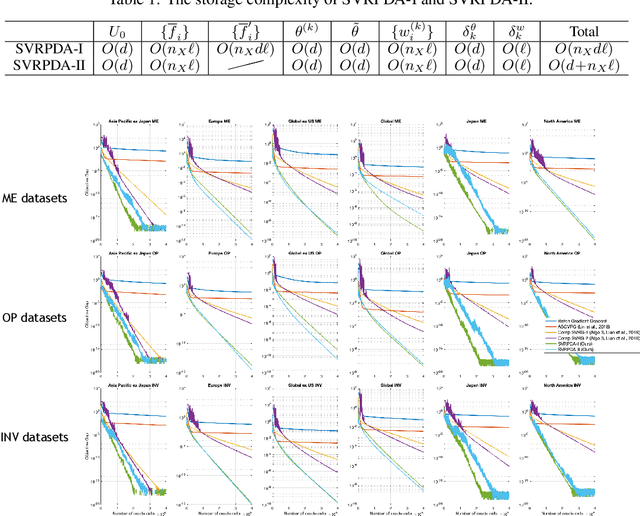
We consider a generic empirical composition optimization problem, where there are empirical averages present both outside and inside nonlinear loss functions. Such a problem is of interest in various machine learning applications, and cannot be directly solved by standard methods such as stochastic gradient descent (SGD). We take a novel approach to solving this problem by reformulating the original minimization objective into an equivalent min-max objective, which brings out all the empirical averages that are originally inside the nonlinear loss functions. We exploit the rich structures of the reformulated problem and develop a stochastic primal-dual algorithm, SVRPDA-I, to solve the problem efficiently. We carry out extensive theoretical analysis of the proposed algorithm, obtaining the convergence rate, the total computation complexity and the storage complexity. In particular, the algorithm is shown to converge at a linear rate when the problem is strongly convex. Moreover, we also develop an approximate version of the algorithm, SVRPDA-II, which further reduces the memory requirement. Finally, we evaluate the performance of our algorithms on several real-world benchmarks, and experimental results show that the proposed algorithms significantly outperform existing techniques.
Semantically Conditioned Dialog Response Generation via Hierarchical Disentangled Self-Attention
Jun 09, 2019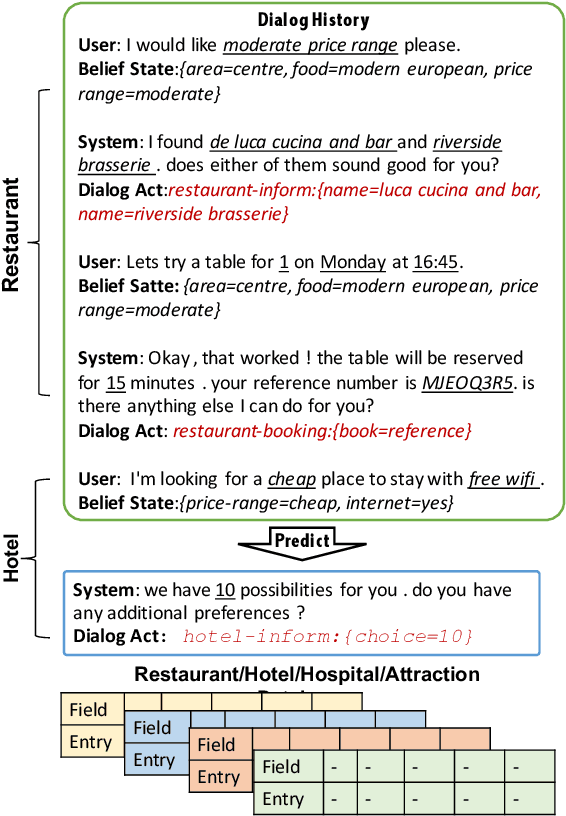

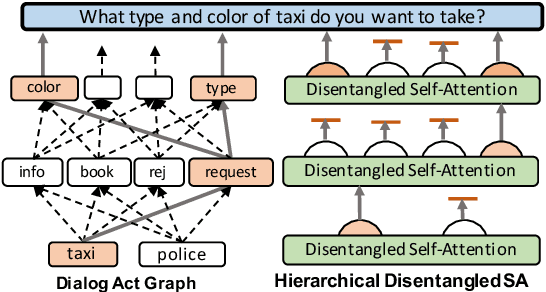
Semantically controlled neural response generation on limited-domain has achieved great performance. However, moving towards multi-domain large-scale scenarios are shown to be difficult because the possible combinations of semantic inputs grow exponentially with the number of domains. To alleviate such scalability issue, we exploit the structure of dialog acts to build a multi-layer hierarchical graph, where each act is represented as a root-to-leaf route on the graph. Then, we incorporate such graph structure prior as an inductive bias to build a hierarchical disentangled self-attention network, where we disentangle attention heads to model designated nodes on the dialog act graph. By activating different (disentangled) heads at each layer, combinatorially many dialog act semantics can be modeled to control the neural response generation. On the large-scale Multi-Domain-WOZ dataset, our model can yield a significant improvement over the baselines on various automatic and human evaluation metrics.
From Caesar Cipher to Unsupervised Learning: A New Method for Classifier Parameter Estimation
Jun 06, 2019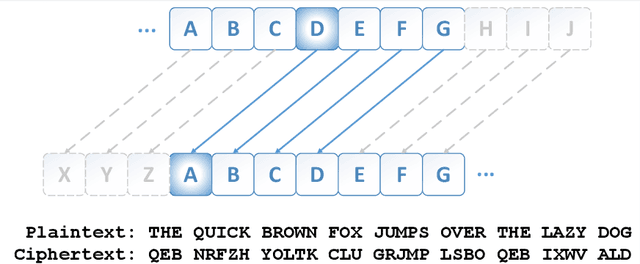

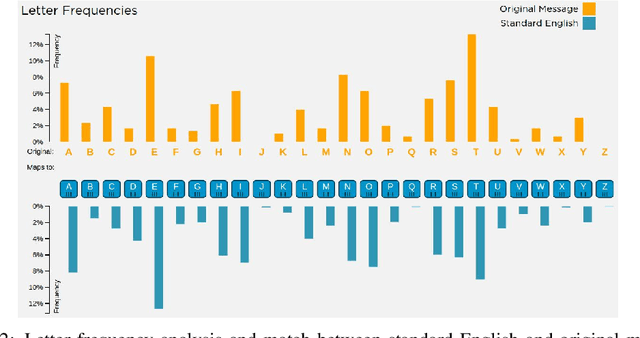
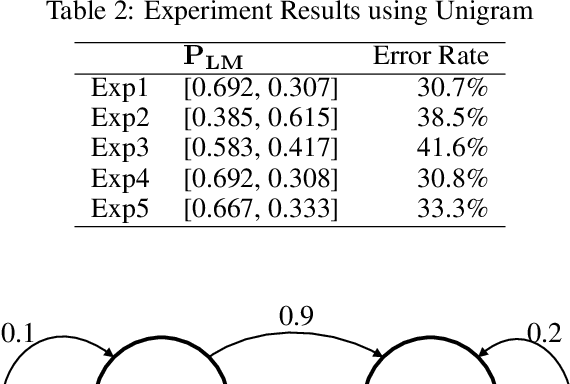
Many important classification problems, such as object classification, speech recognition, and machine translation, have been tackled by the supervised learning paradigm in the past, where training corpora of parallel input-output pairs are required with high cost. To remove the need for the parallel training corpora has practical significance for real-world applications, and it is one of the main goals of unsupervised learning. Recently, encouraging progress in unsupervised learning for solving such classification problems has been made and the nature of the challenges has been clarified. In this article, we review this progress and disseminate a class of promising new methods to facilitate understanding the methods for machine learning researchers. In particular, we emphasize the key information that enables the success of unsupervised learning - the sequential statistics as the distributional prior in the labels. Exploitation of such sequential statistics makes it possible to estimate parameters of classifiers without the need of paired input-output data. In this paper, we first introduce the concept of Caesar Cipher and its decryption, which motivated the construction of the novel loss function for unsupervised learning we use throughout the paper. Then we use a simple but representative binary classification task as an example to derive and describe the unsupervised learning algorithm in a step-by-step, easy-to-understand fashion. We include two cases, one with Bigram language model as the sequential statistics for use in unsupervised parameter estimation, and another with a simpler Unigram language model. For both cases, detailed derivation steps for the learning algorithm are included. Further, a summary table compares computational steps of the two cases in executing the unsupervised learning algorithm for learning binary classifiers.
Evidence Sentence Extraction for Machine Reading Comprehension
Feb 23, 2019
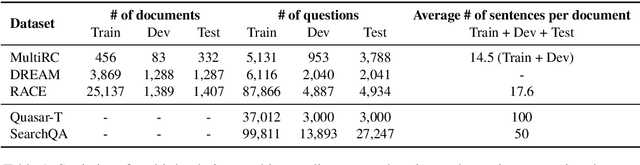
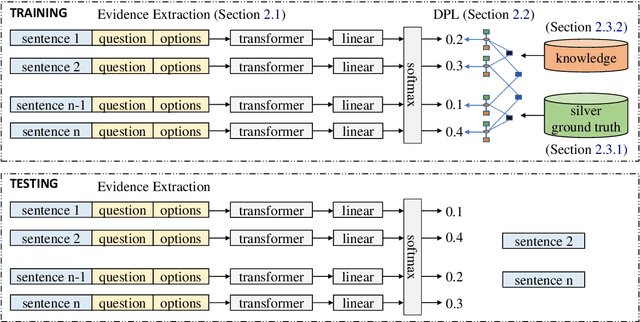
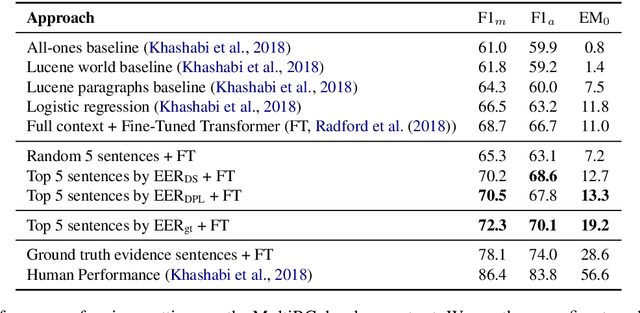
Recently remarkable success has been achieved in machine reading comprehension (MRC). However, it is still difficult to interpret the predictions of existing MRC models. In this paper, we focus on: extracting evidence sentences that can explain/support answer predictions for multiple-choice MRC tasks, where the majority of answer options cannot be directly extracted from reference documents; studying the impacts of using the extracted sentences as the input of MRC models. Due to the lack of ground truth evidence sentence labels in most cases, we apply distant supervision to generate imperfect labels and then use them to train a neural evidence extractor. To denoise the noisy labels, we treat labels as latent variables and define priors over these latent variables by incorporating rich linguistic knowledge under a recently proposed deep probabilistic logic learning framework. We feed the extracted evidence sentences into existing MRC models and evaluate the end-to-end performance on three challenging multiple-choice MRC datasets: MultiRC, DREAM, and RACE, achieving comparable or better performance than the same models that take the full context as input. Our evidence extractor also outperforms a state-of-the-art sentence selector by a large margin on two open-domain question answering datasets: Quasar-T and SearchQA. To the best of our knowledge, this is the first work addressing evidence sentence extraction for multiple-choice MRC.
DREAM: A Challenge Dataset and Models for Dialogue-Based Reading Comprehension
Feb 01, 2019We present DREAM, the first dialogue-based multiple-choice reading comprehension dataset. Collected from English-as-a-foreign-language examinations designed by human experts to evaluate the comprehension level of Chinese learners of English, our dataset contains 10,197 multiple-choice questions for 6,444 dialogues. In contrast to existing reading comprehension datasets, DREAM is the first to focus on in-depth multi-turn multi-party dialogue understanding. DREAM is likely to present significant challenges for existing reading comprehension systems: 84% of answers are non-extractive, 85% of questions require reasoning beyond a single sentence, and 34% of questions also involve commonsense knowledge. We apply several popular neural reading comprehension models that primarily exploit surface information within the text and find them to, at best, just barely outperform a rule-based approach. We next investigate the effects of incorporating dialogue structure and different kinds of general world knowledge into both rule-based and (neural and non-neural) machine learning-based reading comprehension models. Experimental results on the DREAM dataset show the effectiveness of dialogue structure and general world knowledge. DREAM will be available at https://dataset.org/dream/.
Unsupervised Speech Recognition via Segmental Empirical Output Distribution Matching
Dec 23, 2018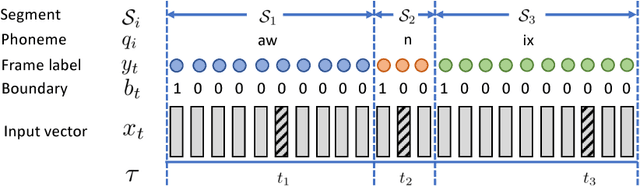
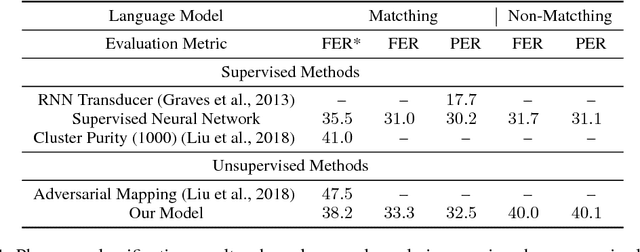
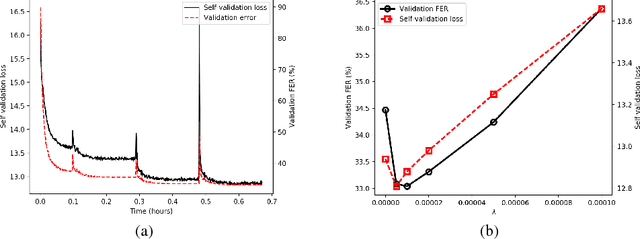
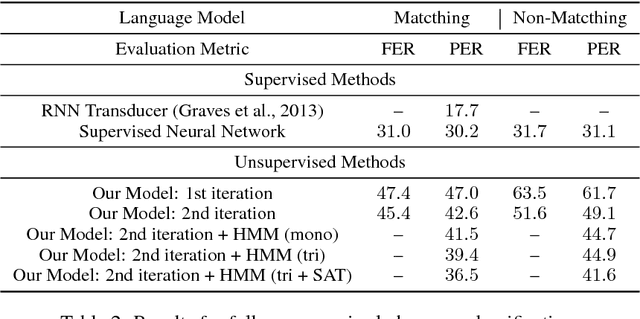
We consider the problem of training speech recognition systems without using any labeled data, under the assumption that the learner can only access to the input utterances and a phoneme language model estimated from a non-overlapping corpus. We propose a fully unsupervised learning algorithm that alternates between solving two sub-problems: (i) learn a phoneme classifier for a given set of phoneme segmentation boundaries, and (ii) refining the phoneme boundaries based on a given classifier. To solve the first sub-problem, we introduce a novel unsupervised cost function named Segmental Empirical Output Distribution Matching, which generalizes the work in (Liu et al., 2017) to segmental structures. For the second sub-problem, we develop an approximate MAP approach to refining the boundaries obtained from Wang et al. (2017). Experimental results on TIMIT dataset demonstrate the success of this fully unsupervised phoneme recognition system, which achieves a phone error rate (PER) of 41.6%. Although it is still far away from the state-of-the-art supervised systems, we show that with oracle boundaries and matching language model, the PER could be improved to 32.5%.This performance approaches the supervised system of the same model architecture, demonstrating the great potential of the proposed method.
Incorporating Structured Commonsense Knowledge in Story Completion
Nov 01, 2018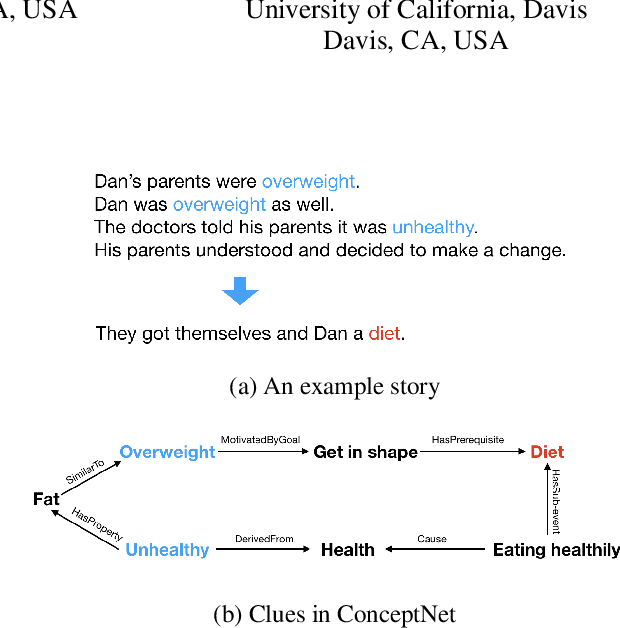
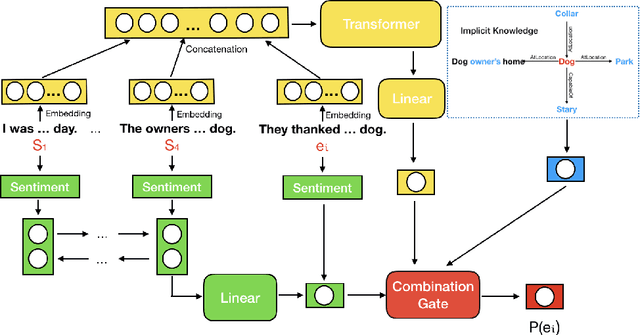
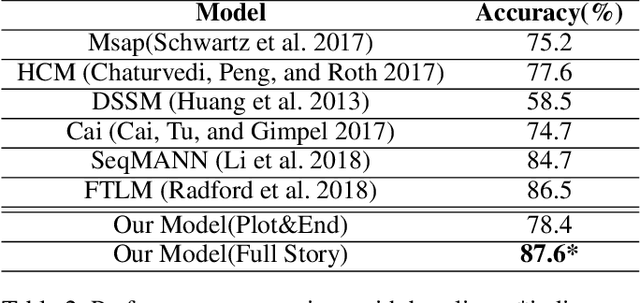
The ability to select an appropriate story ending is the first step towards perfect narrative comprehension. Story ending prediction requires not only the explicit clues within the context, but also the implicit knowledge (such as commonsense) to construct a reasonable and consistent story. However, most previous approaches do not explicitly use background commonsense knowledge. We present a neural story ending selection model that integrates three types of information: narrative sequence, sentiment evolution and commonsense knowledge. Experiments show that our model outperforms state-of-the-art approaches on a public dataset, ROCStory Cloze Task , and the performance gain from adding the additional commonsense knowledge is significant.
M-Walk: Learning to Walk over Graphs using Monte Carlo Tree Search
Nov 01, 2018
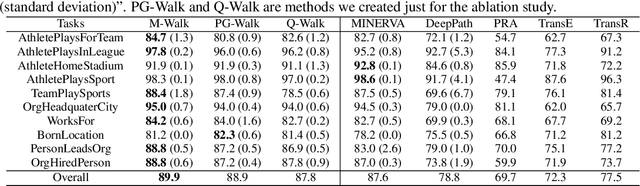
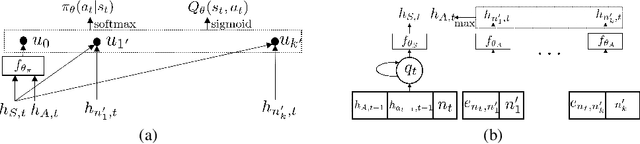

Learning to walk over a graph towards a target node for a given query and a source node is an important problem in applications such as knowledge base completion (KBC). It can be formulated as a reinforcement learning (RL) problem with a known state transition model. To overcome the challenge of sparse rewards, we develop a graph-walking agent called M-Walk, which consists of a deep recurrent neural network (RNN) and Monte Carlo Tree Search (MCTS). The RNN encodes the state (i.e., history of the walked path) and maps it separately to a policy and Q-values. In order to effectively train the agent from sparse rewards, we combine MCTS with the neural policy to generate trajectories yielding more positive rewards. From these trajectories, the network is improved in an off-policy manner using Q-learning, which modifies the RNN policy via parameter sharing. Our proposed RL algorithm repeatedly applies this policy-improvement step to learn the model. At test time, MCTS is combined with the neural policy to predict the target node. Experimental results on several graph-walking benchmarks show that M-Walk is able to learn better policies than other RL-based methods, which are mainly based on policy gradients. M-Walk also outperforms traditional KBC baselines.
P-MCGS: Parallel Monte Carlo Acyclic Graph Search
Oct 28, 2018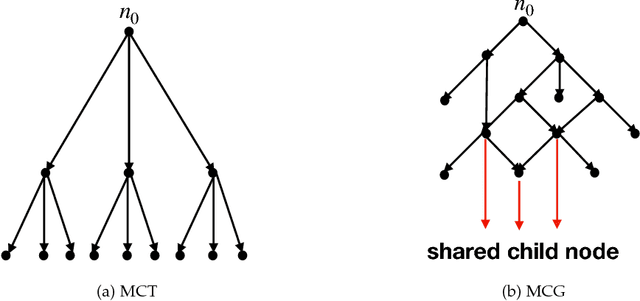
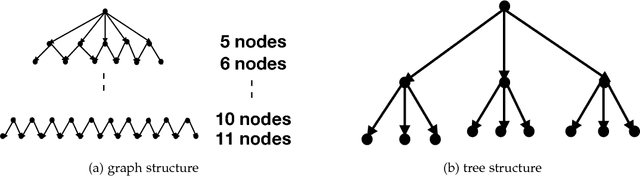
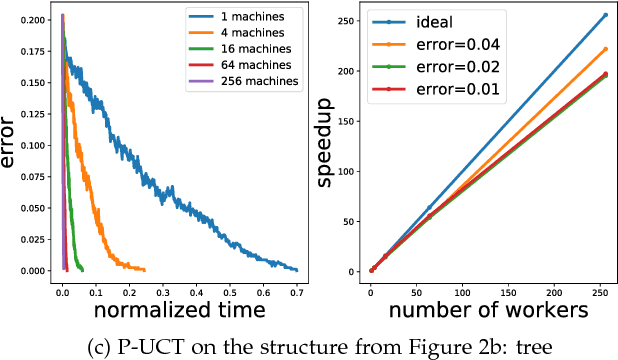
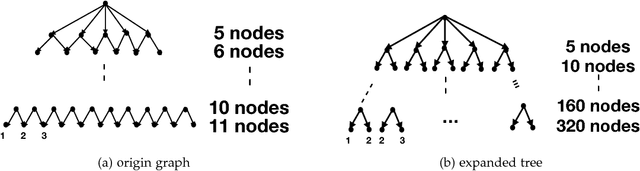
Recently, there have been great interests in Monte Carlo Tree Search (MCTS) in AI research. Although the sequential version of MCTS has been studied widely, its parallel counterpart still lacks systematic study. This leads us to the following questions: \emph{how to design efficient parallel MCTS (or more general cases) algorithms with rigorous theoretical guarantee? Is it possible to achieve linear speedup?} In this paper, we consider the search problem on a more general acyclic one-root graph (namely, Monte Carlo Graph Search (MCGS)), which generalizes MCTS. We develop a parallel algorithm (P-MCGS) to assign multiple workers to investigate appropriate leaf nodes simultaneously. Our analysis shows that P-MCGS algorithm achieves linear speedup and that the sample complexity is comparable to its sequential counterpart.
XL-NBT: A Cross-lingual Neural Belief Tracking Framework
Aug 25, 2018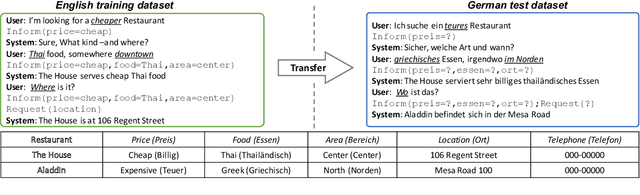
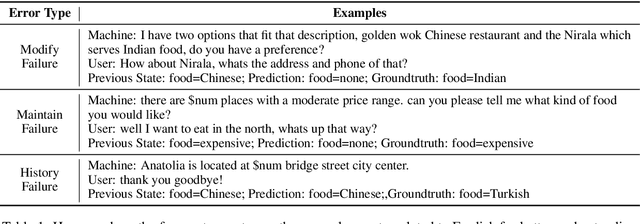
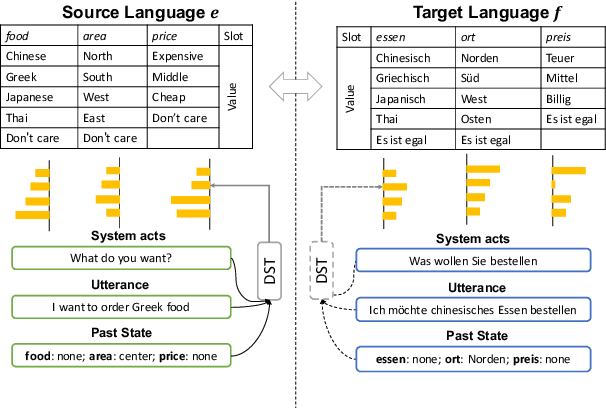
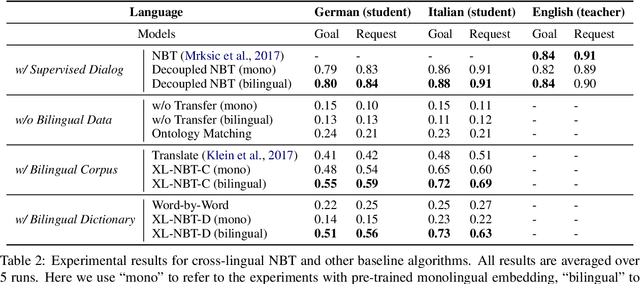
Task-oriented dialog systems are becoming pervasive, and many companies heavily rely on them to complement human agents for customer service in call centers. With globalization, the need for providing cross-lingual customer support becomes more urgent than ever. However, cross-lingual support poses great challenges---it requires a large amount of additional annotated data from native speakers. In order to bypass the expensive human annotation and achieve the first step towards the ultimate goal of building a universal dialog system, we set out to build a cross-lingual state tracking framework. Specifically, we assume that there exists a source language with dialog belief tracking annotations while the target languages have no annotated dialog data of any form. Then, we pre-train a state tracker for the source language as a teacher, which is able to exploit easy-to-access parallel data. We then distill and transfer its own knowledge to the student state tracker in target languages. We specifically discuss two types of common parallel resources: bilingual corpus and bilingual dictionary, and design different transfer learning strategies accordingly. Experimentally, we successfully use English state tracker as the teacher to transfer its knowledge to both Italian and German trackers and achieve promising results.