 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLU2Net: A Lightweight Network for Real-time Underwater Image Enhancement
Jun 21, 2024



Computer vision techniques have empowered underwater robots to effectively undertake a multitude of tasks, including object tracking and path planning. However, underwater optical factors like light refraction and absorption present challenges to underwater vision, which cause degradation of underwater images. A variety of underwater image enhancement methods have been proposed to improve the effectiveness of underwater vision perception. Nevertheless, for real-time vision tasks on underwater robots, it is necessary to overcome the challenges associated with algorithmic efficiency and real-time capabilities. In this paper, we introduce Lightweight Underwater Unet (LU2Net), a novel U-shape network designed specifically for real-time enhancement of underwater images. The proposed model incorporates axial depthwise convolution and the channel attention module, enabling it to significantly reduce computational demands and model parameters, thereby improving processing speed. The extensive experiments conducted on the dataset and real-world underwater robots demonstrate the exceptional performance and speed of proposed model. It is capable of providing well-enhanced underwater images at a speed 8 times faster than the current state-of-the-art underwater image enhancement method. Moreover, LU2Net is able to handle real-time underwater video enhancement.
Inverse Reinforcement Learning with Unknown Reward Model based on Structural Risk Minimization
Dec 27, 2023Inverse reinforcement learning (IRL) usually assumes the model of the reward function is pre-specified and estimates the parameter only. However, how to determine a proper reward model is nontrivial. A simplistic model is less likely to contain the real reward function, while a model with high complexity leads to substantial computation cost and risks overfitting. This paper addresses this trade-off in IRL model selection by introducing the structural risk minimization (SRM) method from statistical learning. SRM selects an optimal reward function class from a hypothesis set minimizing both estimation error and model complexity. To formulate an SRM scheme for IRL, we estimate policy gradient by demonstration serving as empirical risk and establish the upper bound of Rademacher complexity of hypothesis classes as model penalty. The learning guarantee is further presented. In particular, we provide explicit SRM for the common linear weighted sum setting in IRL. Simulations demonstrate the performance and efficiency of our scheme.
AE-GPT: Using Large Language Models to Extract Adverse Events from Surveillance Reports-A Use Case with Influenza Vaccine Adverse Events
Sep 28, 2023



Though Vaccines are instrumental in global health, mitigating infectious diseases and pandemic outbreaks, they can occasionally lead to adverse events (AEs). Recently, Large Language Models (LLMs) have shown promise in effectively identifying and cataloging AEs within clinical reports. Utilizing data from the Vaccine Adverse Event Reporting System (VAERS) from 1990 to 2016, this study particularly focuses on AEs to evaluate LLMs' capability for AE extraction. A variety of prevalent LLMs, including GPT-2, GPT-3 variants, GPT-4, and Llama 2, were evaluated using Influenza vaccine as a use case. The fine-tuned GPT 3.5 model (AE-GPT) stood out with a 0.704 averaged micro F1 score for strict match and 0.816 for relaxed match. The encouraging performance of the AE-GPT underscores LLMs' potential in processing medical data, indicating a significant stride towards advanced AE detection, thus presumably generalizable to other AE extraction tasks.
HiCRISP: A Hierarchical Closed-Loop Robotic Intelligent Self-Correction Planner
Sep 21, 2023



The integration of Large Language Models (LLMs) into robotics has revolutionized human-robot interactions and autonomous task planning. However, these systems are often unable to self-correct during the task execution, which hinders their adaptability in dynamic real-world environments. To address this issue, we present a Hierarchical Closed-loop Robotic Intelligent Self-correction Planner (HiCRISP), an innovative framework that enables robots to correct errors within individual steps during the task execution. HiCRISP actively monitors and adapts the task execution process, addressing both high-level planning and low-level action errors. Extensive benchmark experiments, encompassing virtual and real-world scenarios, showcase HiCRISP's exceptional performance, positioning it as a promising solution for robotic task planning with LLMs.
Affordance-Driven Next-Best-View Planning for Robotic Grasping
Sep 18, 2023Grasping occluded objects in cluttered environments is an essential component in complex robotic manipulation tasks. In this paper, we introduce an AffordanCE-driven Next-Best-View planning policy (ACE-NBV) that tries to find a feasible grasp for target object via continuously observing scenes from new viewpoints. This policy is motivated by the observation that the grasp affordances of an occluded object can be better-measured under the view when the view-direction are the same as the grasp view. Specifically, our method leverages the paradigm of novel view imagery to predict the grasps affordances under previously unobserved view, and select next observation view based on the gain of the highest imagined grasp quality of the target object. The experimental results in simulation and on the real robot demonstrate the effectiveness of the proposed affordance-driven next-best-view planning policy. Additional results, code, and videos of real robot experiments can be found in the supplementary materials.
Control Input Inference of Mobile Agents under Unknown Objective
Jul 20, 2023Trajectory and control secrecy is an important issue in robotics security. This paper proposes a novel algorithm for the control input inference of a mobile agent without knowing its control objective. Specifically, the algorithm first estimates the target state by applying external perturbations. Then we identify the objective function based on the inverse optimal control, providing the well-posedness proof and the identifiability analysis. Next, we obtain the optimal estimate of the control horizon using binary search. Finally, the agent's control optimization problem is reconstructed and solved to predict its input. Simulation illustrates the efficiency and the performance of the algorithm.
Revisiting Estimation Bias in Policy Gradients for Deep Reinforcement Learning
Jan 20, 2023We revisit the estimation bias in policy gradients for the discounted episodic Markov decision process (MDP) from Deep Reinforcement Learning (DRL) perspective. The objective is formulated theoretically as the expected returns discounted over the time horizon. One of the major policy gradient biases is the state distribution shift: the state distribution used to estimate the gradients differs from the theoretical formulation in that it does not take into account the discount factor. Existing discussion of the influence of this bias was limited to the tabular and softmax cases in the literature. Therefore, in this paper, we extend it to the DRL setting where the policy is parameterized and demonstrate how this bias can lead to suboptimal policies theoretically. We then discuss why the empirically inaccurate implementations with shifted state distribution can still be effective. We show that, despite such state distribution shift, the policy gradient estimation bias can be reduced in the following three ways: 1) a small learning rate; 2) an adaptive-learning-rate-based optimizer; and 3) KL regularization. Specifically, we show that a smaller learning rate, or, an adaptive learning rate, such as that used by Adam and RSMProp optimizers, makes the policy optimization robust to the bias. We further draw connections between optimizers and the optimization regularization to show that both the KL and the reverse KL regularization can significantly rectify this bias. Moreover, we provide extensive experiments on continuous control tasks to support our analysis. Our paper sheds light on how successful PG algorithms optimize policies in the DRL setting, and contributes insights into the practical issues in DRL.
Toward Global Sensing Quality Maximization: A Configuration Optimization Scheme for Camera Networks
Nov 28, 2022The performance of a camera network monitoring a set of targets depends crucially on the configuration of the cameras. In this paper, we investigate the reconfiguration strategy for the parameterized camera network model, with which the sensing qualities of the multiple targets can be optimized globally and simultaneously. We first propose to use the number of pixels occupied by a unit-length object in image as a metric of the sensing quality of the object, which is determined by the parameters of the camera, such as intrinsic, extrinsic, and distortional coefficients. Then, we form a single quantity that measures the sensing quality of the targets by the camera network. This quantity further serves as the objective function of our optimization problem to obtain the optimal camera configuration. We verify the effectiveness of our approach through extensive simulations and experiments, and the results reveal its improved performance on the AprilTag detection tasks. Codes and related utilities for this work are open-sourced and available at https://github.com/sszxc/MultiCam-Simulation.
Safety-Critical Optimal Control for Robotic Manipulators in A Cluttered Environment
Nov 11, 2022



Designing safety-critical control for robotic manipulators is challenging, especially in a cluttered environment. First, the actual trajectory of a manipulator might deviate from the planned one due to the complex collision environments and non-trivial dynamics, leading to collision; Second, the feasible space for the manipulator is hard to obtain since the explicit distance functions between collision meshes are unknown. By analyzing the relationship between the safe set and the controlled invariant set, this paper proposes a data-driven control barrier function (CBF) construction method, which extracts CBF from distance samples. Specifically, the CBF guarantees the controlled invariant property for considering the system dynamics. The data-driven method samples the distance function and determines the safe set. Then, the CBF is synthesized based on the safe set by a scenario-based sum of square (SOS) program. Unlike most existing linearization based approaches, our method reserves the volume of the feasible space for planning without approximation, which helps find a solution in a cluttered environment. The control law is obtained by solving a CBF-based quadratic program in real time, which works as a safe filter for the desired planning-based controller. Moreover, our method guarantees safety with the proven probabilistic result. Our method is validated on a 7-DOF manipulator in both real and virtual cluttered environments. The experiments show that the manipulator is able to execute tasks where the clearance between obstacles is in millimeters.
Adaptive Obstacle Avoidance Algorithm Based on Trajectory Learning
Jun 07, 2022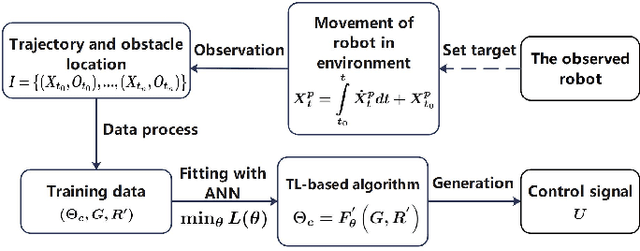
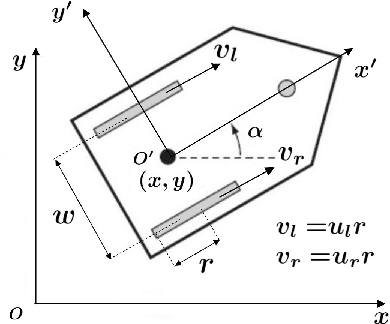
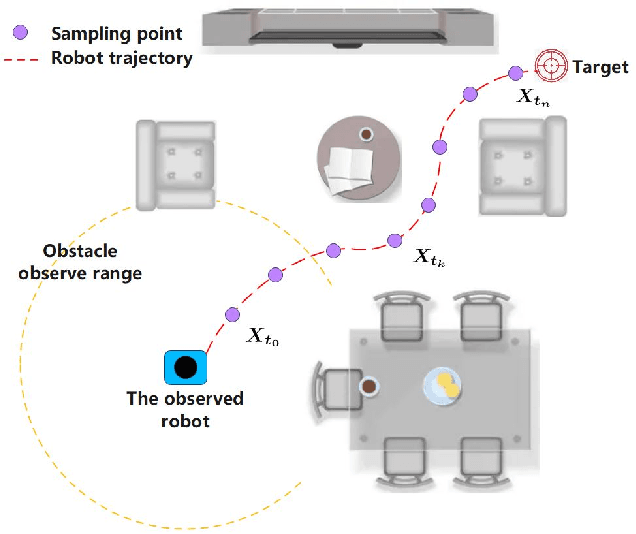
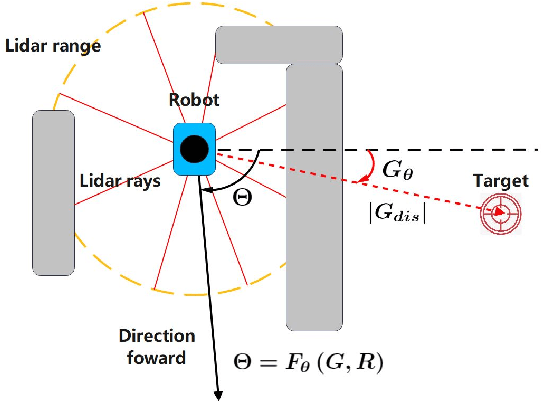
Most obstacle avoidance algorithms are only effective in specific environments, and they have low adaptability to some new environments. In this paper, we propose a trajectory learning (TL)-based obstacle avoidance algorithm, which can learn implicit obstacle avoidance mechanism from trajectories generated by general obstacle avoidance algorithms and achieves better adaptability. Specifically, we define a general data structure to describe the obstacle avoidance mechanism. Based on this structure, we transform the learning of the obstacle avoidance algorithm into a multiclass classification problem about the direction selection. Then, we design an artificial neural network (ANN) to fit multiclass classification function through supervised learning and finally obtain the obstacle avoidance mechanism that generates the observed trajectories. Our algorithm can obtain the obstacle avoidance mechanism similar to that demonstrated in the trajectories, and are adaptable to unseen environments. The automatic learning mechanism simplifies modification and debugging of obstacle avoidance algorithms in applications. Simulation results demonstrate that the proposed algorithm can learn obstacle avoidance strategy from trajectories and achieve better adaptability.