 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepoCoder: Repository-Level Code Completion Through Iterative Retrieval and Generation
Apr 03, 2023The task of repository-level code completion is to continue writing the unfinished code based on a broader context of the repository. While for automated code completion tools, it is difficult to utilize the useful information scattered in different files. We propose RepoCoder, a simple, generic, and effective framework to address the challenge. It streamlines the repository-level code completion process by incorporating a similarity-based retriever and a pre-trained code language model, which allows for the effective utilization of repository-level information for code completion and grants the ability to generate code at various levels of granularity. Furthermore, RepoCoder utilizes a novel iterative retrieval-generation paradigm that bridges the gap between retrieval context and the intended completion target. We also propose a new benchmark RepoEval, which consists of the latest and high-quality real-world repositories covering line, API invocation, and function body completion scenarios. We test the performance of RepoCoder by using various combinations of code retrievers and generators. Experimental results indicate that RepoCoder significantly improves the zero-shot code completion baseline by over 10% in all settings and consistently outperforms the vanilla retrieval-augmented code completion approach. Furthermore, we validate the effectiveness of RepoCoder through comprehensive analysis, providing valuable insights for future research.
LayoutDiffusion: Improving Graphic Layout Generation by Discrete Diffusion Probabilistic Models
Mar 21, 2023



Creating graphic layouts is a fundamental step in graphic designs. In this work, we present a novel generative model named LayoutDiffusion for automatic layout generation. As layout is typically represented as a sequence of discrete tokens, LayoutDiffusion models layout generation as a discrete denoising diffusion process. It learns to reverse a mild forward process, in which layouts become increasingly chaotic with the growth of forward steps and layouts in the neighboring steps do not differ too much. Designing such a mild forward process is however very challenging as layout has both categorical attributes and ordinal attributes. To tackle the challenge, we summarize three critical factors for achieving a mild forward process for the layout, i.e., legality, coordinate proximity and type disruption. Based on the factors, we propose a block-wise transition matrix coupled with a piece-wise linear noise schedule. Experiments on RICO and PubLayNet datasets show that LayoutDiffusion outperforms state-of-the-art approaches significantly. Moreover, it enables two conditional layout generation tasks in a plug-and-play manner without re-training and achieves better performance than existing methods.
Does Deep Learning Learn to Abstract? A Systematic Probing Framework
Feb 23, 2023



Abstraction is a desirable capability for deep learning models, which means to induce abstract concepts from concrete instances and flexibly apply them beyond the learning context. At the same time, there is a lack of clear understanding about both the presence and further characteristics of this capability in deep learning models. In this paper, we introduce a systematic probing framework to explore the abstraction capability of deep learning models from a transferability perspective. A set of controlled experiments are conducted based on this framework, providing strong evidence that two probed pre-trained language models (PLMs), T5 and GPT2, have the abstraction capability. We also conduct in-depth analysis, thus shedding further light: (1) the whole training phase exhibits a "memorize-then-abstract" two-stage process; (2) the learned abstract concepts are gathered in a few middle-layer attention heads, rather than being evenly distributed throughout the model; (3) the probed abstraction capabilities exhibit robustness against concept mutations, and are more robust to low-level/source-side mutations than high-level/target-side ones; (4) generic pre-training is critical to the emergence of abstraction capability, and PLMs exhibit better abstraction with larger model sizes and data scales.
Towards Knowledge-Intensive Text-to-SQL Semantic Parsing with Formulaic Knowledge
Jan 03, 2023



In this paper, we study the problem of knowledge-intensive text-to-SQL, in which domain knowledge is necessary to parse expert questions into SQL queries over domain-specific tables. We formalize this scenario by building a new Chinese benchmark KnowSQL consisting of domain-specific questions covering various domains. We then address this problem by presenting formulaic knowledge, rather than by annotating additional data examples. More concretely, we construct a formulaic knowledge bank as a domain knowledge base and propose a framework (ReGrouP) to leverage this formulaic knowledge during parsing. Experiments using ReGrouP demonstrate a significant 28.2% improvement overall on KnowSQL.
MultiSpider: Towards Benchmarking Multilingual Text-to-SQL Semantic Parsing
Dec 27, 2022Text-to-SQL semantic parsing is an important NLP task, which greatly facilitates the interaction between users and the database and becomes the key component in many human-computer interaction systems. Much recent progress in text-to-SQL has been driven by large-scale datasets, but most of them are centered on English. In this work, we present MultiSpider, the largest multilingual text-to-SQL dataset which covers seven languages (English, German, French, Spanish, Japanese, Chinese, and Vietnamese). Upon MultiSpider, we further identify the lexical and structural challenges of text-to-SQL (caused by specific language properties and dialect sayings) and their intensity across different languages. Experimental results under three typical settings (zero-shot, monolingual and multilingual) reveal a 6.1% absolute drop in accuracy in non-English languages. Qualitative and quantitative analyses are conducted to understand the reason for the performance drop of each language. Besides the dataset, we also propose a simple schema augmentation framework SAVe (Schema-Augmentation-with-Verification), which significantly boosts the overall performance by about 1.8% and closes the 29.5% performance gap across languages.
Towards Robustness of Text-to-SQL Models Against Natural and Realistic Adversarial Table Perturbation
Dec 20, 2022The robustness of Text-to-SQL parsers against adversarial perturbations plays a crucial role in delivering highly reliable applications. Previous studies along this line primarily focused on perturbations in the natural language question side, neglecting the variability of tables. Motivated by this, we propose the Adversarial Table Perturbation (ATP) as a new attacking paradigm to measure the robustness of Text-to-SQL models. Following this proposition, we curate ADVETA, the first robustness evaluation benchmark featuring natural and realistic ATPs. All tested state-of-the-art models experience dramatic performance drops on ADVETA, revealing models' vulnerability in real-world practices. To defend against ATP, we build a systematic adversarial training example generation framework tailored for better contextualization of tabular data. Experiments show that our approach not only brings the best robustness improvement against table-side perturbations but also substantially empowers models against NL-side perturbations. We release our benchmark and code at: https://github.com/microsoft/ContextualSP.
When Neural Model Meets NL2Code: A Survey
Dec 19, 2022Given a natural language that describes the user's demands, the NL2Code task aims to generate code that addresses the demands. This is a critical but challenging task that mirrors the capabilities of AI-powered programming. The NL2Code task is inherently versatile, diverse and complex. For example, a demand can be described in different languages, in different formats, and at different levels of granularity. This inspired us to do this survey for NL2Code. In this survey, we focus on how does neural network (NN) solves NL2Code. We first propose a comprehensive framework, which is able to cover all studies in this field. Then, we in-depth parse the existing studies into this framework. We create an online website to record the parsing results, which tracks existing and recent NL2Code progress. In addition, we summarize the current challenges of NL2Code as well as its future directions. We hope that this survey can foster the evolution of this field.
Know What I don't Know: Handling Ambiguous and Unanswerable Questions for Text-to-SQL
Dec 17, 2022



The task of text-to-SQL is to convert a natural language question to its corresponding SQL query in the context of relational tables. Existing text-to-SQL parsers generate a "plausible" SQL query for an arbitrary user question, thereby failing to correctly handle problematic user questions. To formalize this problem, we conduct a preliminary study on the observed ambiguous and unanswerable cases in text-to-SQL and summarize them into 6 feature categories. Correspondingly, we identify the causes behind each category and propose requirements for handling ambiguous and unanswerable questions. Following this study, we propose a simple yet effective counterfactual example generation approach for the automatic generation of ambiguous and unanswerable text-to-SQL examples. Furthermore, we propose a weakly supervised model DTE (Detecting-Then-Explaining) for error detection, localization, and explanation. Experimental results show that our model achieves the best result on both real-world examples and generated examples compared with various baselines. We will release data and code for future research.
When Language Model Meets Private Library
Oct 31, 2022



With the rapid development of pre-training techniques, a number of language models have been pre-trained on large-scale code corpora and perform well in code generation. In this paper, we investigate how to equip pre-trained language models with the ability of code generation for private libraries. In practice, it is common for programmers to write code using private libraries. However, this is a challenge for language models since they have never seen private APIs during training. Motivated by the fact that private libraries usually come with elaborate API documentation, we propose a novel framework with two modules: the APIRetriever finds useful APIs, and then the APICoder generates code using these APIs. For APIRetriever, we present a dense retrieval system and also design a friendly interaction to involve uses. For APICoder, we can directly use off-the-shelf language models, or continually pre-train the base model on a code corpus containing API information. Both modules are trained with data from public libraries and can be generalized to private ones. Furthermore, we craft three benchmarks for private libraries, named TorchDataEval, MonkeyEval, and BeatNumEval. Experimental results demonstrate the impressive performance of our framework.
UniLayout: Taming Unified Sequence-to-Sequence Transformers for Graphic Layout Generation
Aug 17, 2022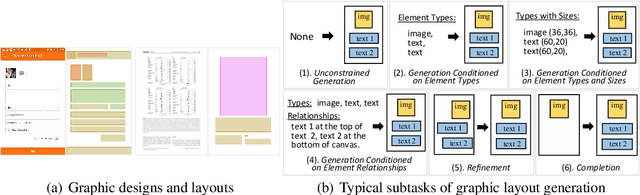

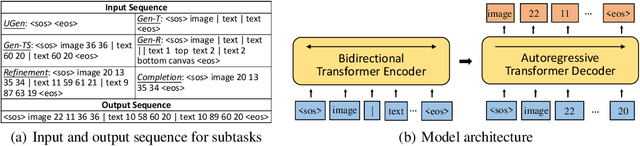
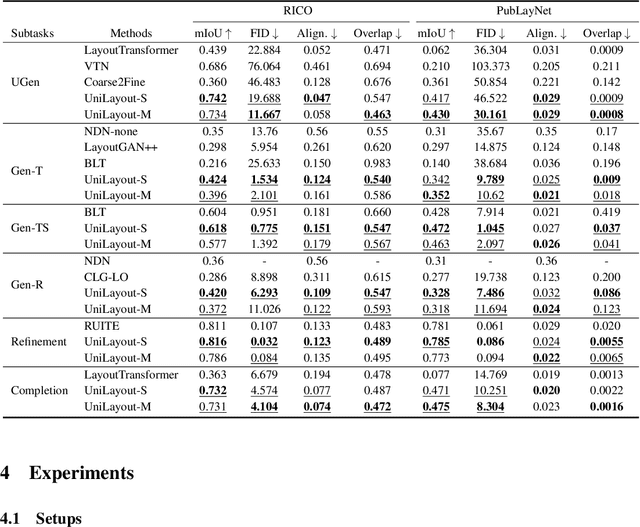
To satisfy various user needs, different subtasks of graphic layout generation have been explored intensively in recent years. Existing studies usually propose task-specific methods with diverse input-output formats, dedicated model architectures, and different learning methods. However, those specialized approaches make the adaption to unseen subtasks difficult, hinder the knowledge sharing between different subtasks, and are contrary to the trend of devising general-purpose models. In this work, we propose UniLayout, which handles different subtasks for graphic layout generation in a unified manner. First, we uniformly represent diverse inputs and outputs of subtasks as the sequences of tokens. Then, based on the unified sequence format, we naturally leverage an identical encoder-decoder architecture with Transformers for different subtasks. Moreover, based on the above two kinds of unification, we further develop a single model that supports all subtasks concurrently. Experiments on two public datasets demonstrate that while simple, UniLayout significantly outperforms the previous task-specific methods.