 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastPhysGS: Accelerating Physics-based Dynamic 3DGS Simulation via Interior Completion and Adaptive Optimization
Feb 02, 2026Extending 3D Gaussian Splatting (3DGS) to 4D physical simulation remains challenging. Based on the Material Point Method (MPM), existing methods either rely on manual parameter tuning or distill dynamics from video diffusion models, limiting the generalization and optimization efficiency. Recent attempts using LLMs/VLMs suffer from a text/image-to-3D perceptual gap, yielding unstable physics behavior. In addition, they often ignore the surface structure of 3DGS, leading to implausible motion. We propose FastPhysGS, a fast and robust framework for physics-based dynamic 3DGS simulation:(1) Instance-aware Particle Filling (IPF) with Monte Carlo Importance Sampling (MCIS) to efficiently populate interior particles while preserving geometric fidelity; (2) Bidirectional Graph Decoupling Optimization (BGDO), an adaptive strategy that rapidly optimizes material parameters predicted from a VLM. Experiments show FastPhysGS achieves high-fidelity physical simulation in 1 minute using only 7 GB runtime memory, outperforming prior works with broad potential applications.
StdGEN++: A Comprehensive System for Semantic-Decomposed 3D Character Generation
Jan 12, 2026We present StdGEN++, a novel and comprehensive system for generating high-fidelity, semantically decomposed 3D characters from diverse inputs. Existing 3D generative methods often produce monolithic meshes that lack the structural flexibility required by industrial pipelines in gaming and animation. Addressing this gap, StdGEN++ is built upon a Dual-branch Semantic-aware Large Reconstruction Model (Dual-Branch S-LRM), which jointly reconstructs geometry, color, and per-component semantics in a feed-forward manner. To achieve production-level fidelity, we introduce a novel semantic surface extraction formalism compatible with hybrid implicit fields. This mechanism is accelerated by a coarse-to-fine proposal scheme, which significantly reduces memory footprint and enables high-resolution mesh generation. Furthermore, we propose a video-diffusion-based texture decomposition module that disentangles appearance into editable layers (e.g., separated iris and skin), resolving semantic confusion in facial regions. Experiments demonstrate that StdGEN++ achieves state-of-the-art performance, significantly outperforming existing methods in geometric accuracy and semantic disentanglement. Crucially, the resulting structural independence unlocks advanced downstream capabilities, including non-destructive editing, physics-compliant animation, and gaze tracking, making it a robust solution for automated character asset production.
StdGEN: Semantic-Decomposed 3D Character Generation from Single Images
Nov 08, 2024



We present StdGEN, an innovative pipeline for generating semantically decomposed high-quality 3D characters from single images, enabling broad applications in virtual reality, gaming, and filmmaking, etc. Unlike previous methods which struggle with limited decomposability, unsatisfactory quality, and long optimization times, StdGEN features decomposability, effectiveness and efficiency; i.e., it generates intricately detailed 3D characters with separated semantic components such as the body, clothes, and hair, in three minutes. At the core of StdGEN is our proposed Semantic-aware Large Reconstruction Model (S-LRM), a transformer-based generalizable model that jointly reconstructs geometry, color and semantics from multi-view images in a feed-forward manner. A differentiable multi-layer semantic surface extraction scheme is introduced to acquire meshes from hybrid implicit fields reconstructed by our S-LRM. Additionally, a specialized efficient multi-view diffusion model and an iterative multi-layer surface refinement module are integrated into the pipeline to facilitate high-quality, decomposable 3D character generation. Extensive experiments demonstrate our state-of-the-art performance in 3D anime character generation, surpassing existing baselines by a significant margin in geometry, texture and decomposability. StdGEN offers ready-to-use semantic-decomposed 3D characters and enables flexible customization for a wide range of applications. Project page: https://stdgen.github.io
RaFE: Generative Radiance Fields Restoration
Apr 07, 2024

NeRF (Neural Radiance Fields) has demonstrated tremendous potential in novel view synthesis and 3D reconstruction, but its performance is sensitive to input image quality, which struggles to achieve high-fidelity rendering when provided with low-quality sparse input viewpoints. Previous methods for NeRF restoration are tailored for specific degradation type, ignoring the generality of restoration. To overcome this limitation, we propose a generic radiance fields restoration pipeline, named RaFE, which applies to various types of degradations, such as low resolution, blurriness, noise, compression artifacts, or their combinations. Our approach leverages the success of off-the-shelf 2D restoration methods to recover the multi-view images individually. Instead of reconstructing a blurred NeRF by averaging inconsistencies, we introduce a novel approach using Generative Adversarial Networks (GANs) for NeRF generation to better accommodate the geometric and appearance inconsistencies present in the multi-view images. Specifically, we adopt a two-level tri-plane architecture, where the coarse level remains fixed to represent the low-quality NeRF, and a fine-level residual tri-plane to be added to the coarse level is modeled as a distribution with GAN to capture potential variations in restoration. We validate RaFE on both synthetic and real cases for various restoration tasks, demonstrating superior performance in both quantitative and qualitative evaluations, surpassing other 3D restoration methods specific to single task. Please see our project website https://zkaiwu.github.io/RaFE-Project/.
UniLayout: Taming Unified Sequence-to-Sequence Transformers for Graphic Layout Generation
Aug 17, 2022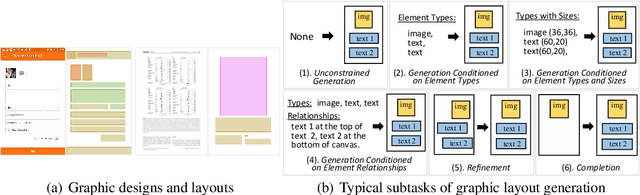

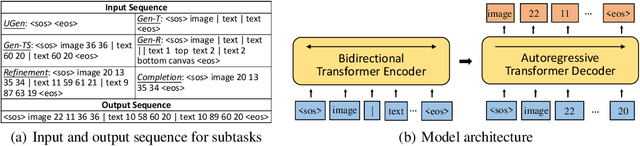
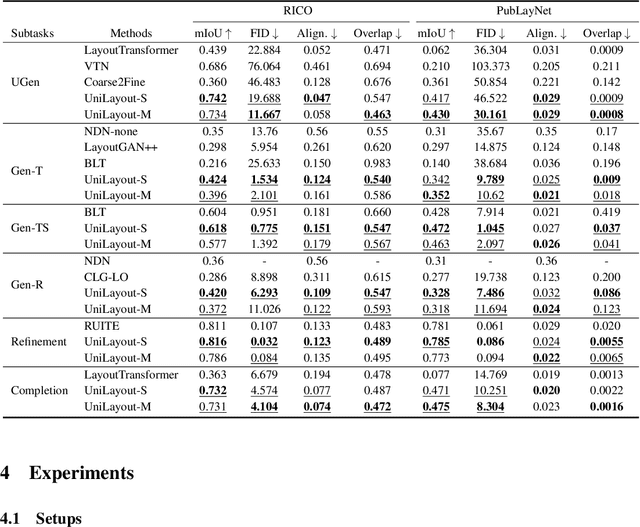
To satisfy various user needs, different subtasks of graphic layout generation have been explored intensively in recent years. Existing studies usually propose task-specific methods with diverse input-output formats, dedicated model architectures, and different learning methods. However, those specialized approaches make the adaption to unseen subtasks difficult, hinder the knowledge sharing between different subtasks, and are contrary to the trend of devising general-purpose models. In this work, we propose UniLayout, which handles different subtasks for graphic layout generation in a unified manner. First, we uniformly represent diverse inputs and outputs of subtasks as the sequences of tokens. Then, based on the unified sequence format, we naturally leverage an identical encoder-decoder architecture with Transformers for different subtasks. Moreover, based on the above two kinds of unification, we further develop a single model that supports all subtasks concurrently. Experiments on two public datasets demonstrate that while simple, UniLayout significantly outperforms the previous task-specific methods.