 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Offline Imitation Learning Through State-level Trajectory Stitching
Mar 28, 2025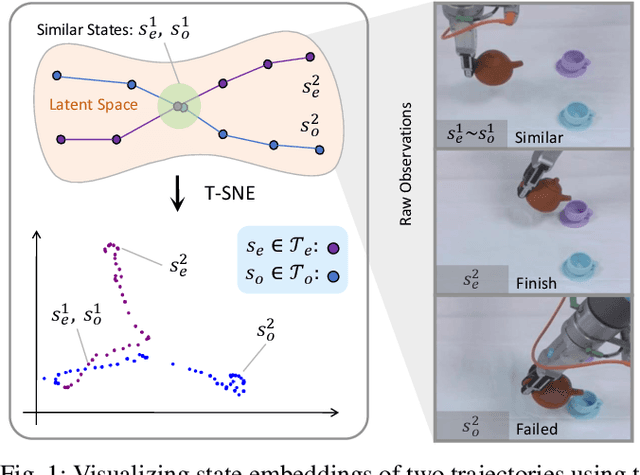

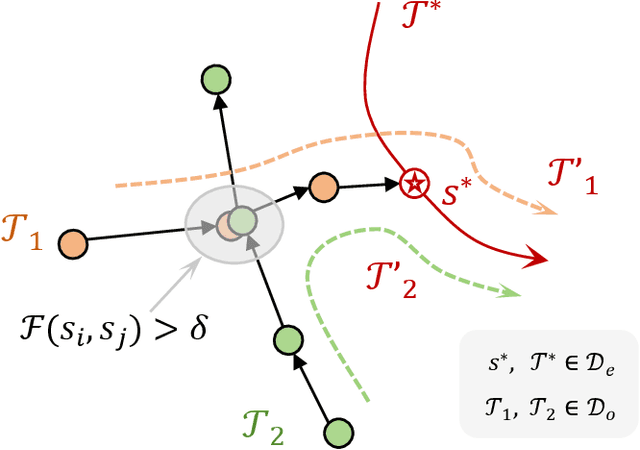

Imitation learning (IL) has proven effective for enabling robots to acquire visuomotor skills through expert demonstrations. However, traditional IL methods are limited by their reliance on high-quality, often scarce, expert data, and suffer from covariate shift. To address these challenges, recent advances in offline IL have incorporated suboptimal, unlabeled datasets into the training. In this paper, we propose a novel approach to enhance policy learning from mixed-quality offline datasets by leveraging task-relevant trajectory fragments and rich environmental dynamics. Specifically, we introduce a state-based search framework that stitches state-action pairs from imperfect demonstrations, generating more diverse and informative training trajectories. Experimental results on standard IL benchmarks and real-world robotic tasks showcase that our proposed method significantly improves both generalization and performance.
Exploring the Roles of Large Language Models in Reshaping Transportation Systems: A Survey, Framework, and Roadmap
Mar 27, 2025Modern transportation systems face pressing challenges due to increasing demand, dynamic environments, and heterogeneous information integration. The rapid evolution of Large Language Models (LLMs) offers transformative potential to address these challenges. Extensive knowledge and high-level capabilities derived from pretraining evolve the default role of LLMs as text generators to become versatile, knowledge-driven task solvers for intelligent transportation systems. This survey first presents LLM4TR, a novel conceptual framework that systematically categorizes the roles of LLMs in transportation into four synergetic dimensions: information processors, knowledge encoders, component generators, and decision facilitators. Through a unified taxonomy, we systematically elucidate how LLMs bridge fragmented data pipelines, enhance predictive analytics, simulate human-like reasoning, and enable closed-loop interactions across sensing, learning, modeling, and managing tasks in transportation systems. For each role, our review spans diverse applications, from traffic prediction and autonomous driving to safety analytics and urban mobility optimization, highlighting how emergent capabilities of LLMs such as in-context learning and step-by-step reasoning can enhance the operation and management of transportation systems. We further curate practical guidance, including available resources and computational guidelines, to support real-world deployment. By identifying challenges in existing LLM-based solutions, this survey charts a roadmap for advancing LLM-driven transportation research, positioning LLMs as central actors in the next generation of cyber-physical-social mobility ecosystems. Online resources can be found in the project page: https://github.com/tongnie/awesome-llm4tr.
A Vehicle-Infrastructure Multi-layer Cooperative Decision-making Framework
Mar 19, 2025Autonomous driving has entered the testing phase, but due to the limited decision-making capabilities of individual vehicle algorithms, safety and efficiency issues have become more apparent in complex scenarios. With the advancement of connected communication technologies, autonomous vehicles equipped with connectivity can leverage vehicle-to-vehicle (V2V) and vehicle-to-infrastructure (V2I) communications, offering a potential solution to the decision-making challenges from individual vehicle's perspective. We propose a multi-level vehicle-infrastructure cooperative decision-making framework for complex conflict scenarios at unsignalized intersections. First, based on vehicle states, we define a method for quantifying vehicle impacts and their propagation relationships, using accumulated impact to group vehicles through motif-based graph clustering. Next, within and between vehicle groups, a pass order negotiation process based on Large Language Models (LLM) is employed to determine the vehicle passage order, resulting in planned vehicle actions. Simulation results from ablation experiments show that our approach reduces negotiation complexity and ensures safer, more efficient vehicle passage at intersections, aligning with natural decision-making logic.
CT-UIO: Continuous-Time UWB-Inertial-Odometer Localization Using Non-Uniform B-spline with Fewer Anchors
Feb 10, 2025Ultra-wideband (UWB) based positioning with fewer anchors has attracted significant research interest in recent years, especially under energy-constrained conditions. However, most existing methods rely on discrete-time representations and smoothness priors to infer a robot's motion states, which often struggle with ensuring multi-sensor data synchronization. In this paper, we present an efficient UWB-Inertial-odometer localization system, utilizing a non-uniform B-spline framework with fewer anchors. Unlike traditional uniform B-spline-based continuous-time methods, we introduce an adaptive knot-span adjustment strategy for non-uniform continuous-time trajectory representation. This is accomplished by adjusting control points dynamically based on movement speed. To enable efficient fusion of IMU and odometer data, we propose an improved Extended Kalman Filter (EKF) with innovation-based adaptive estimation to provide short-term accurate motion prior. Furthermore, to address the challenge of achieving a fully observable UWB localization system under few-anchor conditions, the Virtual Anchor (VA) generation method based on multiple hypotheses is proposed. At the backend, we propose a CT-UIO factor graph with an adaptive sliding window for global trajectory estimation. Comprehensive experiments conducted on corridor and exhibition hall datasets validate the proposed system's high precision and robust performance. The codebase and datasets of this work will be open-sourced at https://github.com/JasonSun623/CT-UIO.
TeLL-Drive: Enhancing Autonomous Driving with Teacher LLM-Guided Deep Reinforcement Learning
Feb 03, 2025



Although Deep Reinforcement Learning (DRL) and Large Language Models (LLMs) each show promise in addressing decision-making challenges in autonomous driving, DRL often suffers from high sample complexity, while LLMs have difficulty ensuring real-time decision making. To address these limitations, we propose TeLL-Drive, a hybrid framework that integrates an Teacher LLM to guide an attention-based Student DRL policy. By incorporating risk metrics, historical scenario retrieval, and domain heuristics into context-rich prompts, the LLM produces high-level driving strategies through chain-of-thought reasoning. A self-attention mechanism then fuses these strategies with the DRL agent's exploration, accelerating policy convergence and boosting robustness across diverse driving conditions. Our experimental results, evaluated across multiple traffic scenarios, show that TeLL-Drive outperforms existing baseline methods, including other LLM-based approaches, in terms of success rates, average returns, and real-time feasibility. Ablation studies underscore the importance of each model component, especially the synergy between the attention mechanism and LLM-driven guidance. These findings suggest that TeLL-Drive significantly enhances both the adaptability and safety of autonomous driving systems, while offering a more efficient and scalable approach for policy learning. Full validation results are available on our website.
LLM-attacker: Enhancing Closed-loop Adversarial Scenario Generation for Autonomous Driving with Large Language Models
Jan 27, 2025



Ensuring and improving the safety of autonomous driving systems (ADS) is crucial for the deployment of highly automated vehicles, especially in safety-critical events. To address the rarity issue, adversarial scenario generation methods are developed, in which behaviors of traffic participants are manipulated to induce safety-critical events. However, existing methods still face two limitations. First, identification of the adversarial participant directly impacts the effectiveness of the generation. However, the complexity of real-world scenarios, with numerous participants and diverse behaviors, makes identification challenging. Second, the potential of generated safety-critical scenarios to continuously improve ADS performance remains underexplored. To address these issues, we propose LLM-attacker: a closed-loop adversarial scenario generation framework leveraging large language models (LLMs). Specifically, multiple LLM agents are designed and coordinated to identify optimal attackers. Then, the trajectories of the attackers are optimized to generate adversarial scenarios. These scenarios are iteratively refined based on the performance of ADS, forming a feedback loop to improve ADS. Experimental results show that LLM-attacker can create more dangerous scenarios than other methods, and the ADS trained with it achieves a collision rate half that of training with normal scenarios. This indicates the ability of LLM-attacker to test and enhance the safety and robustness of ADS. Video demonstrations are provided at: https://drive.google.com/file/d/1Zv4V3iG7825oyiKbUwS2Y-rR0DQIE1ZA/view.
Collaborative Imputation of Urban Time Series through Cross-city Meta-learning
Jan 20, 2025Urban time series, such as mobility flows, energy consumption, and pollution records, encapsulate complex urban dynamics and structures. However, data collection in each city is impeded by technical challenges such as budget limitations and sensor failures, necessitating effective data imputation techniques that can enhance data quality and reliability. Existing imputation models, categorized into learning-based and analytics-based paradigms, grapple with the trade-off between capacity and generalizability. Collaborative learning to reconstruct data across multiple cities holds the promise of breaking this trade-off. Nevertheless, urban data's inherent irregularity and heterogeneity issues exacerbate challenges of knowledge sharing and collaboration across cities. To address these limitations, we propose a novel collaborative imputation paradigm leveraging meta-learned implicit neural representations (INRs). INRs offer a continuous mapping from domain coordinates to target values, integrating the strengths of both paradigms. By imposing embedding theory, we first employ continuous parameterization to handle irregularity and reconstruct the dynamical system. We then introduce a cross-city collaborative learning scheme through model-agnostic meta learning, incorporating hierarchical modulation and normalization techniques to accommodate multiscale representations and reduce variance in response to heterogeneity. Extensive experiments on a diverse urban dataset from 20 global cities demonstrate our model's superior imputation performance and generalizability, underscoring the effectiveness of collaborative imputation in resource-constrained settings.
Re-Visible Dual-Domain Self-Supervised Deep Unfolding Network for MRI Reconstruction
Jan 07, 2025



Magnetic Resonance Imaging (MRI) is widely used in clinical practice, but suffered from prolonged acquisition time. Although deep learning methods have been proposed to accelerate acquisition and demonstrate promising performance, they rely on high-quality fully-sampled datasets for training in a supervised manner. However, such datasets are time-consuming and expensive-to-collect, which constrains their broader applications. On the other hand, self-supervised methods offer an alternative by enabling learning from under-sampled data alone, but most existing methods rely on further partitioned under-sampled k-space data as model's input for training, resulting in a loss of valuable information. Additionally, their models have not fully incorporated image priors, leading to degraded reconstruction performance. In this paper, we propose a novel re-visible dual-domain self-supervised deep unfolding network to address these issues when only under-sampled datasets are available. Specifically, by incorporating re-visible dual-domain loss, all under-sampled k-space data are utilized during training to mitigate information loss caused by further partitioning. This design enables the model to implicitly adapt to all under-sampled k-space data as input. Additionally, we design a deep unfolding network based on Chambolle and Pock Proximal Point Algorithm (DUN-CP-PPA) to achieve end-to-end reconstruction, incorporating imaging physics and image priors to guide the reconstruction process. By employing a Spatial-Frequency Feature Extraction (SFFE) block to capture global and local feature representation, we enhance the model's efficiency to learn comprehensive image priors. Experiments conducted on the fastMRI and IXI datasets demonstrate that our method significantly outperforms state-of-the-art approaches in terms of reconstruction performance.
Lightweight Design and Optimization methods for DCNNs: Progress and Futures
Dec 22, 2024



Lightweight design, as a key approach to mitigate disparity between computational requirements of deep learning models and hardware performance, plays a pivotal role in advancing application of deep learning technologies on mobile and embedded devices, alongside rapid development of smart home, telemedicine, and autonomous driving. With its outstanding feature extracting capabilities, Deep Convolutional Neural Networks (DCNNs) have demonstrated superior performance in computer vision tasks. However, high computational costs and large network architectures severely limit the widespread application of DCNNs on resource-constrained hardware platforms such as smartphones, robots, and IoT devices. This paper reviews lightweight design strategies for DCNNs and examines recent research progress in both lightweight architectural design and model compression. Additionally, this paper discusses current limitations in this field of research and propose prospects for future directions, aiming to provide valuable guidance and reflection for lightweight design philosophy on deep neural networks in the field of computer vision.
InterHub: A Naturalistic Trajectory Dataset with Dense Interaction for Autonomous Driving
Nov 30, 2024



The driving interaction-a critical yet complex aspect of daily driving-lies at the core of autonomous driving research. However, real-world driving scenarios sparsely capture rich interaction events, limiting the availability of comprehensive trajectory datasets for this purpose. To address this challenge, we present InterHub, a dense interaction dataset derived by mining interaction events from extensive naturalistic driving records. We employ formal methods to describe and extract multi-agent interaction events, exposing the limitations of existing autonomous driving solutions. Additionally, we introduce a user-friendly toolkit enabling the expansion of InterHub with both public and private data. By unifying, categorizing, and analyzing diverse interaction events, InterHub facilitates cross-comparative studies and large-scale research, thereby advancing the evaluation and development of autonomous driving technologies.