 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Convolutional Networks for Panoptic Segmentation
Dec 01, 2020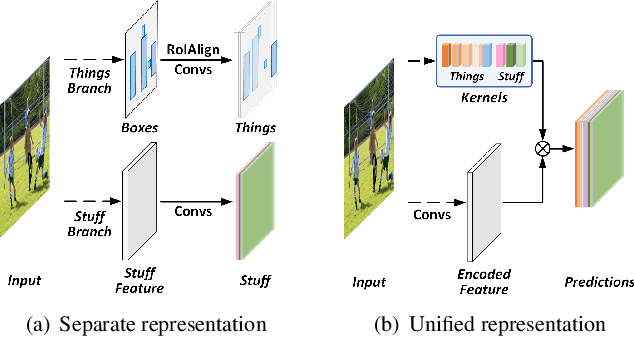
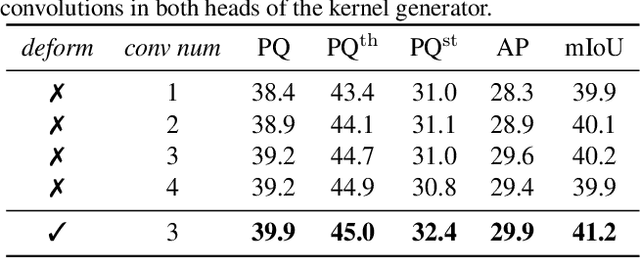
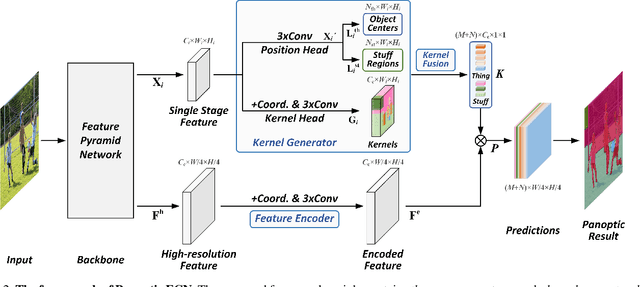
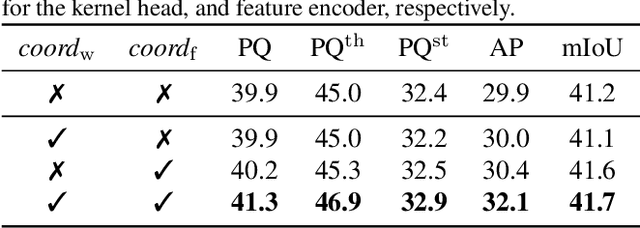
In this paper, we present a conceptually simple, strong, and efficient framework for panoptic segmentation, called Panoptic FCN. Our approach aims to represent and predict foreground things and background stuff in a unified fully convolutional pipeline. In particular, Panoptic FCN encodes each object instance or stuff category into a specific kernel weight with the proposed kernel generator and produces the prediction by convolving the high-resolution feature directly. With this approach, instance-aware and semantically consistent properties for things and stuff can be respectively satisfied in a simple generate-kernel-then-segment workflow. Without extra boxes for localization or instance separation, the proposed approach outperforms previous box-based and -free models with high efficiency on COCO, Cityscapes, and Mapillary Vistas datasets with single scale input. Our code is made publicly available at https://github.com/yanwei-li/PanopticFCN.
UPFlow: Upsampling Pyramid for Unsupervised Optical Flow Learning
Dec 01, 2020
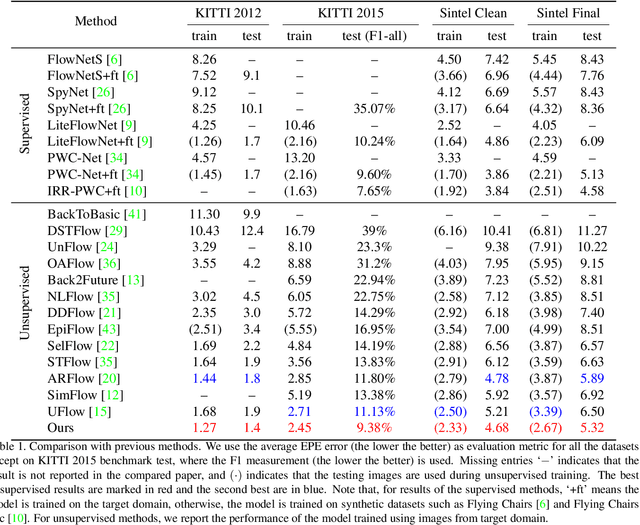
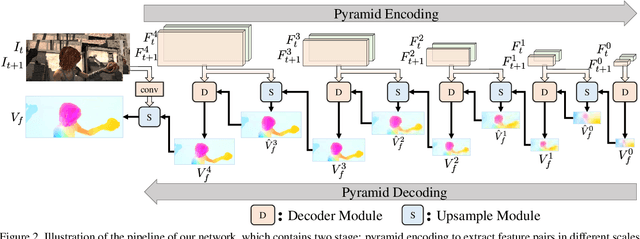
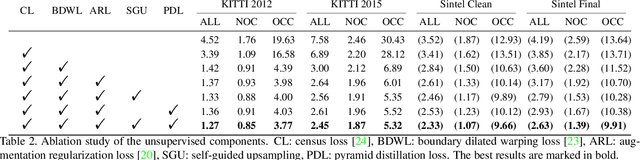
We present an unsupervised learning approach for optical flow estimation by improving the upsampling and learning of pyramid network. We design a self-guided upsample module to tackle the interpolation blur problem caused by bilinear upsampling between pyramid levels. Moreover, we propose a pyramid distillation loss to add supervision for intermediate levels via distilling the finest flow as pseudo labels. By integrating these two components together, our method achieves the best performance for unsupervised optical flow learning on multiple leading benchmarks, including MPI-SIntel, KITTI 2012 and KITTI 2015. In particular, we achieve EPE=1.4 on KITTI 2012 and F1=9.38% on KITTI 2015, which outperform the previous state-of-the-art methods by 22.2% and 15.7%, respectively.
Deep Positional and Relational Feature Learning for Rotation-Invariant Point Cloud Analysis
Nov 18, 2020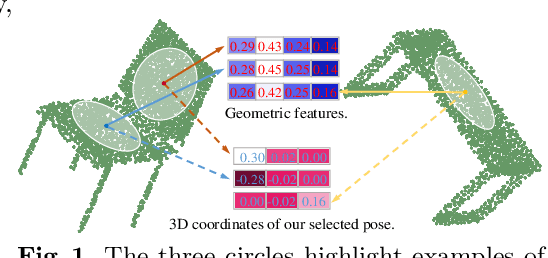
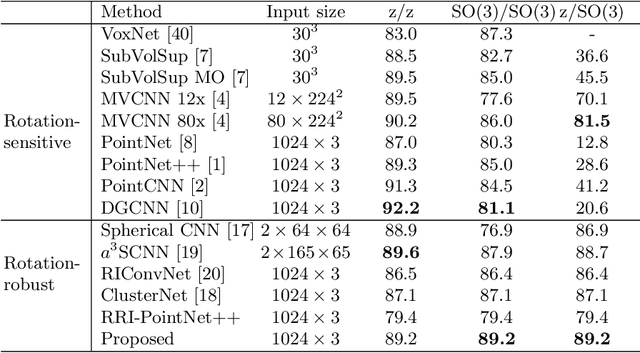
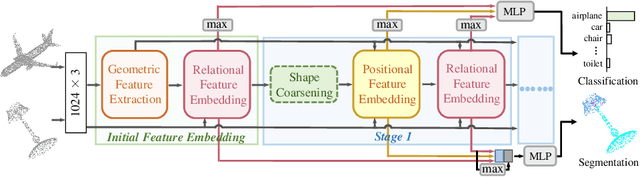
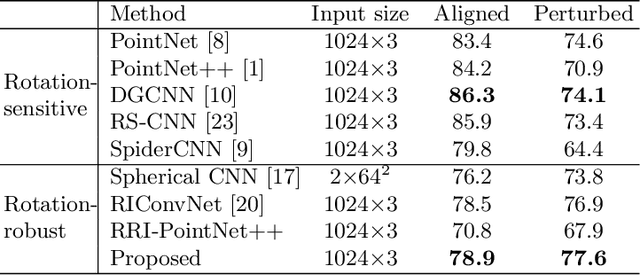
In this paper we propose a rotation-invariant deep network for point clouds analysis. Point-based deep networks are commonly designed to recognize roughly aligned 3D shapes based on point coordinates, but suffer from performance drops with shape rotations. Some geometric features, e.g., distances and angles of points as inputs of network, are rotation-invariant but lose positional information of points. In this work, we propose a novel deep network for point clouds by incorporating positional information of points as inputs while yielding rotation-invariance. The network is hierarchical and relies on two modules: a positional feature embedding block and a relational feature embedding block. Both modules and the whole network are proven to be rotation-invariant when processing point clouds as input. Experiments show state-of-the-art classification and segmentation performances on benchmark datasets, and ablation studies demonstrate effectiveness of the network design.
Joint COCO and Mapillary Workshop at ICCV 2019: COCO Instance Segmentation Challenge Track
Oct 06, 2020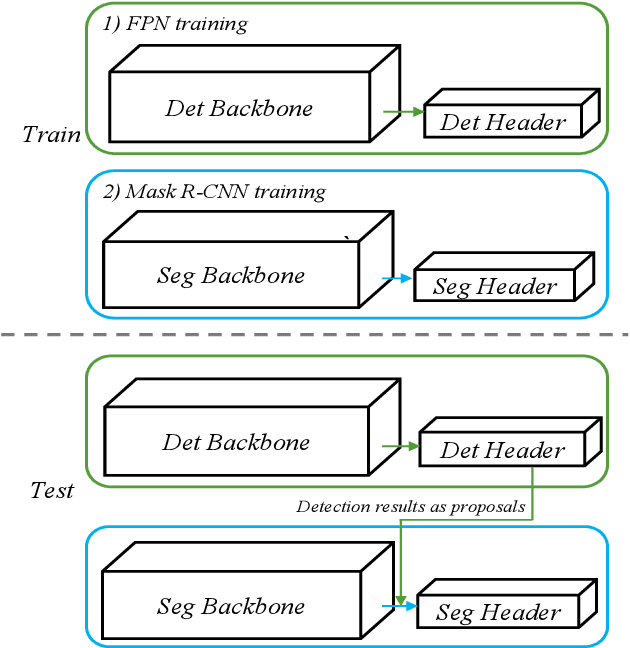

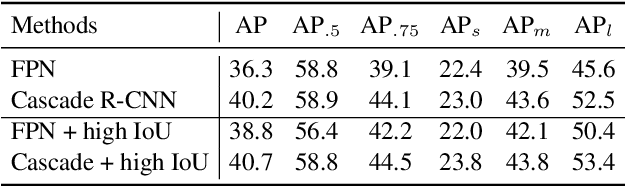
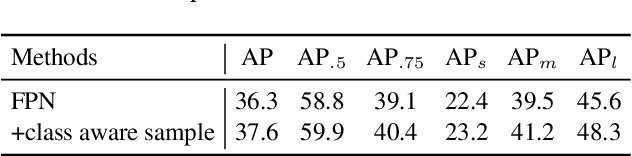
In this report, we present our object detection/instance segmentation system, MegDetV2, which works in a two-pass fashion, first to detect instances then to obtain segmentation. Our baseline detector is mainly built on a new designed RPN, called RPN++. On the COCO-2019 detection/instance-segmentation test-dev dataset, our system achieves 61.0/53.1 mAP, which surpassed our 2018 winning results by 5.0/4.2 respectively. We achieve the best results in COCO Challenge 2019 and 2020.
EqCo: Equivalent Rules for Self-supervised Contrastive Learning
Oct 05, 2020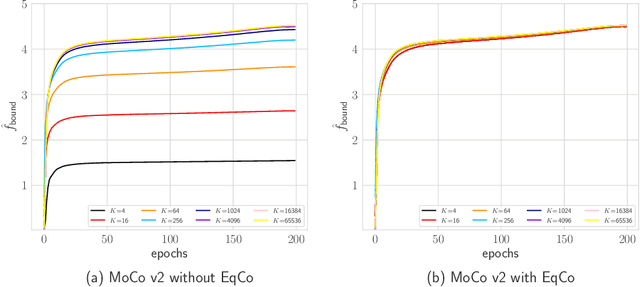

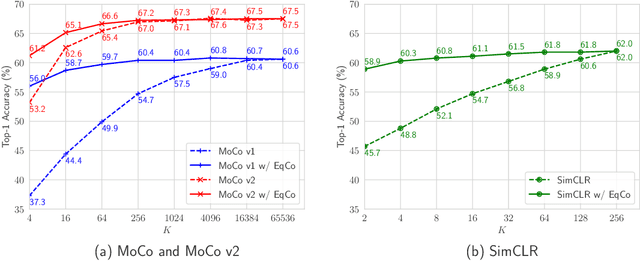
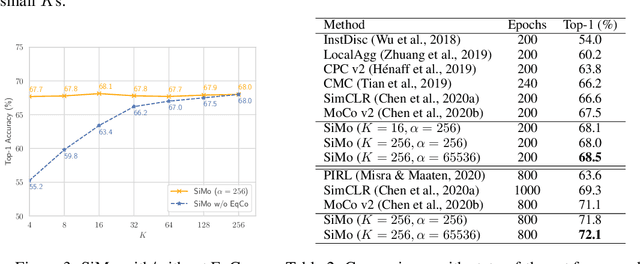
In this paper, we propose a method, named EqCo (Equivalent Rules for Contrastive Learning), to make self-supervised learning irrelevant to the number of negative samples in the contrastive learning framework. Inspired by the infomax principle, we point that the margin term in contrastive loss needs to be adaptively scaled according to the number of negative pairs in order to keep steady mutual information bound and gradient magnitude. EqCo bridges the performance gap among a wide range of negative sample sizes, so that for the first time, we can perform self-supervised contrastive training using only a few negative pairs (e.g.smaller than 256 per query) on large-scale vision tasks like ImageNet, while with little accuracy drop. This is quite a contrast to the widely used large batch training or memory bank mechanism in current practices. Equipped with EqCo, our simplified MoCo (SiMo) achieves comparable accuracy with MoCo v2 on ImageNet (linear evaluation protocol) while only involves 16 negative pairs per query instead of 65536, suggesting that large quantities of negative samples might not be a critical factor in contrastive learning frameworks.
Activate or Not: Learning Customized Activation
Sep 10, 2020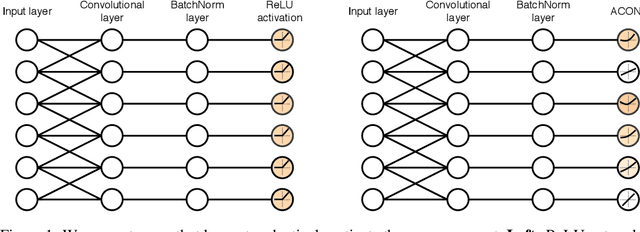

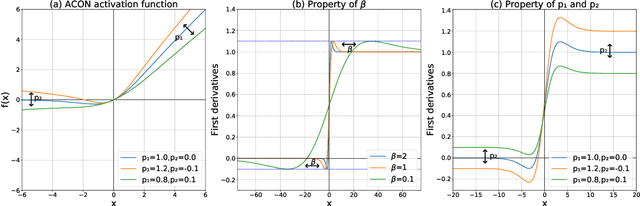
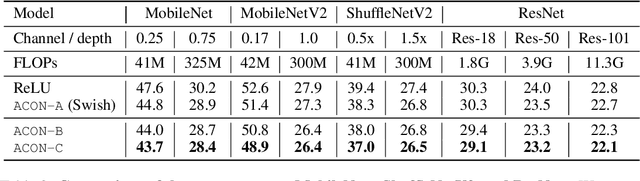
Modern activation layers use non-linear functions to activate the neurons. In this paper, we present a simple but effective activation function we term ACON which learns to activate the neurons or not. Surprisingly, we find Swish, the recent popular NAS-searched activation, can be interpreted as a smooth approximation to ReLU. Intuitively, in the same way, we approximate the variants in the ReLU family to the Swish family, we call ACON, which makes Swish a special case of ACON and remarkably improves the performance. Next, we present meta-ACON, which explicitly learns to optimize the parameter switching between non-linear (activate) and linear (inactivate) and provides a new design space. By simply changing the activation function, we improve the ImageNet top-1 accuracy rate by 6.7% and 1.8% on MobileNet-0.25 and ResNet-152, respectively.
A Survey on Complex Question Answering over Knowledge Base: Recent Advances and Challenges
Jul 26, 2020
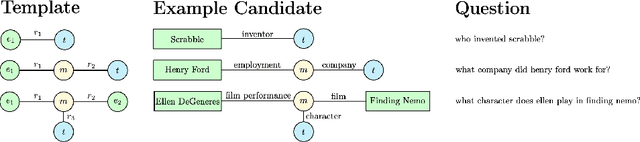
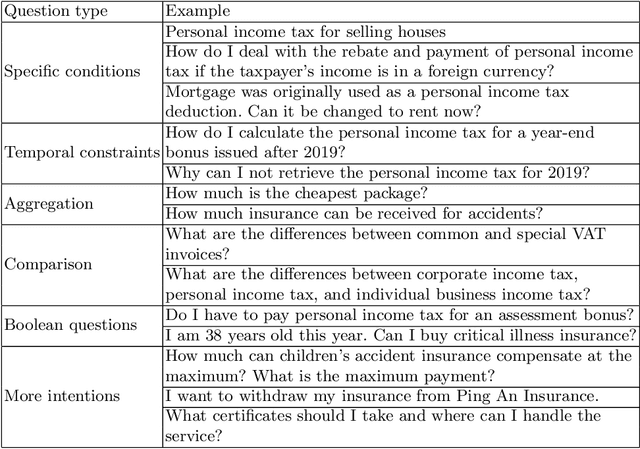

Question Answering (QA) over Knowledge Base (KB) aims to automatically answer natural language questions via well-structured relation information between entities stored in knowledge bases. In order to make KBQA more applicable in actual scenarios, researchers have shifted their attention from simple questions to complex questions, which require more KB triples and constraint inference. In this paper, we introduce the recent advances in complex QA. Besides traditional methods relying on templates and rules, the research is categorized into a taxonomy that contains two main branches, namely Information Retrieval-based and Neural Semantic Parsing-based. After describing the methods of these branches, we analyze directions for future research and introduce the models proposed by the Alime team.
WeightNet: Revisiting the Design Space of Weight Networks
Jul 24, 2020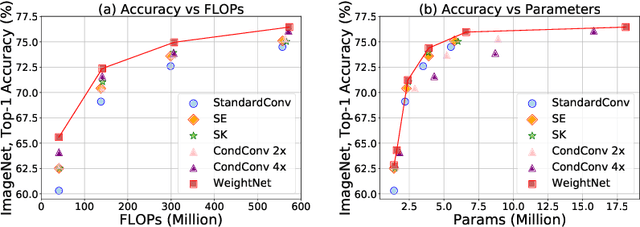
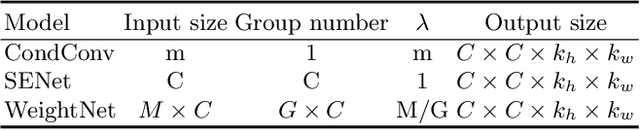
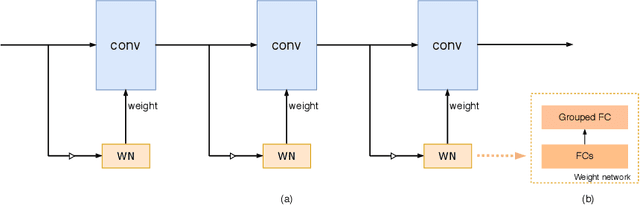
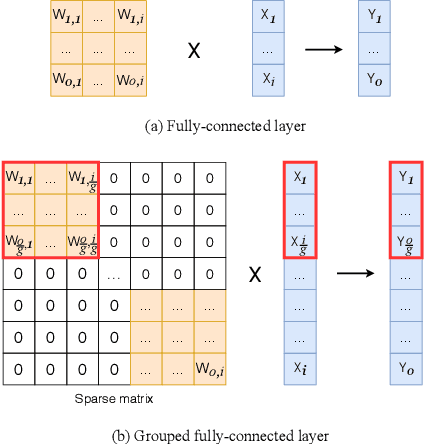
We present a conceptually simple, flexible and effective framework for weight generating networks. Our approach is general that unifies two current distinct and extremely effective SENet and CondConv into the same framework on weight space. The method, called WeightNet, generalizes the two methods by simply adding one more grouped fully-connected layer to the attention activation layer. We use the WeightNet, composed entirely of (grouped) fully-connected layers, to directly output the convolutional weight. WeightNet is easy and memory-conserving to train, on the kernel space instead of the feature space. Because of the flexibility, our method outperforms existing approaches on both ImageNet and COCO detection tasks, achieving better Accuracy-FLOPs and Accuracy-Parameter trade-offs. The framework on the flexible weight space has the potential to further improve the performance. Code is available at https://github.com/megvii-model/WeightNet.
Funnel Activation for Visual Recognition
Jul 24, 2020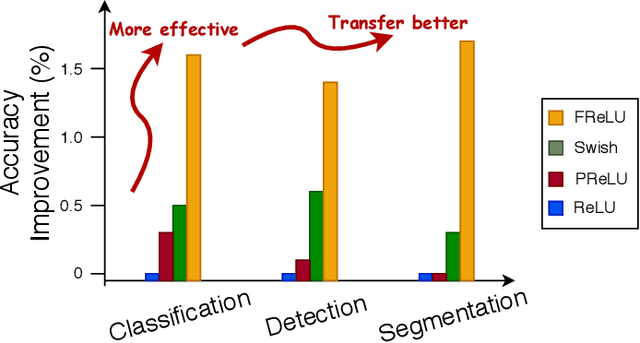
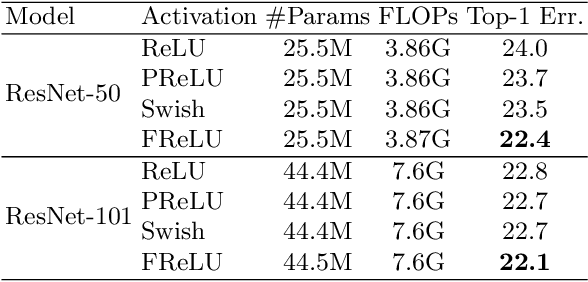
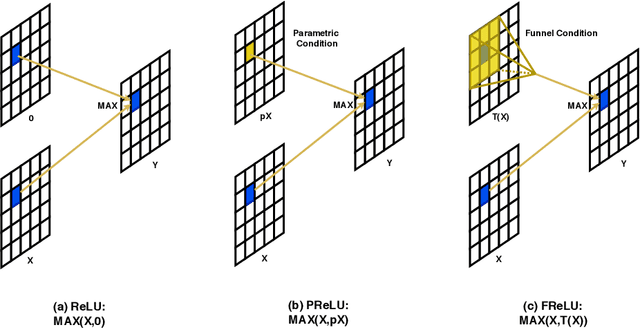
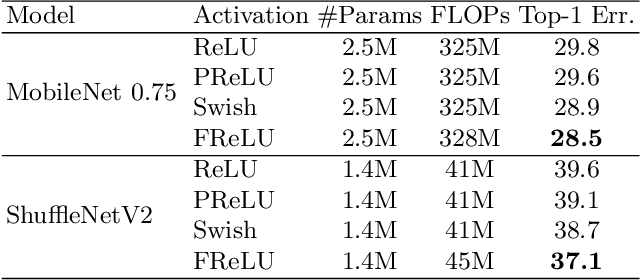
We present a conceptually simple but effective funnel activation for image recognition tasks, called Funnel activation (FReLU), that extends ReLU and PReLU to a 2D activation by adding a negligible overhead of spatial condition. The forms of ReLU and PReLU are y = max(x, 0) and y = max(x, px), respectively, while FReLU is in the form of y = max(x,T(x)), where T(x) is the 2D spatial condition. Moreover, the spatial condition achieves a pixel-wise modeling capacity in a simple way, capturing complicated visual layouts with regular convolutions. We conduct experiments on ImageNet, COCO detection, and semantic segmentation tasks, showing great improvements and robustness of FReLU in the visual recognition tasks. Code is available at https://github.com/megvii-model/FunnelAct.
BorderDet: Border Feature for Dense Object Detection
Jul 21, 2020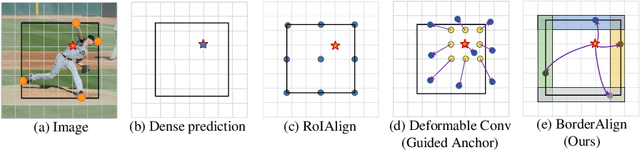
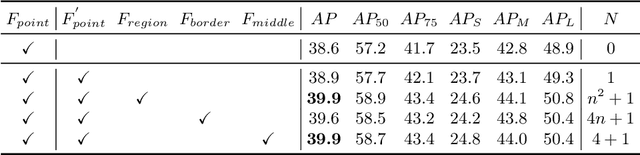
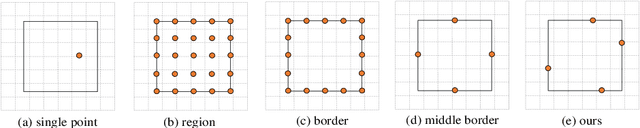
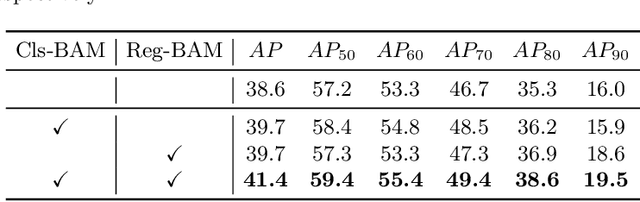
Dense object detectors rely on the sliding-window paradigm that predicts the object over a regular grid of image. Meanwhile, the feature maps on the point of the grid are adopted to generate the bounding box predictions. The point feature is convenient to use but may lack the explicit border information for accurate localization. In this paper, We propose a simple and efficient operator called Border-Align to extract "border features" from the extreme point of the border to enhance the point feature. Based on the BorderAlign, we design a novel detection architecture called BorderDet, which explicitly exploits the border information for stronger classification and more accurate localization. With ResNet-50 backbone, our method improves single-stage detector FCOS by 2.8 AP gains (38.6 v.s. 41.4). With the ResNeXt-101-DCN backbone, our BorderDet obtains 50.3 AP, outperforming the existing state-of-the-art approaches. The code is available at (https://github.com/Megvii-BaseDetection/BorderDet).