 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSource-Aware Embedding Training on Heterogeneous Information Networks
Jul 10, 2023Heterogeneous information networks (HINs) have been extensively applied to real-world tasks, such as recommendation systems, social networks, and citation networks. While existing HIN representation learning methods can effectively learn the semantic and structural features in the network, little awareness was given to the distribution discrepancy of subgraphs within a single HIN. However, we find that ignoring such distribution discrepancy among subgraphs from multiple sources would hinder the effectiveness of graph embedding learning algorithms. This motivates us to propose SUMSHINE (Scalable Unsupervised Multi-Source Heterogeneous Information Network Embedding) -- a scalable unsupervised framework to align the embedding distributions among multiple sources of an HIN. Experimental results on real-world datasets in a variety of downstream tasks validate the performance of our method over the state-of-the-art heterogeneous information network embedding algorithms.
Making the Most of What You Have: Adapting Pre-trained Visual Language Models in the Low-data Regime
May 03, 2023



Large-scale visual language models are widely used as pre-trained models and then adapted for various downstream tasks. While humans are known to efficiently learn new tasks from a few examples, deep learning models struggle with adaptation from few examples. In this work, we look into task adaptation in the low-data regime, and provide a thorough study of the existing adaptation methods for generative Visual Language Models. And we show important benefits of self-labelling, i.e. using the model's own predictions to self-improve when having access to a larger number of unlabelled images of the same distribution. Our study demonstrates significant gains using our proposed task adaptation pipeline across a wide range of visual language tasks such as visual classification (ImageNet), visual captioning (COCO), detailed visual captioning (Localised Narratives) and visual question answering (VQAv2).
On the Benefits of Leveraging Structural Information in Planning Over the Learned Model
Mar 15, 2023



Model-based Reinforcement Learning (RL) integrates learning and planning and has received increasing attention in recent years. However, learning the model can incur a significant cost (in terms of sample complexity), due to the need to obtain a sufficient number of samples for each state-action pair. In this paper, we investigate the benefits of leveraging structural information about the system in terms of reducing sample complexity. Specifically, we consider the setting where the transition probability matrix is a known function of a number of structural parameters, whose values are initially unknown. We then consider the problem of estimating those parameters based on the interactions with the environment. We characterize the difference between the Q estimates and the optimal Q value as a function of the number of samples. Our analysis shows that there can be a significant saving in sample complexity by leveraging structural information about the model. We illustrate the findings by considering several problems including controlling a queuing system with heterogeneous servers, and seeking an optimal path in a stochastic windy gridworld.
NEVIS'22: A Stream of 100 Tasks Sampled from 30 Years of Computer Vision Research
Nov 15, 2022We introduce the Never Ending VIsual-classification Stream (NEVIS'22), a benchmark consisting of a stream of over 100 visual classification tasks, sorted chronologically and extracted from papers sampled uniformly from computer vision proceedings spanning the last three decades. The resulting stream reflects what the research community thought was meaningful at any point in time. Despite being limited to classification, the resulting stream has a rich diversity of tasks from OCR, to texture analysis, crowd counting, scene recognition, and so forth. The diversity is also reflected in the wide range of dataset sizes, spanning over four orders of magnitude. Overall, NEVIS'22 poses an unprecedented challenge for current sequential learning approaches due to the scale and diversity of tasks, yet with a low entry barrier as it is limited to a single modality and each task is a classical supervised learning problem. Moreover, we provide a reference implementation including strong baselines and a simple evaluation protocol to compare methods in terms of their trade-off between accuracy and compute. We hope that NEVIS'22 can be useful to researchers working on continual learning, meta-learning, AutoML and more generally sequential learning, and help these communities join forces towards more robust and efficient models that efficiently adapt to a never ending stream of data. Implementations have been made available at https://github.com/deepmind/dm_nevis.
SL3D: Self-supervised-Self-labeled 3D Recognition
Nov 03, 2022



There are a lot of promising results in 3D recognition, including classification, object detection, and semantic segmentation. However, many of these results rely on manually collecting densely annotated real-world 3D data, which is highly time-consuming and expensive to obtain, limiting the scalability of 3D recognition tasks. Thus in this paper, we study unsupervised 3D recognition and propose a Self-supervised-Self-Labeled 3D Recognition (SL3D) framework. SL3D simultaneously solves two coupled objectives, i.e., clustering and learning feature representation to generate pseudo labeled data for unsupervised 3D recognition. SL3D is a generic framework and can be applied to solve different 3D recognition tasks, including classification, object detection, and semantic segmentation. Extensive experiments demonstrate its effectiveness. Code is available at https://github.com/fcendra/sl3d.
Towards Efficient and Scale-Robust Ultra-High-Definition Image Demoireing
Jul 20, 2022


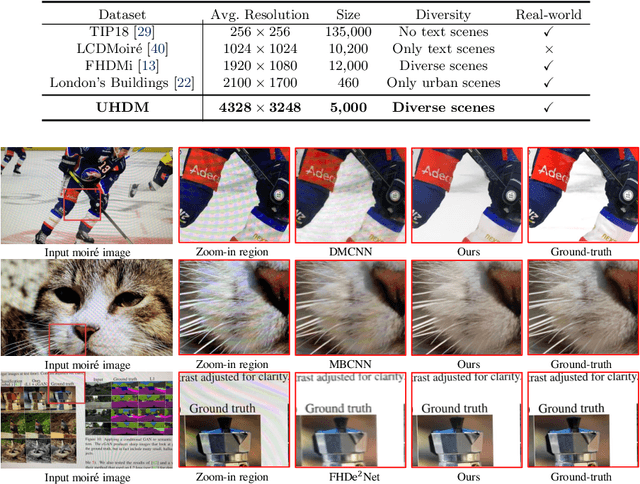
With the rapid development of mobile devices, modern widely-used mobile phones typically allow users to capture 4K resolution (i.e., ultra-high-definition) images. However, for image demoireing, a challenging task in low-level vision, existing works are generally carried out on low-resolution or synthetic images. Hence, the effectiveness of these methods on 4K resolution images is still unknown. In this paper, we explore moire pattern removal for ultra-high-definition images. To this end, we propose the first ultra-high-definition demoireing dataset (UHDM), which contains 5,000 real-world 4K resolution image pairs, and conduct a benchmark study on current state-of-the-art methods. Further, we present an efficient baseline model ESDNet for tackling 4K moire images, wherein we build a semantic-aligned scale-aware module to address the scale variation of moire patterns. Extensive experiments manifest the effectiveness of our approach, which outperforms state-of-the-art methods by a large margin while being much more lightweight. Code and dataset are available at https://xinyu-andy.github.io/uhdm-page.
Federated Self-supervised Learning for Video Understanding
Jul 05, 2022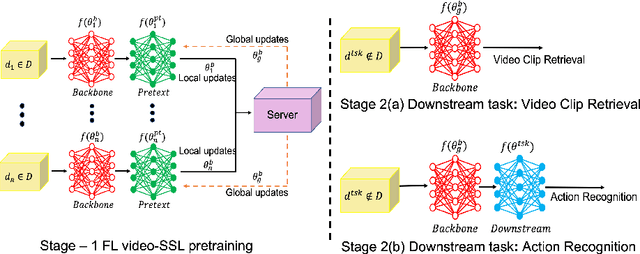
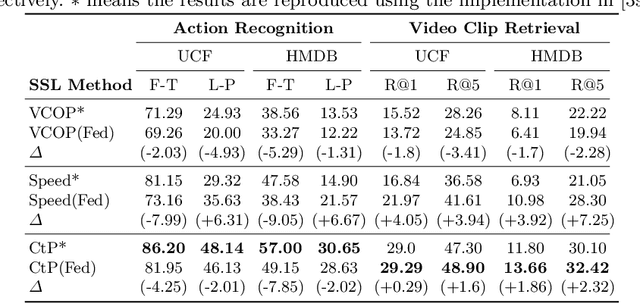
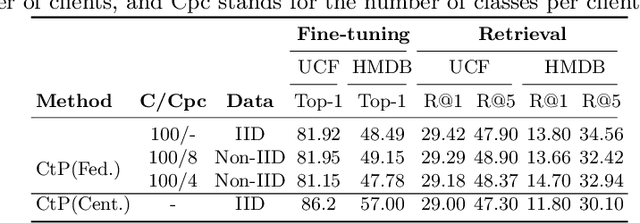
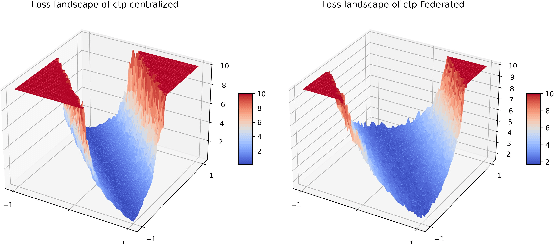
The ubiquity of camera-enabled mobile devices has lead to large amounts of unlabelled video data being produced at the edge. Although various self-supervised learning (SSL) methods have been proposed to harvest their latent spatio-temporal representations for task-specific training, practical challenges including privacy concerns and communication costs prevent SSL from being deployed at large scales. To mitigate these issues, we propose the use of Federated Learning (FL) to the task of video SSL. In this work, we evaluate the performance of current state-of-the-art (SOTA) video-SSL techniques and identify their shortcomings when integrated into the large-scale FL setting simulated with kinetics-400 dataset. We follow by proposing a novel federated SSL framework for video, dubbed FedVSSL, that integrates different aggregation strategies and partial weight updating. Extensive experiments demonstrate the effectiveness and significance of FedVSSL as it outperforms the centralized SOTA for the downstream retrieval task by 6.66% on UCF-101 and 5.13% on HMDB-51.
Reconstruct Face from Features Using GAN Generator as a Distribution Constraint
Jun 09, 2022
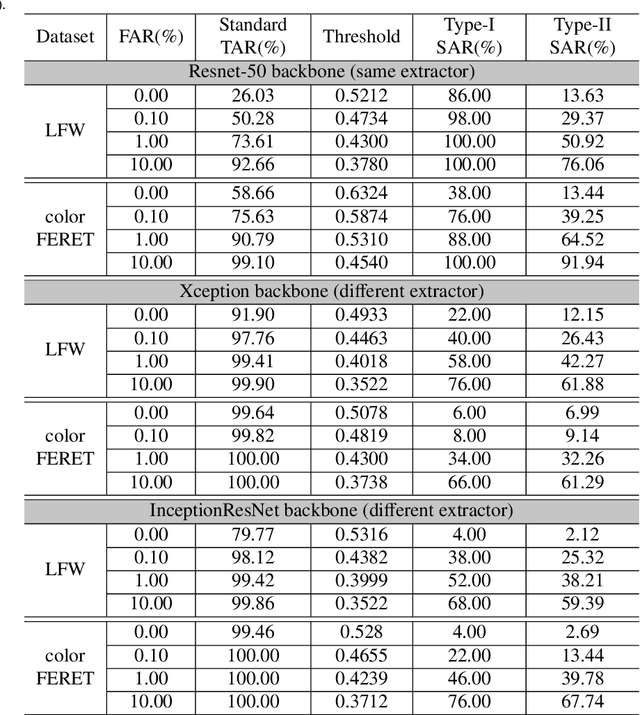
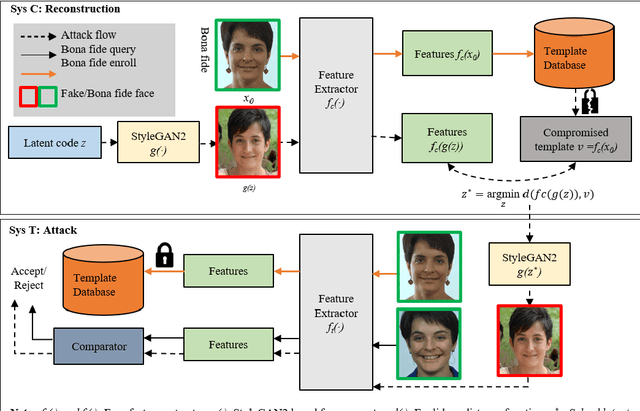
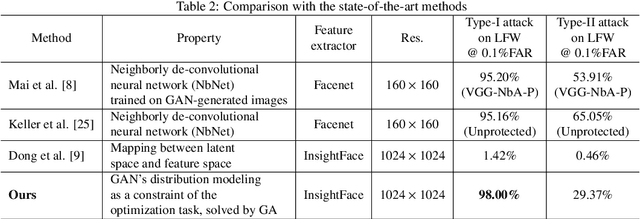
Face recognition based on the deep convolutional neural networks (CNN) shows superior accuracy performance attributed to the high discriminative features extracted. Yet, the security and privacy of the extracted features from deep learning models (deep features) have been often overlooked. This paper proposes the reconstruction of face images from deep features without accessing the CNN network configurations as a constrained optimization problem. Such optimization minimizes the distance between the features extracted from the original face image and the reconstructed face image. Instead of directly solving the optimization problem in the image space, we innovatively reformulate the problem by looking for a latent vector of a GAN generator, then use it to generate the face image. The GAN generator serves as a dual role in this novel framework, i.e., face distribution constraint of the optimization goal and a face generator. On top of the novel optimization task, we also propose an attack pipeline to impersonate the target user based on the generated face image. Our results show that the generated face images can achieve a state-of-the-art successful attack rate of 98.0\% on LFW under type-I attack @ FAR of 0.1\%. Our work sheds light on the biometric deployment to meet the privacy-preserving and security policies.
Video Demoireing with Relation-Based Temporal Consistency
Apr 06, 2022
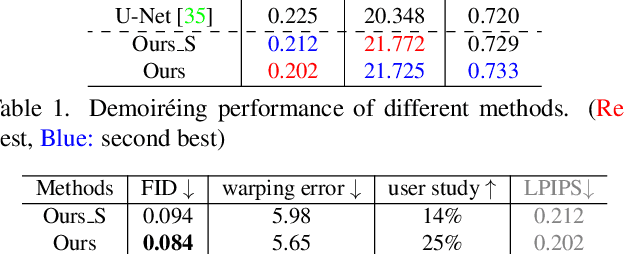

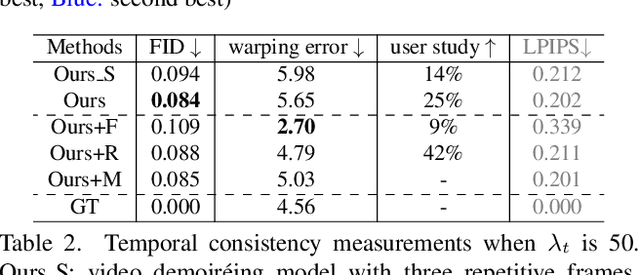
Moire patterns, appearing as color distortions, severely degrade image and video qualities when filming a screen with digital cameras. Considering the increasing demands for capturing videos, we study how to remove such undesirable moire patterns in videos, namely video demoireing. To this end, we introduce the first hand-held video demoireing dataset with a dedicated data collection pipeline to ensure spatial and temporal alignments of captured data. Further, a baseline video demoireing model with implicit feature space alignment and selective feature aggregation is developed to leverage complementary information from nearby frames to improve frame-level video demoireing. More importantly, we propose a relation-based temporal consistency loss to encourage the model to learn temporal consistency priors directly from ground-truth reference videos, which facilitates producing temporally consistent predictions and effectively maintains frame-level qualities. Extensive experiments manifest the superiority of our model. Code is available at \url{https://daipengwa.github.io/VDmoire_ProjectPage/}.
Abandoning the Bayer-Filter to See in the Dark
Mar 22, 2022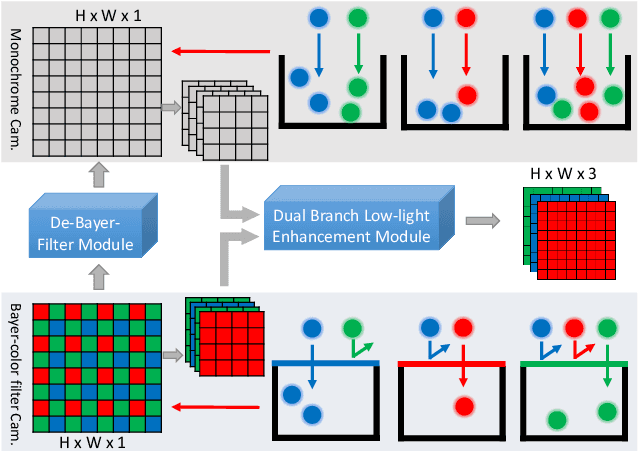


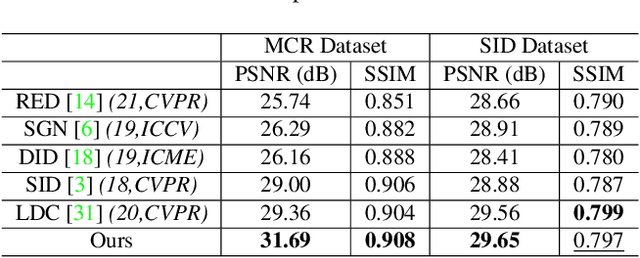
Low-light image enhancement - a pervasive but challenging problem, plays a central role in enhancing the visibility of an image captured in a poor illumination environment. Due to the fact that not all photons can pass the Bayer-Filter on the sensor of the color camera, in this work, we first present a De-Bayer-Filter simulator based on deep neural networks to generate a monochrome raw image from the colored raw image. Next, a fully convolutional network is proposed to achieve the low-light image enhancement by fusing colored raw data with synthesized monochrome raw data. Channel-wise attention is also introduced to the fusion process to establish a complementary interaction between features from colored and monochrome raw images. To train the convolutional networks, we propose a dataset with monochrome and color raw pairs named Mono-Colored Raw paired dataset (MCR) collected by using a monochrome camera without Bayer-Filter and a color camera with Bayer-Filter. The proposed pipeline take advantages of the fusion of the virtual monochrome and the color raw images and our extensive experiments indicate that significant improvement can be achieved by leveraging raw sensor data and data-driven learning.