 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Self-supervised Learning for Video Understanding
Jul 05, 2022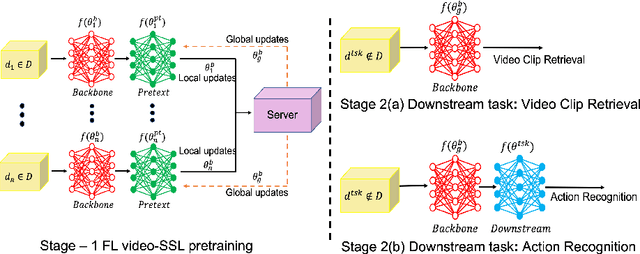
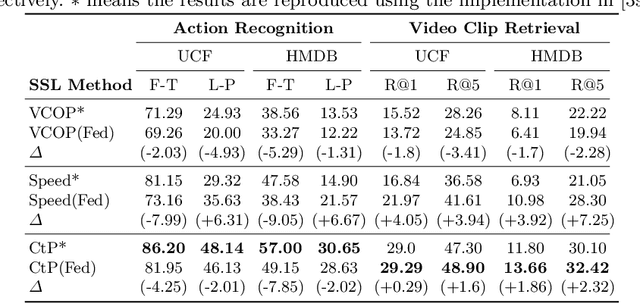
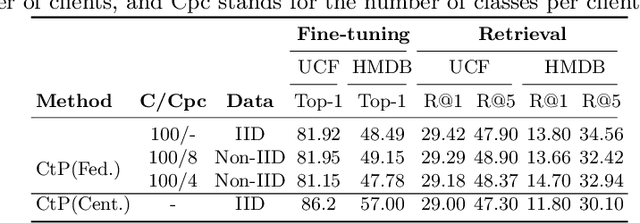
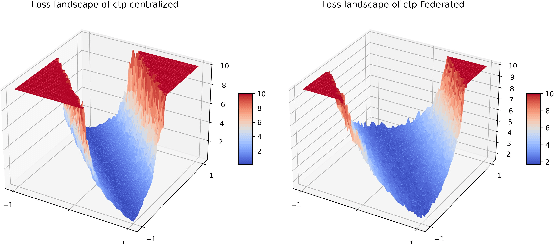
The ubiquity of camera-enabled mobile devices has lead to large amounts of unlabelled video data being produced at the edge. Although various self-supervised learning (SSL) methods have been proposed to harvest their latent spatio-temporal representations for task-specific training, practical challenges including privacy concerns and communication costs prevent SSL from being deployed at large scales. To mitigate these issues, we propose the use of Federated Learning (FL) to the task of video SSL. In this work, we evaluate the performance of current state-of-the-art (SOTA) video-SSL techniques and identify their shortcomings when integrated into the large-scale FL setting simulated with kinetics-400 dataset. We follow by proposing a novel federated SSL framework for video, dubbed FedVSSL, that integrates different aggregation strategies and partial weight updating. Extensive experiments demonstrate the effectiveness and significance of FedVSSL as it outperforms the centralized SOTA for the downstream retrieval task by 6.66% on UCF-101 and 5.13% on HMDB-51.
A first look into the carbon footprint of federated learning
Feb 15, 2021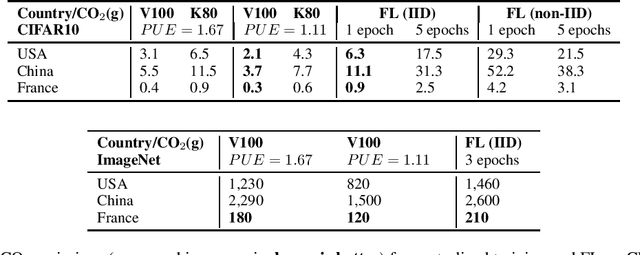
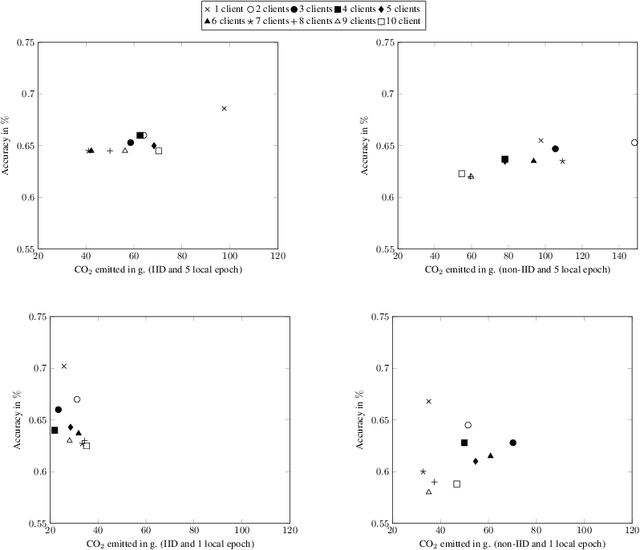
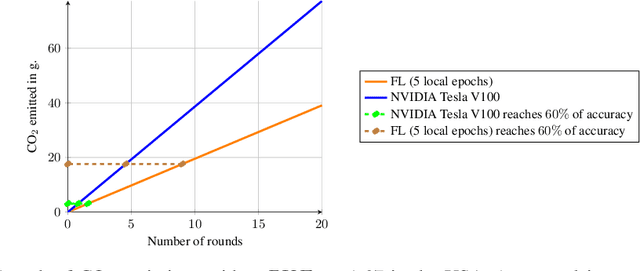
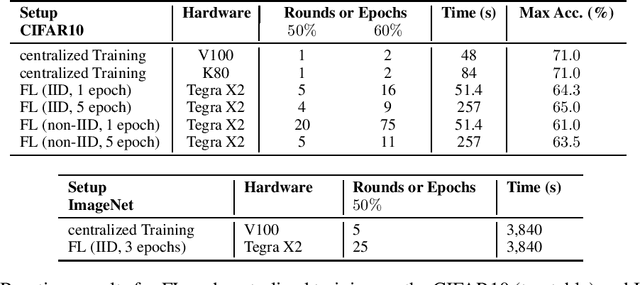
Despite impressive results, deep learning-based technologies also raise severe privacy and environmental concerns induced by the training procedure often conducted in datacenters. In response, alternatives to centralized training such as Federated Learning (FL) have emerged. Perhaps unexpectedly, FL, in particular, is starting to be deployed at a global scale by companies that must adhere to new legal demands and policies originating from governments and civil society for privacy protection. However, the potential environmental impact related to FL remains unclear and unexplored. This paper offers the first-ever systematic study of the carbon footprint of FL. First, we propose a rigorous model to quantify the carbon footprint, hence facilitating the investigation of the relationship between FL design and carbon emissions. Then, we compare the carbon footprint of FL to traditional centralized learning. Our findings show that FL, despite being slower to converge in some cases, may result in a comparatively greener impact than a centralized equivalent setup. We performed extensive experiments across different types of datasets, settings, and various deep learning models with FL. Finally, we highlight and connect the reported results to the future challenges and trends in FL to reduce its environmental impact, including algorithms efficiency, hardware capabilities, and stronger industry transparency.