 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnatomy-Aware Low-Dose CT Denoising via Pretrained Vision Models and Semantic-Guided Contrastive Learning
Aug 11, 2025To reduce radiation exposure and improve the diagnostic efficacy of low-dose computed tomography (LDCT), numerous deep learning-based denoising methods have been developed to mitigate noise and artifacts. However, most of these approaches ignore the anatomical semantics of human tissues, which may potentially result in suboptimal denoising outcomes. To address this problem, we propose ALDEN, an anatomy-aware LDCT denoising method that integrates semantic features of pretrained vision models (PVMs) with adversarial and contrastive learning. Specifically, we introduce an anatomy-aware discriminator that dynamically fuses hierarchical semantic features from reference normal-dose CT (NDCT) via cross-attention mechanisms, enabling tissue-specific realism evaluation in the discriminator. In addition, we propose a semantic-guided contrastive learning module that enforces anatomical consistency by contrasting PVM-derived features from LDCT, denoised CT and NDCT, preserving tissue-specific patterns through positive pairs and suppressing artifacts via dual negative pairs. Extensive experiments conducted on two LDCT denoising datasets reveal that ALDEN achieves the state-of-the-art performance, offering superior anatomy preservation and substantially reducing over-smoothing issue of previous work. Further validation on a downstream multi-organ segmentation task (encompassing 117 anatomical structures) affirms the model's ability to maintain anatomical awareness.
Anatomy-Aware Conditional Image-Text Retrieval
Mar 10, 2025



Image-Text Retrieval (ITR) finds broad applications in healthcare, aiding clinicians and radiologists by automatically retrieving relevant patient cases in the database given the query image and/or report, for more efficient clinical diagnosis and treatment, especially for rare diseases. However conventional ITR systems typically only rely on global image or text representations for measuring patient image/report similarities, which overlook local distinctiveness across patient cases. This often results in suboptimal retrieval performance. In this paper, we propose an Anatomical Location-Conditioned Image-Text Retrieval (ALC-ITR) framework, which, given a query image and the associated suspicious anatomical region(s), aims to retrieve similar patient cases exhibiting the same disease or symptoms in the same anatomical region. To perform location-conditioned multimodal retrieval, we learn a medical Relevance-Region-Aligned Vision Language (RRA-VL) model with semantic global-level and region-/word-level alignment to produce generalizable, well-aligned multi-modal representations. Additionally, we perform location-conditioned contrastive learning to further utilize cross-pair region-level contrastiveness for improved multi-modal retrieval. We show that our proposed RRA-VL achieves state-of-the-art localization performance in phase-grounding tasks, and satisfying multi-modal retrieval performance with or without location conditioning. Finally, we thoroughly investigate the generalizability and explainability of our proposed ALC-ITR system in providing explanations and preliminary diagnosis reports given retrieved patient cases (conditioned on anatomical regions), with proper off-the-shelf LLM prompts.
Chest X-ray Foundation Model with Global and Local Representations Integration
Feb 07, 2025Chest X-ray (CXR) is the most frequently ordered imaging test, supporting diverse clinical tasks from thoracic disease detection to postoperative monitoring. However, task-specific classification models are limited in scope, require costly labeled data, and lack generalizability to out-of-distribution datasets. To address these challenges, we introduce CheXFound, a self-supervised vision foundation model that learns robust CXR representations and generalizes effectively across a wide range of downstream tasks. We pretrain CheXFound on a curated CXR-1M dataset, comprising over one million unique CXRs from publicly available sources. We propose a Global and Local Representations Integration (GLoRI) module for downstream adaptations, by incorporating disease-specific local features with global image features for enhanced performance in multilabel classification. Our experimental results show that CheXFound outperforms state-of-the-art models in classifying 40 disease findings across different prevalence levels on the CXR-LT 24 dataset and exhibits superior label efficiency on downstream tasks with limited training data. Additionally, CheXFound achieved significant improvements on new tasks with out-of-distribution datasets, including opportunistic cardiovascular disease risk estimation and mortality prediction. These results highlight CheXFound's strong generalization capabilities, enabling diverse adaptations with improved label efficiency. The project source code is publicly available at https://github.com/RPIDIAL/CheXFound.
Integrating AI in College Education: Positive yet Mixed Experiences with ChatGPT
Jul 08, 2024

The integration of artificial intelligence (AI) chatbots into higher education marks a shift towards a new generation of pedagogical tools, mirroring the arrival of milestones like the internet. With the launch of ChatGPT-4 Turbo in November 2023, we developed a ChatGPT-based teaching application (https://chat.openai.com/g/g-1imx1py4K-chatge-medical-imaging) and integrated it into our undergraduate medical imaging course in the Spring 2024 semester. This study investigates the use of ChatGPT throughout a semester-long trial, providing insights into students' engagement, perception, and the overall educational effectiveness of the technology. We systematically collected and analyzed data concerning students' interaction with ChatGPT, focusing on their attitudes, concerns, and usage patterns. The findings indicate that ChatGPT offers significant advantages such as improved information access and increased interactivity, but its adoption is accompanied by concerns about the accuracy of the information provided and the necessity for well-defined guidelines to optimize its use.
Cardiovascular Disease Detection from Multi-View Chest X-rays with BI-Mamba
May 28, 2024



Accurate prediction of Cardiovascular disease (CVD) risk in medical imaging is central to effective patient health management. Previous studies have demonstrated that imaging features in computed tomography (CT) can help predict CVD risk. However, CT entails notable radiation exposure, which may result in adverse health effects for patients. In contrast, chest X-ray emits significantly lower levels of radiation, offering a safer option. This rationale motivates our investigation into the feasibility of using chest X-ray for predicting CVD risk. Convolutional Neural Networks (CNNs) and Transformers are two established network architectures for computer-aided diagnosis. However, they struggle to model very high resolution chest X-ray due to the lack of large context modeling power or quadratic time complexity. Inspired by state space sequence models (SSMs), a new class of network architectures with competitive sequence modeling power as Transfomers and linear time complexity, we propose Bidirectional Image Mamba (BI-Mamba) to complement the unidirectional SSMs with opposite directional information. BI-Mamba utilizes parallel forward and backwark blocks to encode longe-range dependencies of multi-view chest X-rays. We conduct extensive experiments on images from 10,395 subjects in National Lung Screening Trail (NLST). Results show that BI-Mamba outperforms ResNet-50 and ViT-S with comparable parameter size, and saves significant amount of GPU memory during training. Besides, BI-Mamba achieves promising performance compared with previous state of the art in CT, unraveling the potential of chest X-ray for CVD risk prediction.
Disease-informed Adaptation of Vision-Language Models
May 24, 2024In medical image analysis, the expertise scarcity and the high cost of data annotation limits the development of large artificial intelligence models. This paper investigates the potential of transfer learning with pre-trained vision-language models (VLMs) in this domain. Currently, VLMs still struggle to transfer to the underrepresented diseases with minimal presence and new diseases entirely absent from the pretraining dataset. We argue that effective adaptation of VLMs hinges on the nuanced representation learning of disease concepts. By capitalizing on the joint visual-linguistic capabilities of VLMs, we introduce disease-informed contextual prompting in a novel disease prototype learning framework. This approach enables VLMs to grasp the concepts of new disease effectively and efficiently, even with limited data. Extensive experiments across multiple image modalities showcase notable enhancements in performance compared to existing techniques.
Spectral Adversarial MixUp for Few-Shot Unsupervised Domain Adaptation
Sep 03, 2023Domain shift is a common problem in clinical applications, where the training images (source domain) and the test images (target domain) are under different distributions. Unsupervised Domain Adaptation (UDA) techniques have been proposed to adapt models trained in the source domain to the target domain. However, those methods require a large number of images from the target domain for model training. In this paper, we propose a novel method for Few-Shot Unsupervised Domain Adaptation (FSUDA), where only a limited number of unlabeled target domain samples are available for training. To accomplish this challenging task, first, a spectral sensitivity map is introduced to characterize the generalization weaknesses of models in the frequency domain. We then developed a Sensitivity-guided Spectral Adversarial MixUp (SAMix) method to generate target-style images to effectively suppresses the model sensitivity, which leads to improved model generalizability in the target domain. We demonstrated the proposed method and rigorously evaluated its performance on multiple tasks using several public datasets.
Dynamic Ensemble of Low-fidelity Experts: Mitigating NAS "Cold-Start"
Feb 02, 2023Predictor-based Neural Architecture Search (NAS) employs an architecture performance predictor to improve the sample efficiency. However, predictor-based NAS suffers from the severe ``cold-start'' problem, since a large amount of architecture-performance data is required to get a working predictor. In this paper, we focus on exploiting information in cheaper-to-obtain performance estimations (i.e., low-fidelity information) to mitigate the large data requirements of predictor training. Despite the intuitiveness of this idea, we observe that using inappropriate low-fidelity information even damages the prediction ability and different search spaces have different preferences for low-fidelity information types. To solve the problem and better fuse beneficial information provided by different types of low-fidelity information, we propose a novel dynamic ensemble predictor framework that comprises two steps. In the first step, we train different sub-predictors on different types of available low-fidelity information to extract beneficial knowledge as low-fidelity experts. In the second step, we learn a gating network to dynamically output a set of weighting coefficients conditioned on each input neural architecture, which will be used to combine the predictions of different low-fidelity experts in a weighted sum. The overall predictor is optimized on a small set of actual architecture-performance data to fuse the knowledge from different low-fidelity experts to make the final prediction. We conduct extensive experiments across five search spaces with different architecture encoders under various experimental settings. Our method can easily be incorporated into existing predictor-based NAS frameworks to discover better architectures.
When Neural Networks Fail to Generalize? A Model Sensitivity Perspective
Dec 01, 2022Domain generalization (DG) aims to train a model to perform well in unseen domains under different distributions. This paper considers a more realistic yet more challenging scenario,namely Single Domain Generalization (Single-DG), where only a single source domain is available for training. To tackle this challenge, we first try to understand when neural networks fail to generalize? We empirically ascertain a property of a model that correlates strongly with its generalization that we coin as "model sensitivity". Based on our analysis, we propose a novel strategy of Spectral Adversarial Data Augmentation (SADA) to generate augmented images targeted at the highly sensitive frequencies. Models trained with these hard-to-learn samples can effectively suppress the sensitivity in the frequency space, which leads to improved generalization performance. Extensive experiments on multiple public datasets demonstrate the superiority of our approach, which surpasses the state-of-the-art single-DG methods.
Regression Metric Loss: Learning a Semantic Representation Space for Medical Images
Jul 12, 2022
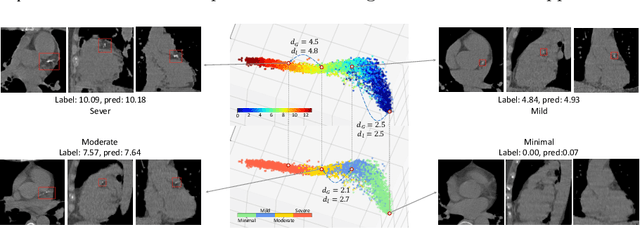
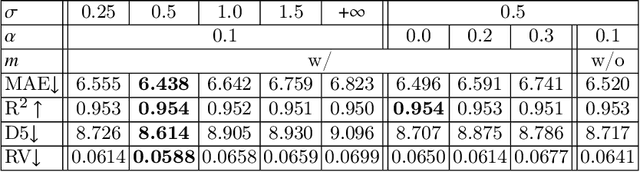
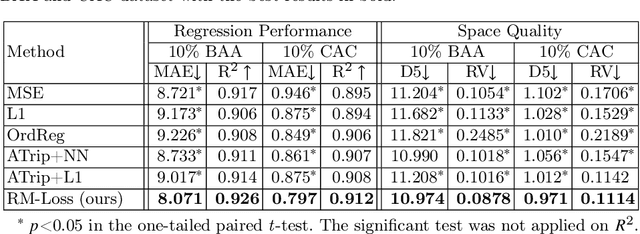
Regression plays an essential role in many medical imaging applications for estimating various clinical risk or measurement scores. While training strategies and loss functions have been studied for the deep neural networks in medical image classification tasks, options for regression tasks are very limited. One of the key challenges is that the high-dimensional feature representation learned by existing popular loss functions like Mean Squared Error or L1 loss is hard to interpret. In this paper, we propose a novel Regression Metric Loss (RM-Loss), which endows the representation space with the semantic meaning of the label space by finding a representation manifold that is isometric to the label space. Experiments on two regression tasks, i.e. coronary artery calcium score estimation and bone age assessment, show that RM-Loss is superior to the existing popular regression losses on both performance and interpretability. Code is available at https://github.com/DIAL-RPI/Regression-Metric-Loss.