 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePOCE: Pose-Controllable Expression Editing
Apr 18, 2023



Facial expression editing has attracted increasing attention with the advance of deep neural networks in recent years. However, most existing methods suffer from compromised editing fidelity and limited usability as they either ignore pose variations (unrealistic editing) or require paired training data (not easy to collect) for pose controls. This paper presents POCE, an innovative pose-controllable expression editing network that can generate realistic facial expressions and head poses simultaneously with just unpaired training images. POCE achieves the more accessible and realistic pose-controllable expression editing by mapping face images into UV space, where facial expressions and head poses can be disentangled and edited separately. POCE has two novel designs. The first is self-supervised UV completion that allows to complete UV maps sampled under different head poses, which often suffer from self-occlusions and missing facial texture. The second is weakly-supervised UV editing that allows to generate new facial expressions with minimal modification of facial identity, where the synthesized expression could be controlled by either an expression label or directly transplanted from a reference UV map via feature transfer. Extensive experiments show that POCE can learn from unpaired face images effectively, and the learned model can generate realistic and high-fidelity facial expressions under various new poses.
StyleRF: Zero-shot 3D Style Transfer of Neural Radiance Fields
Mar 24, 2023



3D style transfer aims to render stylized novel views of a 3D scene with multi-view consistency. However, most existing work suffers from a three-way dilemma over accurate geometry reconstruction, high-quality stylization, and being generalizable to arbitrary new styles. We propose StyleRF (Style Radiance Fields), an innovative 3D style transfer technique that resolves the three-way dilemma by performing style transformation within the feature space of a radiance field. StyleRF employs an explicit grid of high-level features to represent 3D scenes, with which high-fidelity geometry can be reliably restored via volume rendering. In addition, it transforms the grid features according to the reference style which directly leads to high-quality zero-shot style transfer. StyleRF consists of two innovative designs. The first is sampling-invariant content transformation that makes the transformation invariant to the holistic statistics of the sampled 3D points and accordingly ensures multi-view consistency. The second is deferred style transformation of 2D feature maps which is equivalent to the transformation of 3D points but greatly reduces memory footprint without degrading multi-view consistency. Extensive experiments show that StyleRF achieves superior 3D stylization quality with precise geometry reconstruction and it can generalize to various new styles in a zero-shot manner.
Regularized Vector Quantization for Tokenized Image Synthesis
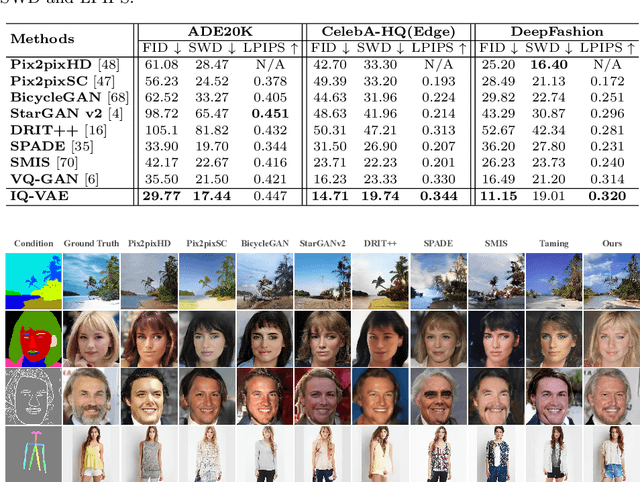
Mar 11, 2023Quantizing images into discrete representations has been a fundamental problem in unified generative modeling. Predominant approaches learn the discrete representation either in a deterministic manner by selecting the best-matching token or in a stochastic manner by sampling from a predicted distribution. However, deterministic quantization suffers from severe codebook collapse and misalignment with inference stage while stochastic quantization suffers from low codebook utilization and perturbed reconstruction objective. This paper presents a regularized vector quantization framework that allows to mitigate above issues effectively by applying regularization from two perspectives. The first is a prior distribution regularization which measures the discrepancy between a prior token distribution and the predicted token distribution to avoid codebook collapse and low codebook utilization. The second is a stochastic mask regularization that introduces stochasticity during quantization to strike a good balance between inference stage misalignment and unperturbed reconstruction objective. In addition, we design a probabilistic contrastive loss which serves as a calibrated metric to further mitigate the perturbed reconstruction objective. Extensive experiments show that the proposed quantization framework outperforms prevailing vector quantization methods consistently across different generative models including auto-regressive models and diffusion models.
Latent Multi-Relation Reasoning for GAN-Prior based Image Super-Resolution
Aug 04, 2022



Recently, single image super-resolution (SR) under large scaling factors has witnessed impressive progress by introducing pre-trained generative adversarial networks (GANs) as priors. However, most GAN-Priors based SR methods are constrained by an attribute disentanglement problem in inverted latent codes which directly leads to mismatches of visual attributes in the generator layers and further degraded reconstruction. In addition, stochastic noises fed to the generator are employed for unconditional detail generation, which tends to produce unfaithful details that compromise the fidelity of the generated SR image. We design LAREN, a LAtent multi-Relation rEasoNing technique that achieves superb large-factor SR through graph-based multi-relation reasoning in latent space. LAREN consists of two innovative designs. The first is graph-based disentanglement that constructs a superior disentangled latent space via hierarchical multi-relation reasoning. The second is graph-based code generation that produces image-specific codes progressively via recursive relation reasoning which enables prior GANs to generate desirable image details. Extensive experiments show that LAREN achieves superior large-factor image SR and outperforms the state-of-the-art consistently across multiple benchmarks.
RenderNet: Visual Relocalization Using Virtual Viewpoints in Large-Scale Indoor Environments
Jul 26, 2022
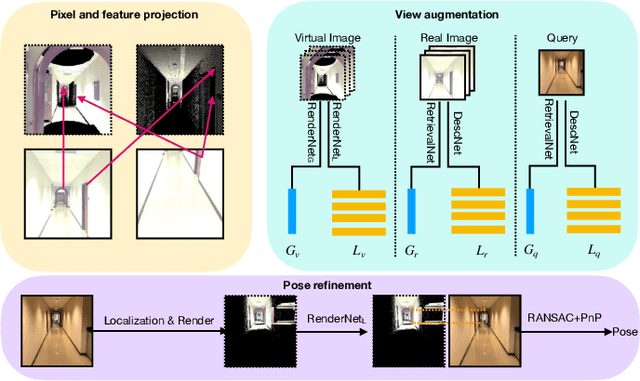
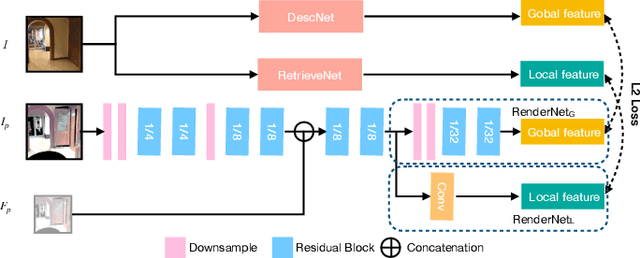

Visual relocalization has been a widely discussed problem in 3D vision: given a pre-constructed 3D visual map, the 6 DoF (Degrees-of-Freedom) pose of a query image is estimated. Relocalization in large-scale indoor environments enables attractive applications such as augmented reality and robot navigation. However, appearance changes fast in such environments when the camera moves, which is challenging for the relocalization system. To address this problem, we propose a virtual view synthesis-based approach, RenderNet, to enrich the database and refine poses regarding this particular scenario. Instead of rendering real images which requires high-quality 3D models, we opt to directly render the needed global and local features of virtual viewpoints and apply them in the subsequent image retrieval and feature matching operations respectively. The proposed method can largely improve the performance in large-scale indoor environments, e.g., achieving an improvement of 7.1\% and 12.2\% on the Inloc dataset.
Auto-regressive Image Synthesis with Integrated Quantization
Jul 21, 2022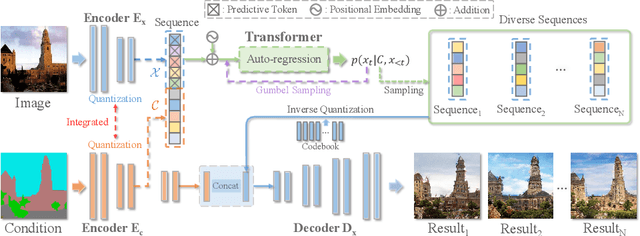
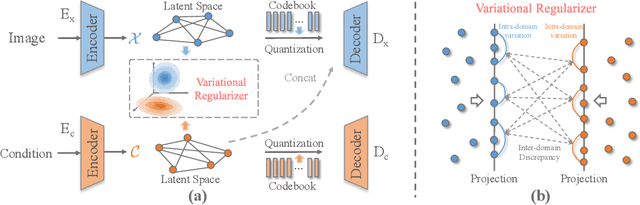
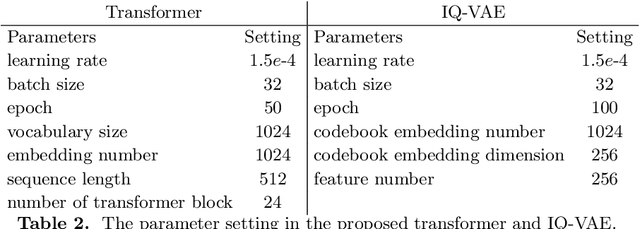
Deep generative models have achieved conspicuous progress in realistic image synthesis with multifarious conditional inputs, while generating diverse yet high-fidelity images remains a grand challenge in conditional image generation. This paper presents a versatile framework for conditional image generation which incorporates the inductive bias of CNNs and powerful sequence modeling of auto-regression that naturally leads to diverse image generation. Instead of independently quantizing the features of multiple domains as in prior research, we design an integrated quantization scheme with a variational regularizer that mingles the feature discretization in multiple domains, and markedly boosts the auto-regressive modeling performance. Notably, the variational regularizer enables to regularize feature distributions in incomparable latent spaces by penalizing the intra-domain variations of distributions. In addition, we design a Gumbel sampling strategy that allows to incorporate distribution uncertainty into the auto-regressive training procedure. The Gumbel sampling substantially mitigates the exposure bias that often incurs misalignment between the training and inference stages and severely impairs the inference performance. Extensive experiments over multiple conditional image generation tasks show that our method achieves superior diverse image generation performance qualitatively and quantitatively as compared with the state-of-the-art.
Towards Counterfactual Image Manipulation via CLIP
Jul 12, 2022
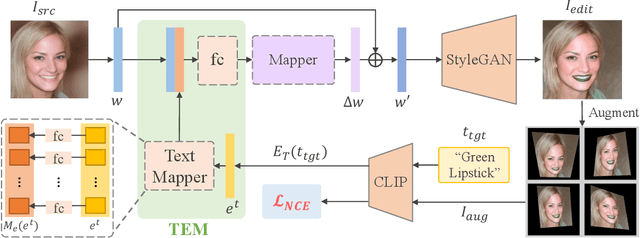
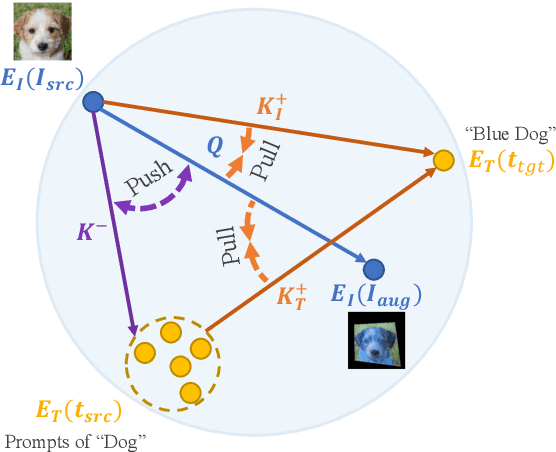

Leveraging StyleGAN's expressivity and its disentangled latent codes, existing methods can achieve realistic editing of different visual attributes such as age and gender of facial images. An intriguing yet challenging problem arises: Can generative models achieve counterfactual editing against their learnt priors? Due to the lack of counterfactual samples in natural datasets, we investigate this problem in a text-driven manner with Contrastive-Language-Image-Pretraining (CLIP), which can offer rich semantic knowledge even for various counterfactual concepts. Different from in-domain manipulation, counterfactual manipulation requires more comprehensive exploitation of semantic knowledge encapsulated in CLIP as well as more delicate handling of editing directions for avoiding being stuck in local minimum or undesired editing. To this end, we design a novel contrastive loss that exploits predefined CLIP-space directions to guide the editing toward desired directions from different perspectives. In addition, we design a simple yet effective scheme that explicitly maps CLIP embeddings (of target text) to the latent space and fuses them with latent codes for effective latent code optimization and accurate editing. Extensive experiments show that our design achieves accurate and realistic editing while driving by target texts with various counterfactual concepts.
VMRF: View Matching Neural Radiance Fields
Jul 06, 2022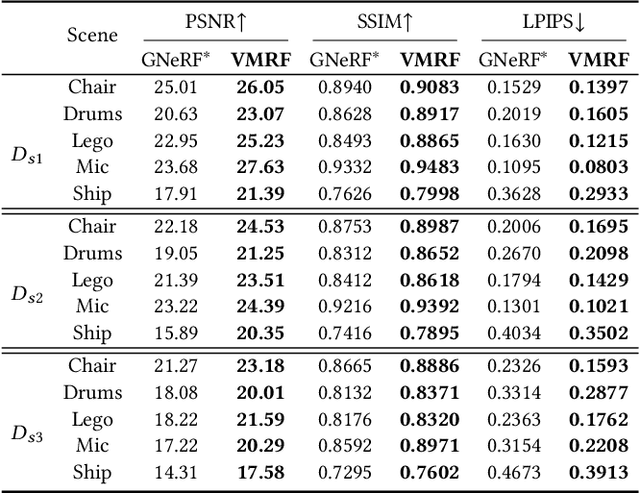
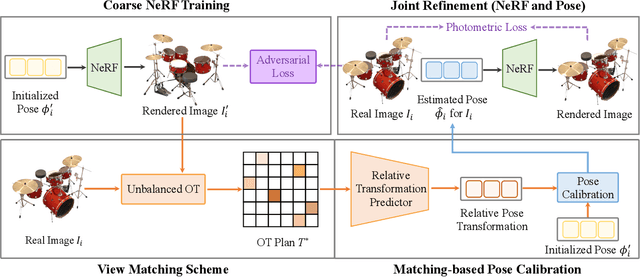
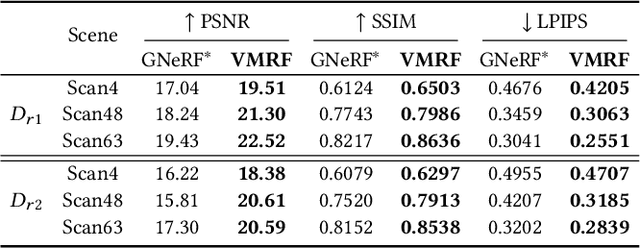
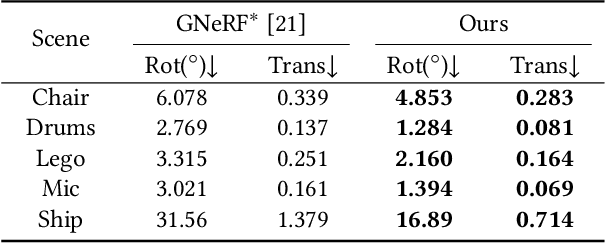
Neural Radiance Fields (NeRF) have demonstrated very impressive performance in novel view synthesis via implicitly modelling 3D representations from multi-view 2D images. However, most existing studies train NeRF models with either reasonable camera pose initialization or manually-crafted camera pose distributions which are often unavailable or hard to acquire in various real-world data. We design VMRF, an innovative view matching NeRF that enables effective NeRF training without requiring prior knowledge in camera poses or camera pose distributions. VMRF introduces a view matching scheme, which exploits unbalanced optimal transport to produce a feature transport plan for mapping a rendered image with randomly initialized camera pose to the corresponding real image. With the feature transport plan as the guidance, a novel pose calibration technique is designed which rectifies the initially randomized camera poses by predicting relative pose transformations between the pair of rendered and real images. Extensive experiments over a number of synthetic and real datasets show that the proposed VMRF outperforms the state-of-the-art qualitatively and quantitatively by large margins.
Marginal Contrastive Correspondence for Guided Image Generation
Apr 01, 2022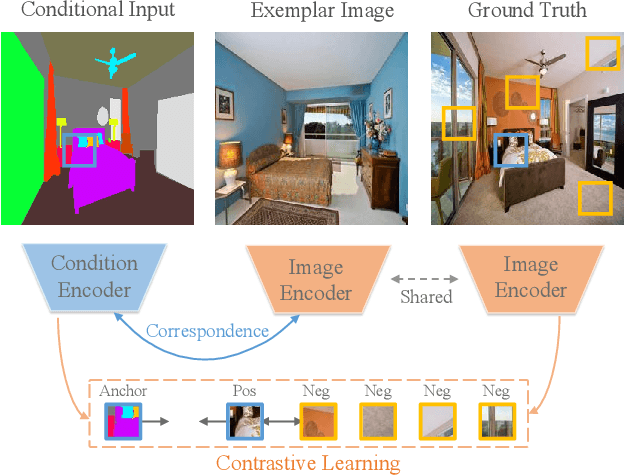
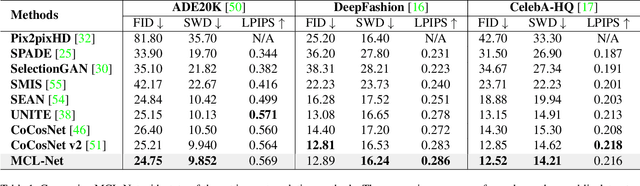
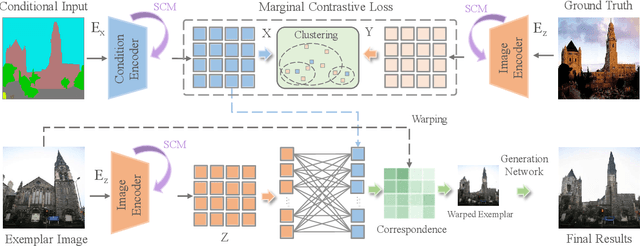
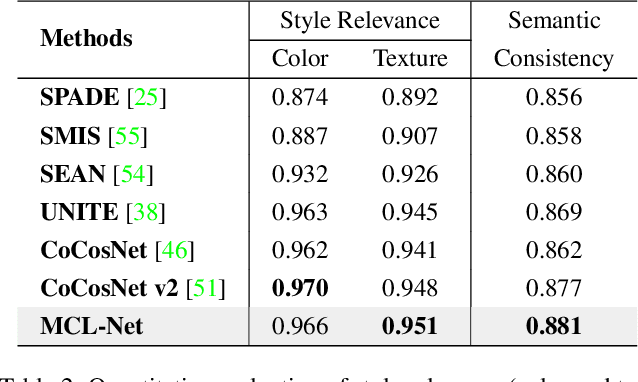
Exemplar-based image translation establishes dense correspondences between a conditional input and an exemplar (from two different domains) for leveraging detailed exemplar styles to achieve realistic image translation. Existing work builds the cross-domain correspondences implicitly by minimizing feature-wise distances across the two domains. Without explicit exploitation of domain-invariant features, this approach may not reduce the domain gap effectively which often leads to sub-optimal correspondences and image translation. We design a Marginal Contrastive Learning Network (MCL-Net) that explores contrastive learning to learn domain-invariant features for realistic exemplar-based image translation. Specifically, we design an innovative marginal contrastive loss that guides to establish dense correspondences explicitly. Nevertheless, building correspondence with domain-invariant semantics alone may impair the texture patterns and lead to degraded texture generation. We thus design a Self-Correlation Map (SCM) that incorporates scene structures as auxiliary information which improves the built correspondences substantially. Quantitative and qualitative experiments on multifarious image translation tasks show that the proposed method outperforms the state-of-the-art consistently.
Modulated Contrast for Versatile Image Synthesis
Mar 17, 2022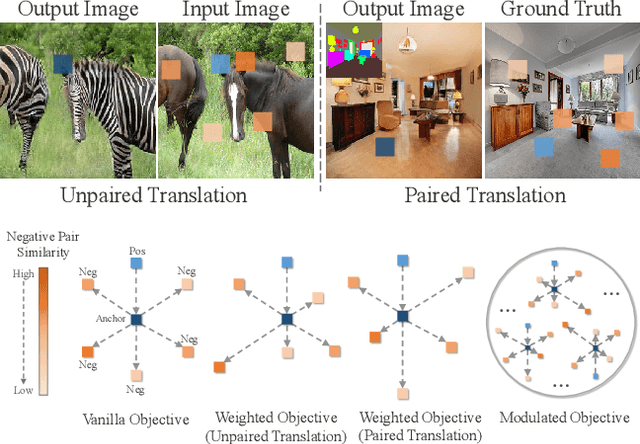
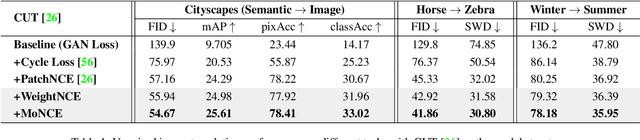

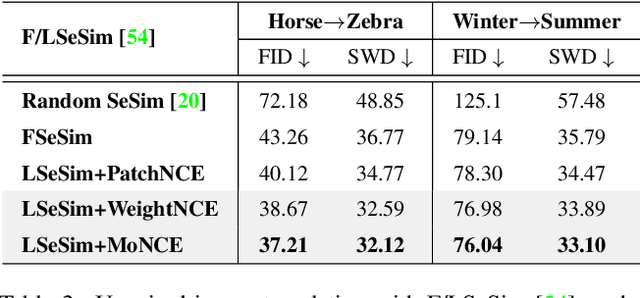
Perceiving the similarity between images has been a long-standing and fundamental problem underlying various visual generation tasks. Predominant approaches measure the inter-image distance by computing pointwise absolute deviations, which tends to estimate the median of instance distributions and leads to blurs and artifacts in the generated images. This paper presents MoNCE, a versatile metric that introduces image contrast to learn a calibrated metric for the perception of multifaceted inter-image distances. Unlike vanilla contrast which indiscriminately pushes negative samples from the anchor regardless of their similarity, we propose to re-weight the pushing force of negative samples adaptively according to their similarity to the anchor, which facilitates the contrastive learning from informative negative samples. Since multiple patch-level contrastive objectives are involved in image distance measurement, we introduce optimal transport in MoNCE to modulate the pushing force of negative samples collaboratively across multiple contrastive objectives. Extensive experiments over multiple image translation tasks show that the proposed MoNCE outperforms various prevailing metrics substantially. The code is available at https://github.com/fnzhan/MoNCE.