 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDuality-free Methods for Stochastic Composition Optimization
Oct 26, 2017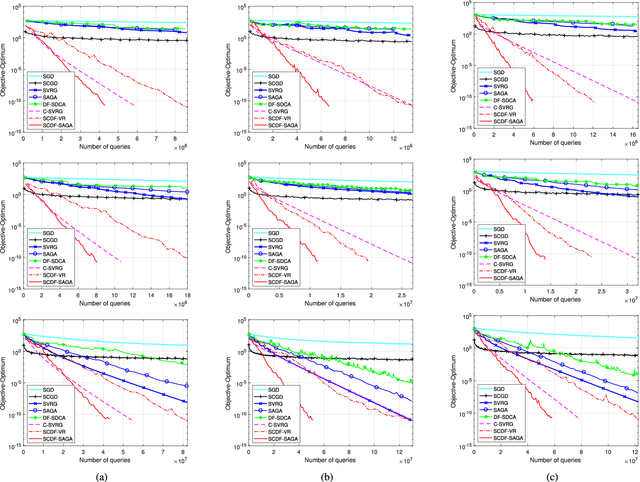
We consider the composition optimization with two expected-value functions in the form of $\frac{1}{n}\sum\nolimits_{i = 1}^n F_i(\frac{1}{m}\sum\nolimits_{j = 1}^m G_j(x))+R(x)$, { which formulates many important problems in statistical learning and machine learning such as solving Bellman equations in reinforcement learning and nonlinear embedding}. Full Gradient or classical stochastic gradient descent based optimization algorithms are unsuitable or computationally expensive to solve this problem due to the inner expectation $\frac{1}{m}\sum\nolimits_{j = 1}^m G_j(x)$. We propose a duality-free based stochastic composition method that combines variance reduction methods to address the stochastic composition problem. We apply SVRG and SAGA based methods to estimate the inner function, and duality-free method to estimate the outer function. We prove the linear convergence rate not only for the convex composition problem, but also for the case that the individual outer functions are non-convex while the objective function is strongly-convex. We also provide the results of experiments that show the effectiveness of our proposed methods.
Infinite-Label Learning with Semantic Output Codes
Oct 21, 2017
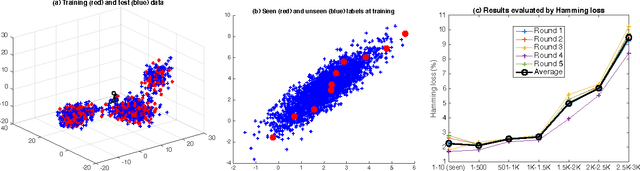
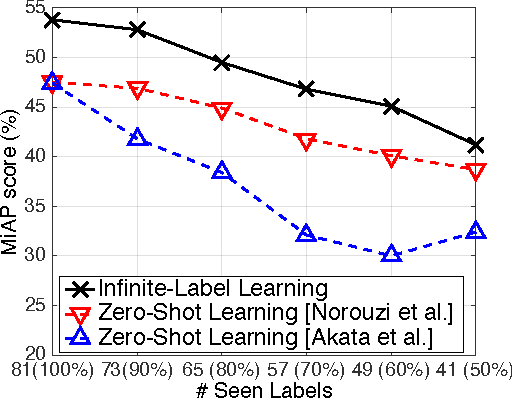
We develop a new statistical machine learning paradigm, named infinite-label learning, to annotate a data point with more than one relevant labels from a candidate set, which pools both the finite labels observed at training and a potentially infinite number of previously unseen labels. The infinite-label learning fundamentally expands the scope of conventional multi-label learning, and better models the practical requirements in various real-world applications, such as image tagging, ads-query association, and article categorization. However, how can we learn a labeling function that is capable of assigning to a data point the labels omitted from the training set? To answer the question, we seek some clues from the recent work on zero-shot learning, where the key is to represent a class/label by a vector of semantic codes, as opposed to treating them as atomic labels. We validate the infinite-label learning by a PAC bound in theory and some empirical studies on both synthetic and real data.
GaDei: On Scale-up Training As A Service For Deep Learning
Oct 03, 2017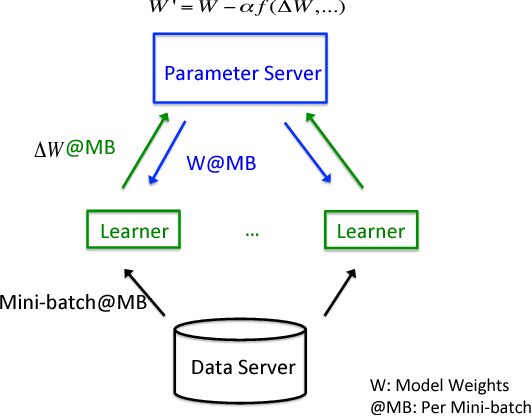
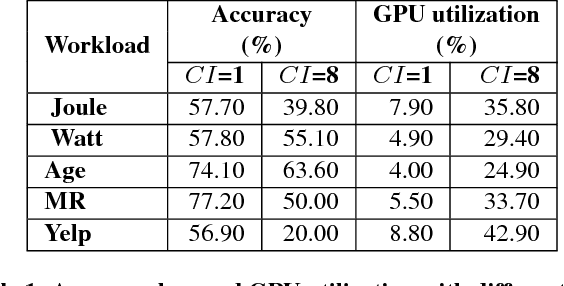
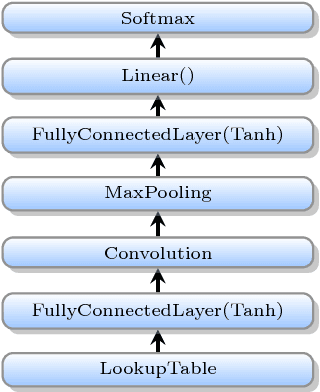
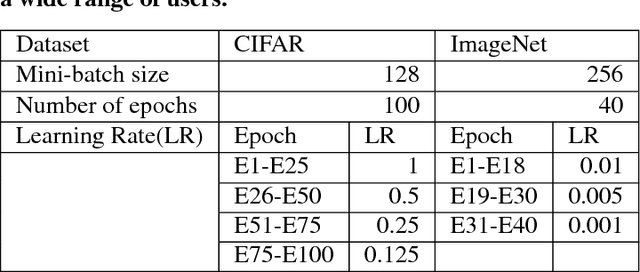
Deep learning (DL) training-as-a-service (TaaS) is an important emerging industrial workload. The unique challenge of TaaS is that it must satisfy a wide range of customers who have no experience and resources to tune DL hyper-parameters, and meticulous tuning for each user's dataset is prohibitively expensive. Therefore, TaaS hyper-parameters must be fixed with values that are applicable to all users. IBM Watson Natural Language Classifier (NLC) service, the most popular IBM cognitive service used by thousands of enterprise-level clients around the globe, is a typical TaaS service. By evaluating the NLC workloads, we show that only the conservative hyper-parameter setup (e.g., small mini-batch size and small learning rate) can guarantee acceptable model accuracy for a wide range of customers. We further justify theoretically why such a setup guarantees better model convergence in general. Unfortunately, the small mini-batch size causes a high volume of communication traffic in a parameter-server based system. We characterize the high communication bandwidth requirement of TaaS using representative industrial deep learning workloads and demonstrate that none of the state-of-the-art scale-up or scale-out solutions can satisfy such a requirement. We then present GaDei, an optimized shared-memory based scale-up parameter server design. We prove that the designed protocol is deadlock-free and it processes each gradient exactly once. Our implementation is evaluated on both commercial benchmarks and public benchmarks to demonstrate that it significantly outperforms the state-of-the-art parameter-server based implementation while maintaining the required accuracy and our implementation reaches near the best possible runtime performance, constrained only by the hardware limitation. Furthermore, to the best of our knowledge, GaDei is the only scale-up DL system that provides fault-tolerance.
Can Decentralized Algorithms Outperform Centralized Algorithms? A Case Study for Decentralized Parallel Stochastic Gradient Descent
Sep 11, 2017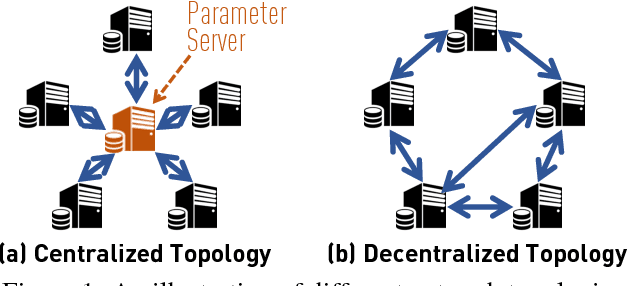
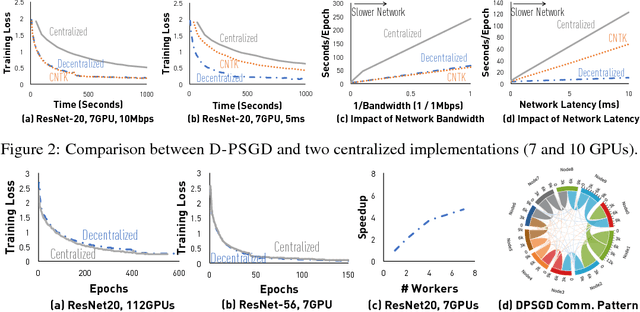
Most distributed machine learning systems nowadays, including TensorFlow and CNTK, are built in a centralized fashion. One bottleneck of centralized algorithms lies on high communication cost on the central node. Motivated by this, we ask, can decentralized algorithms be faster than its centralized counterpart? Although decentralized PSGD (D-PSGD) algorithms have been studied by the control community, existing analysis and theory do not show any advantage over centralized PSGD (C-PSGD) algorithms, simply assuming the application scenario where only the decentralized network is available. In this paper, we study a D-PSGD algorithm and provide the first theoretical analysis that indicates a regime in which decentralized algorithms might outperform centralized algorithms for distributed stochastic gradient descent. This is because D-PSGD has comparable total computational complexities to C-PSGD but requires much less communication cost on the busiest node. We further conduct an empirical study to validate our theoretical analysis across multiple frameworks (CNTK and Torch), different network configurations, and computation platforms up to 112 GPUs. On network configurations with low bandwidth or high latency, D-PSGD can be up to one order of magnitude faster than its well-optimized centralized counterparts.
Ease.ml: Towards Multi-tenant Resource Sharing for Machine Learning Workloads
Aug 24, 2017
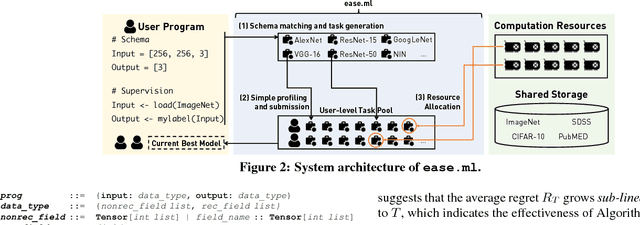
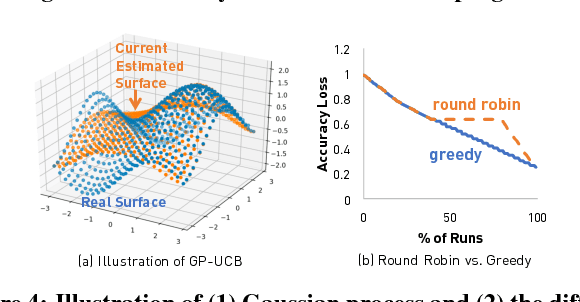
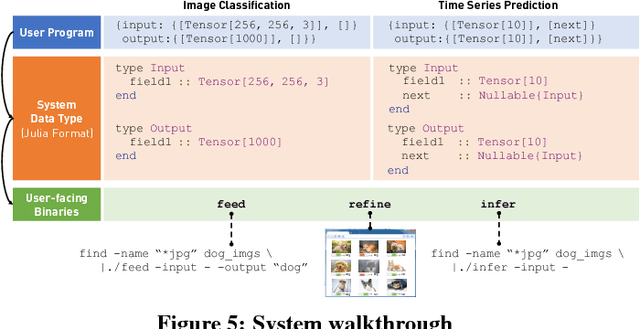
We present ease.ml, a declarative machine learning service platform we built to support more than ten research groups outside the computer science departments at ETH Zurich for their machine learning needs. With ease.ml, a user defines the high-level schema of a machine learning application and submits the task via a Web interface. The system automatically deals with the rest, such as model selection and data movement. In this paper, we describe the ease.ml architecture and focus on a novel technical problem introduced by ease.ml regarding resource allocation. We ask, as a "service provider" that manages a shared cluster of machines among all our users running machine learning workloads, what is the resource allocation strategy that maximizes the global satisfaction of all our users? Resource allocation is a critical yet subtle issue in this multi-tenant scenario, as we have to balance between efficiency and fairness. We first formalize the problem that we call multi-tenant model selection, aiming for minimizing the total regret of all users running automatic model selection tasks. We then develop a novel algorithm that combines multi-armed bandits with Bayesian optimization and prove a regret bound under the multi-tenant setting. Finally, we report our evaluation of ease.ml on synthetic data and on one service we are providing to our users, namely, image classification with deep neural networks. Our experimental evaluation results show that our proposed solution can be up to 9.8x faster in achieving the same global quality for all users as the two popular heuristics used by our users before ease.ml.
The ZipML Framework for Training Models with End-to-End Low Precision: The Cans, the Cannots, and a Little Bit of Deep Learning
Jun 19, 2017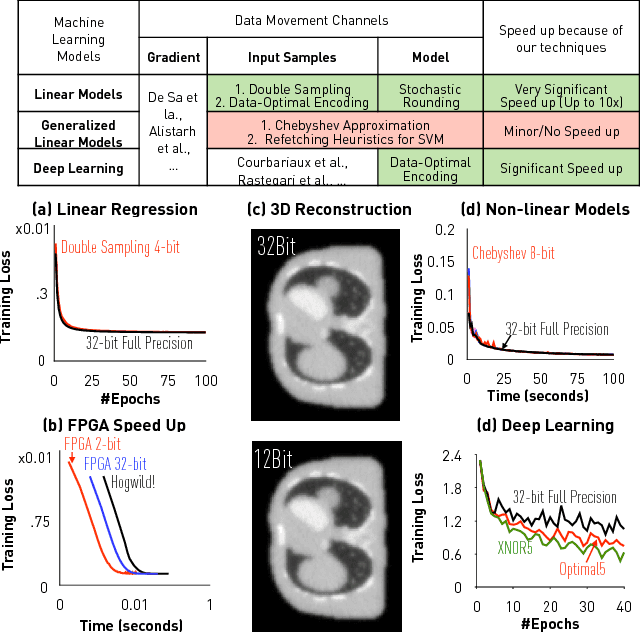
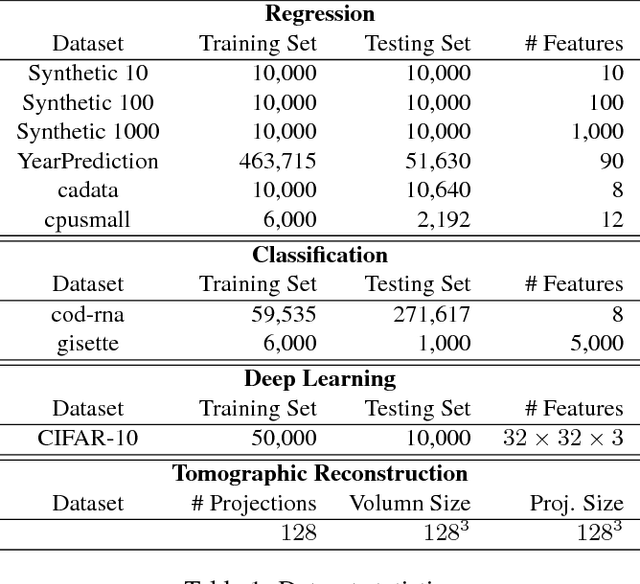
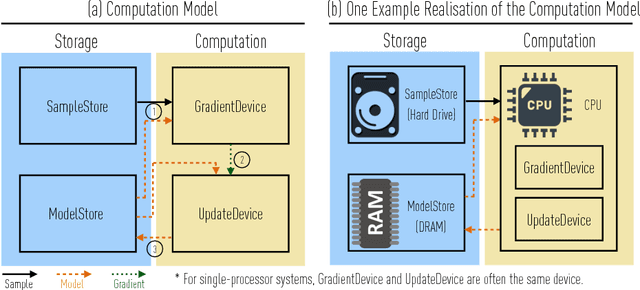
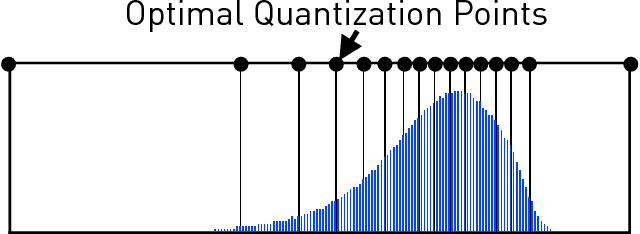
Recently there has been significant interest in training machine-learning models at low precision: by reducing precision, one can reduce computation and communication by one order of magnitude. We examine training at reduced precision, both from a theoretical and practical perspective, and ask: is it possible to train models at end-to-end low precision with provable guarantees? Can this lead to consistent order-of-magnitude speedups? We present a framework called ZipML to answer these questions. For linear models, the answer is yes. We develop a simple framework based on one simple but novel strategy called double sampling. Our framework is able to execute training at low precision with no bias, guaranteeing convergence, whereas naive quantization would introduce significant bias. We validate our framework across a range of applications, and show that it enables an FPGA prototype that is up to 6.5x faster than an implementation using full 32-bit precision. We further develop a variance-optimal stochastic quantization strategy and show that it can make a significant difference in a variety of settings. When applied to linear models together with double sampling, we save up to another 1.7x in data movement compared with uniform quantization. When training deep networks with quantized models, we achieve higher accuracy than the state-of-the-art XNOR-Net. Finally, we extend our framework through approximation to non-linear models, such as SVM. We show that, although using low-precision data induces bias, we can appropriately bound and control the bias. We find in practice 8-bit precision is often sufficient to converge to the correct solution. Interestingly, however, in practice we notice that our framework does not always outperform the naive rounding approach. We discuss this negative result in detail.
On The Projection Operator to A Three-view Cardinality Constrained Set
Jun 14, 2017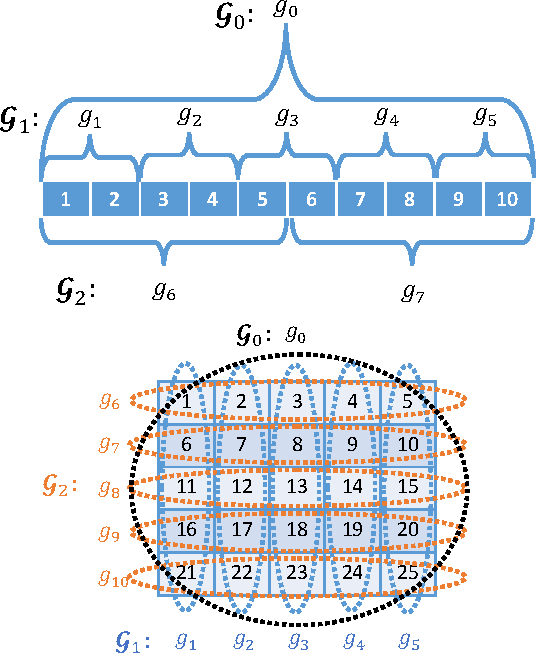

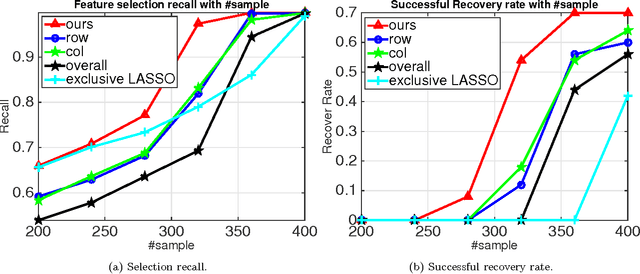
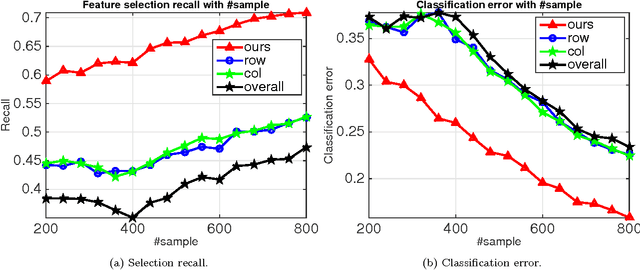
The cardinality constraint is an intrinsic way to restrict the solution structure in many domains, for example, sparse learning, feature selection, and compressed sensing. To solve a cardinality constrained problem, the key challenge is to solve the projection onto the cardinality constraint set, which is NP-hard in general when there exist multiple overlapped cardinality constraints. In this paper, we consider the scenario where the overlapped cardinality constraints satisfy a Three-view Cardinality Structure (TVCS), which reflects the natural restriction in many applications, such as identification of gene regulatory networks and task-worker assignment problem. We cast the projection into a linear programming, and show that for TVCS, the vertex solution of this linear programming is the solution for the original projection problem. We further prove that such solution can be found with the complexity proportional to the number of variables and constraints. We finally use synthetic experiments and two interesting applications in bioinformatics and crowdsourcing to validate the proposed TVCS model and method.
Lifelong Metric Learning
Jun 12, 2017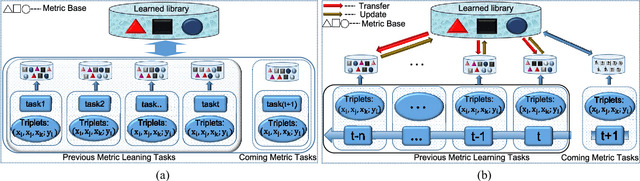
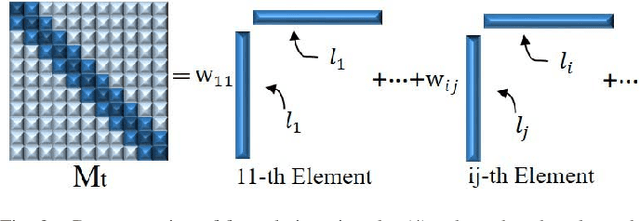
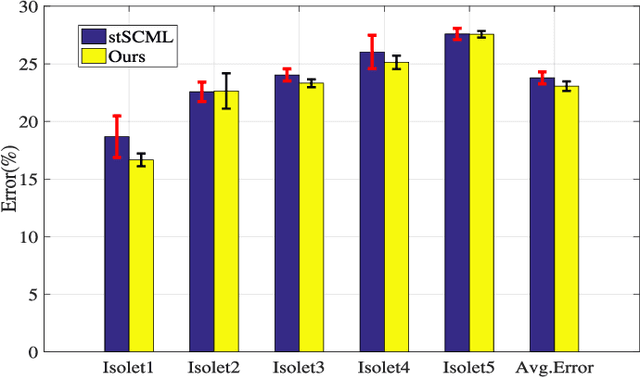
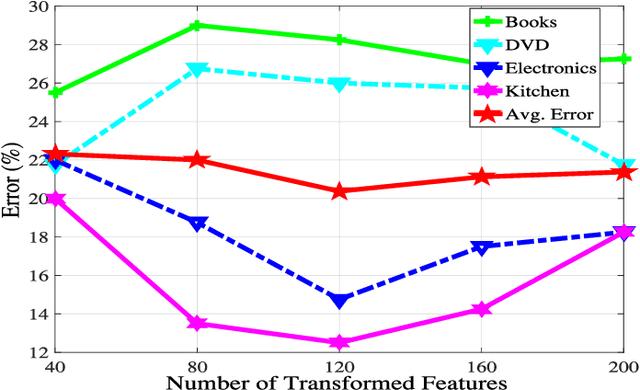
The state-of-the-art online learning approaches are only capable of learning the metric for predefined tasks. In this paper, we consider lifelong learning problem to mimic "human learning", i.e., endowing a new capability to the learned metric for a new task from new online samples and incorporating previous experiences and knowledge. Therefore, we propose a new metric learning framework: lifelong metric learning (LML), which only utilizes the data of the new task to train the metric model while preserving the original capabilities. More specifically, the proposed LML maintains a common subspace for all learned metrics, named lifelong dictionary, transfers knowledge from the common subspace to each new metric task with task-specific idiosyncrasy, and redefines the common subspace over time to maximize performance across all metric tasks. For model optimization, we apply online passive aggressive optimization algorithm to solve the proposed LML framework, where the lifelong dictionary and task-specific partition are optimized alternatively and consecutively. Finally, we evaluate our approach by analyzing several multi-task metric learning datasets. Extensive experimental results demonstrate effectiveness and efficiency of the proposed framework.
Asynchronous Parallel Stochastic Gradient for Nonconvex Optimization
Jun 10, 2017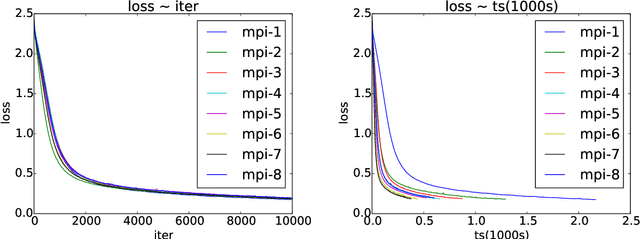

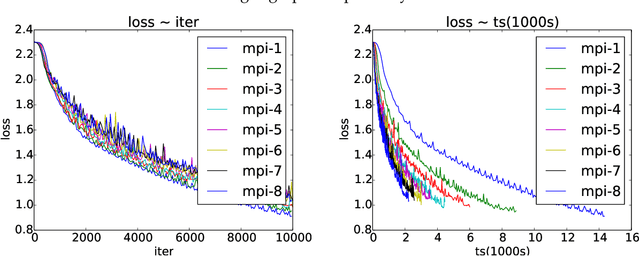

Asynchronous parallel implementations of stochastic gradient (SG) have been broadly used in solving deep neural network and received many successes in practice recently. However, existing theories cannot explain their convergence and speedup properties, mainly due to the nonconvexity of most deep learning formulations and the asynchronous parallel mechanism. To fill the gaps in theory and provide theoretical supports, this paper studies two asynchronous parallel implementations of SG: one is on the computer network and the other is on the shared memory system. We establish an ergodic convergence rate $O(1/\sqrt{K})$ for both algorithms and prove that the linear speedup is achievable if the number of workers is bounded by $\sqrt{K}$ ($K$ is the total number of iterations). Our results generalize and improve existing analysis for convex minimization.
Negative-Unlabeled Tensor Factorization for Location Category Inference from Highly Inaccurate Mobility Data
May 24, 2017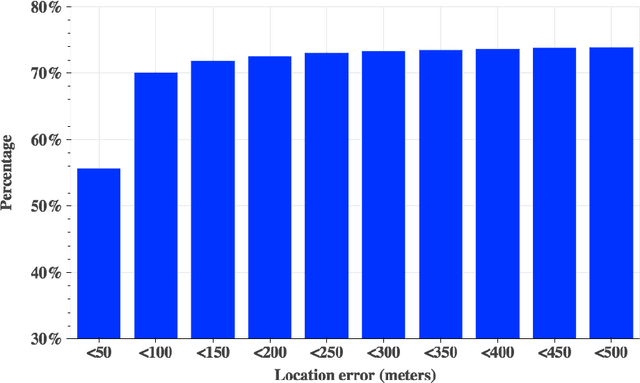
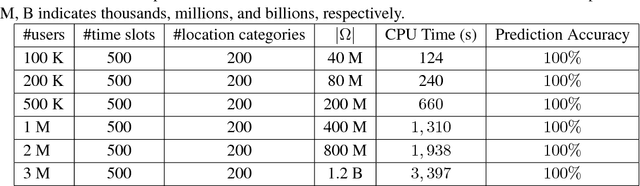
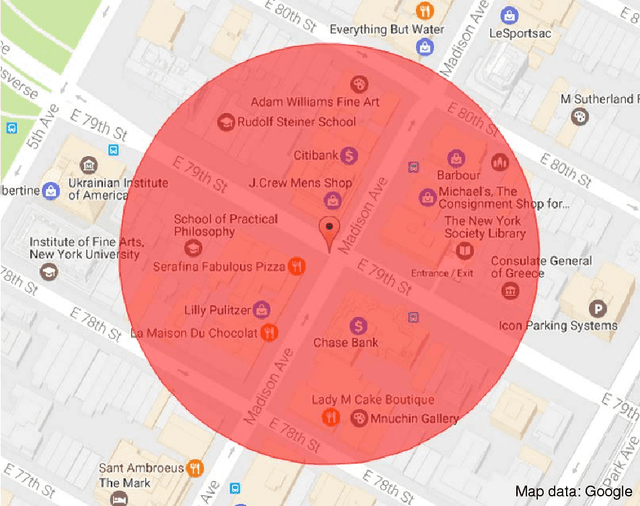
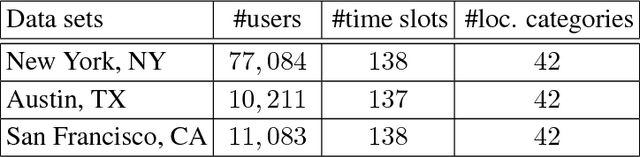
Identifying significant location categories visited by mobile users is the key to a variety of applications. This is an extremely challenging task due to the possible deviation between the estimated location coordinate and the actual location, which could be on the order of kilometers. To estimate the actual location category more precisely, we propose a novel tensor factorization framework, through several key observations including the intrinsic correlations between users, to infer the most likely location categories within the location uncertainty circle. In addition, the proposed algorithm can also predict where users are even in the absence of location information. In order to efficiently solve the proposed framework, we propose a parameter-free and scalable optimization algorithm by effectively exploring the sparse and low-rank structure of the tensor. Our empirical studies show that the proposed algorithm is both efficient and effective: it can solve problems with millions of users and billions of location updates, and also provides superior prediction accuracies on real-world location updates and check-in data sets.