 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous-Time Fitted Value Iteration for Robust Policies
Oct 05, 2021
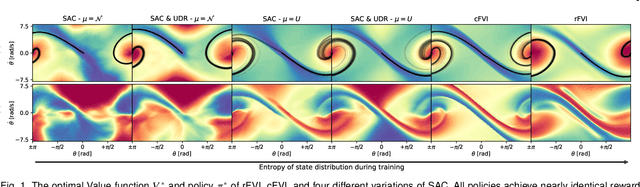


Solving the Hamilton-Jacobi-Bellman equation is important in many domains including control, robotics and economics. Especially for continuous control, solving this differential equation and its extension the Hamilton-Jacobi-Isaacs equation, is important as it yields the optimal policy that achieves the maximum reward on a give task. In the case of the Hamilton-Jacobi-Isaacs equation, which includes an adversary controlling the environment and minimizing the reward, the obtained policy is also robust to perturbations of the dynamics. In this paper we propose continuous fitted value iteration (cFVI) and robust fitted value iteration (rFVI). These algorithms leverage the non-linear control-affine dynamics and separable state and action reward of many continuous control problems to derive the optimal policy and optimal adversary in closed form. This analytic expression simplifies the differential equations and enables us to solve for the optimal value function using value iteration for continuous actions and states as well as the adversarial case. Notably, the resulting algorithms do not require discretization of states or actions. We apply the resulting algorithms to the Furuta pendulum and cartpole. We show that both algorithms obtain the optimal policy. The robustness Sim2Real experiments on the physical systems show that the policies successfully achieve the task in the real-world. When changing the masses of the pendulum, we observe that robust value iteration is more robust compared to deep reinforcement learning algorithm and the non-robust version of the algorithm. Videos of the experiments are shown at https://sites.google.com/view/rfvi
Combining Physics and Deep Learning to learn Continuous-Time Dynamics Models
Oct 05, 2021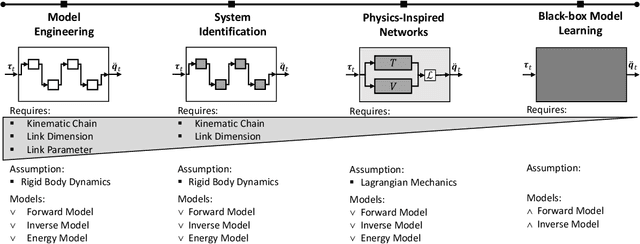


Deep learning has been widely used within learning algorithms for robotics. One disadvantage of deep networks is that these networks are black-box representations. Therefore, the learned approximations ignore the existing knowledge of physics or robotics. Especially for learning dynamics models, these black-box models are not desirable as the underlying principles are well understood and the standard deep networks can learn dynamics that violate these principles. To learn dynamics models with deep networks that guarantee physically plausible dynamics, we introduce physics-inspired deep networks that combine first principles from physics with deep learning. We incorporate Lagrangian mechanics within the model learning such that all approximated models adhere to the laws of physics and conserve energy. Deep Lagrangian Networks (DeLaN) parametrize the system energy using two networks. The parameters are obtained by minimizing the squared residual of the Euler-Lagrange differential equation. Therefore, the resulting model does not require specific knowledge of the individual system, is interpretable, and can be used as a forward, inverse, and energy model. Previously these properties were only obtained when using system identification techniques that require knowledge of the kinematic structure. We apply DeLaN to learning dynamics models and apply these models to control simulated and physical rigid body systems. The results show that the proposed approach obtains dynamics models that can be applied to physical systems for real-time control. Compared to standard deep networks, the physics-inspired models learn better models and capture the underlying structure of the dynamics.
A Robot Cluster for Reproducible Research in Dexterous Manipulation
Sep 22, 2021

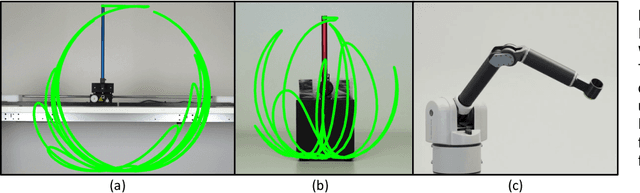
Dexterous manipulation remains an open problem in robotics. To coordinate efforts of the research community towards tackling this problem, we propose a shared benchmark. We designed and built robotic platforms that are hosted at the MPI-IS and can be accessed remotely. Each platform consists of three robotic fingers that are capable of dexterous object manipulation. Users are able to control the platforms remotely by submitting code that is executed automatically, akin to a computational cluster. Using this setup, i) we host robotics competitions, where teams from anywhere in the world access our platforms to tackle challenging tasks, ii) we publish the datasets collected during these competitions (consisting of hundreds of robot hours), and iii) we give researchers access to these platforms for their own projects.
An Empirical Analysis of Measure-Valued Derivatives for Policy Gradients
Jul 20, 2021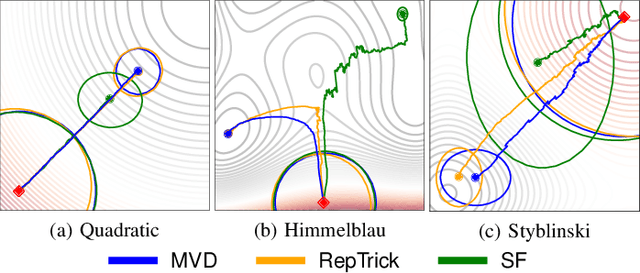
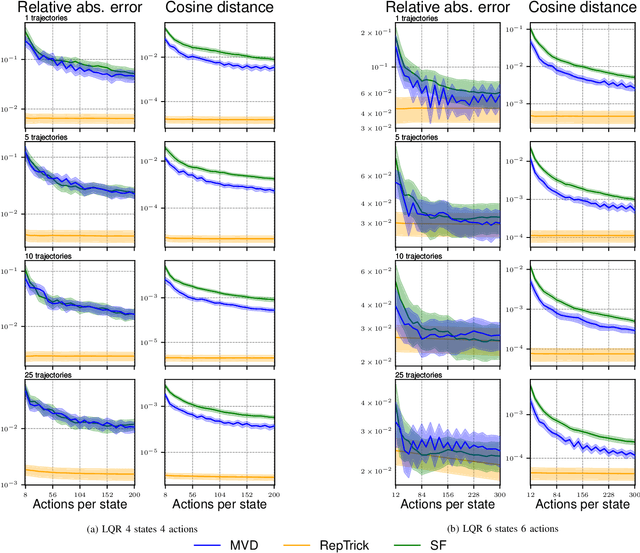
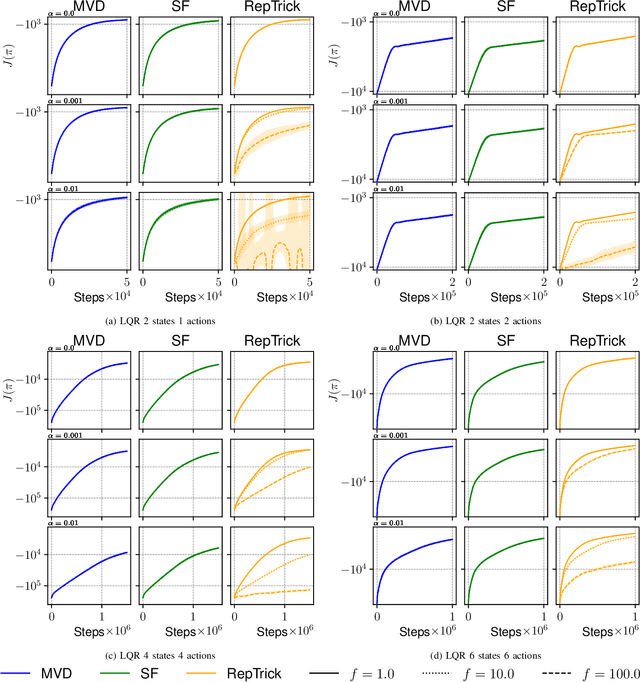
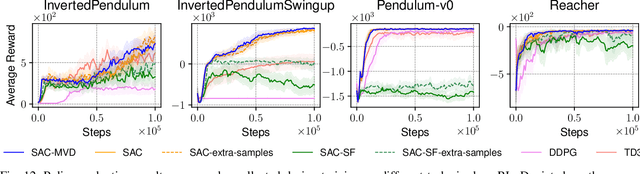
Reinforcement learning methods for robotics are increasingly successful due to the constant development of better policy gradient techniques. A precise (low variance) and accurate (low bias) gradient estimator is crucial to face increasingly complex tasks. Traditional policy gradient algorithms use the likelihood-ratio trick, which is known to produce unbiased but high variance estimates. More modern approaches exploit the reparametrization trick, which gives lower variance gradient estimates but requires differentiable value function approximators. In this work, we study a different type of stochastic gradient estimator: the Measure-Valued Derivative. This estimator is unbiased, has low variance, and can be used with differentiable and non-differentiable function approximators. We empirically evaluate this estimator in the actor-critic policy gradient setting and show that it can reach comparable performance with methods based on the likelihood-ratio or reparametrization tricks, both in low and high-dimensional action spaces.
Efficient and Reactive Planning for High Speed Robot Air Hockey
Jul 14, 2021
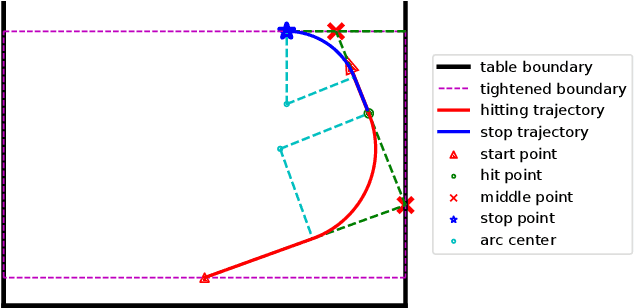
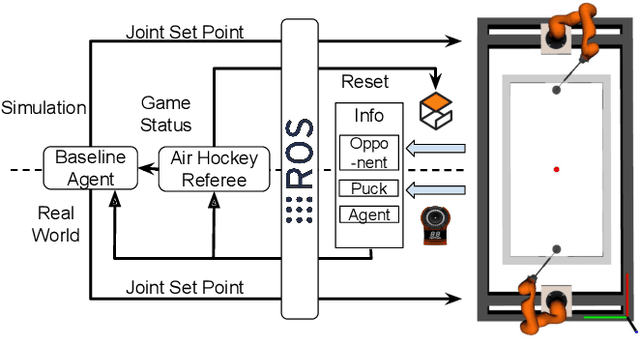

Highly dynamic robotic tasks require high-speed and reactive robots. These tasks are particularly challenging due to the physical constraints, hardware limitations, and the high uncertainty of dynamics and sensor measures. To face these issues, it's crucial to design robotics agents that generate precise and fast trajectories and react immediately to environmental changes. Air hockey is an example of this kind of task. Due to the environment's characteristics, it is possible to formalize the problem and derive clean mathematical solutions. For these reasons, this environment is perfect for pushing to the limit the performance of currently available general-purpose robotic manipulators. Using two Kuka Iiwa 14, we show how to design a policy for general-purpose robotic manipulators for the air hockey game. We demonstrate that a real robot arm can perform fast-hitting movements and that the two robots can play against each other on a medium-size air hockey table in simulation.
High-Dimensional Bayesian Optimisation with Variational Autoencoders and Deep Metric Learning
Jun 16, 2021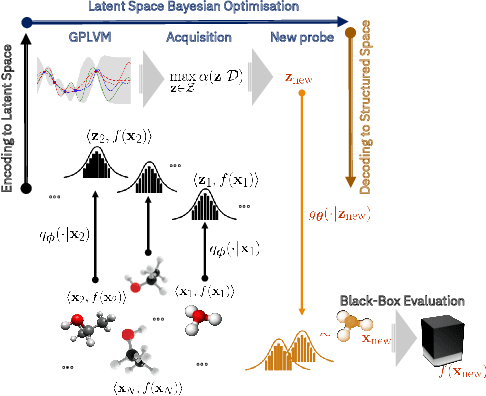

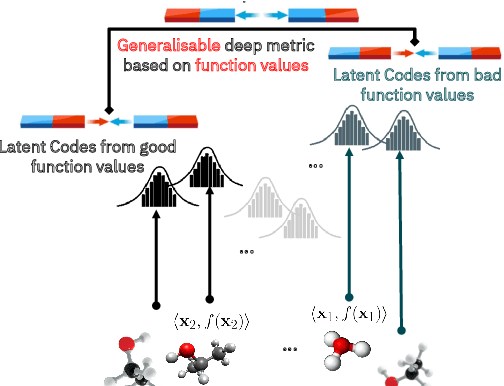

We introduce a method based on deep metric learning to perform Bayesian optimisation over high-dimensional, structured input spaces using variational autoencoders (VAEs). By extending ideas from supervised deep metric learning, we address a longstanding problem in high-dimensional VAE Bayesian optimisation, namely how to enforce a discriminative latent space as an inductive bias. Importantly, we achieve such an inductive bias using just 1% of the available labelled data relative to previous work, highlighting the sample efficiency of our approach. As a theoretical contribution, we present a proof of vanishing regret for our method. As an empirical contribution, we present state-of-the-art results on real-world high-dimensional black-box optimisation problems including property-guided molecule generation. It is the hope that the results presented in this paper can act as a guiding principle for realising effective high-dimensional Bayesian optimisation.
Robust Value Iteration for Continuous Control Tasks
May 25, 2021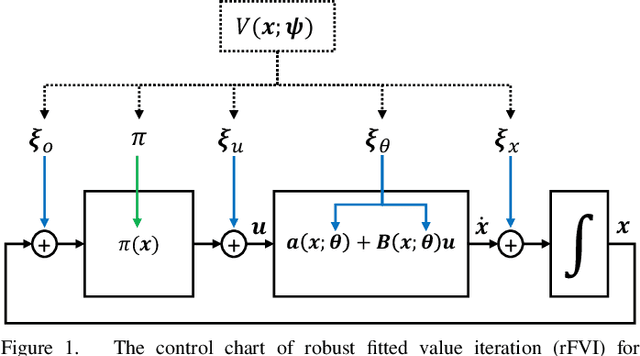
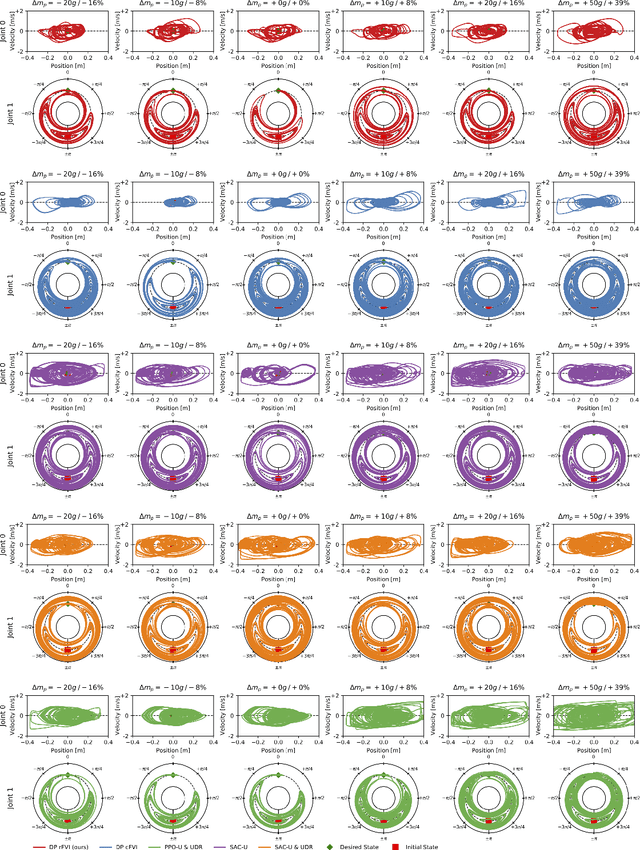
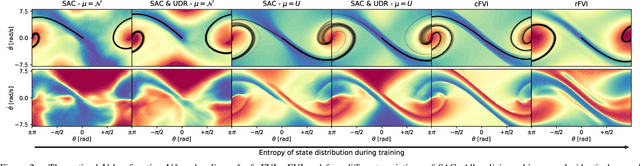

When transferring a control policy from simulation to a physical system, the policy needs to be robust to variations in the dynamics to perform well. Commonly, the optimal policy overfits to the approximate model and the corresponding state-distribution, often resulting in failure to trasnfer underlying distributional shifts. In this paper, we present Robust Fitted Value Iteration, which uses dynamic programming to compute the optimal value function on the compact state domain and incorporates adversarial perturbations of the system dynamics. The adversarial perturbations encourage a optimal policy that is robust to changes in the dynamics. Utilizing the continuous-time perspective of reinforcement learning, we derive the optimal perturbations for the states, actions, observations and model parameters in closed-form. Notably, the resulting algorithm does not require discretization of states or actions. Therefore, the optimal adversarial perturbations can be efficiently incorporated in the min-max value function update. We apply the resulting algorithm to the physical Furuta pendulum and cartpole. By changing the masses of the systems we evaluate the quantitative and qualitative performance across different model parameters. We show that robust value iteration is more robust compared to deep reinforcement learning algorithm and the non-robust version of the algorithm. Videos of the experiments are shown at https://sites.google.com/view/rfvi
Evolutionary Training and Abstraction Yields Algorithmic Generalization of Neural Computers
May 17, 2021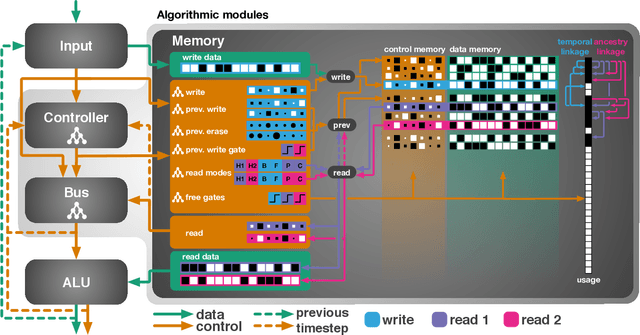
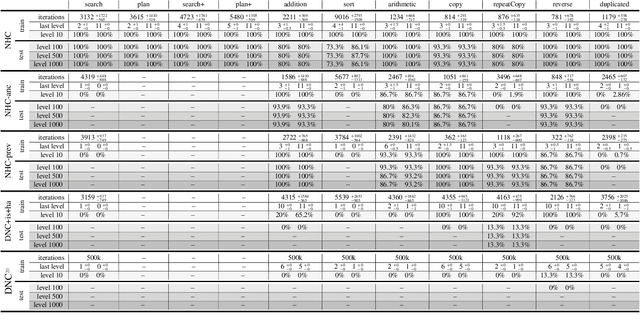
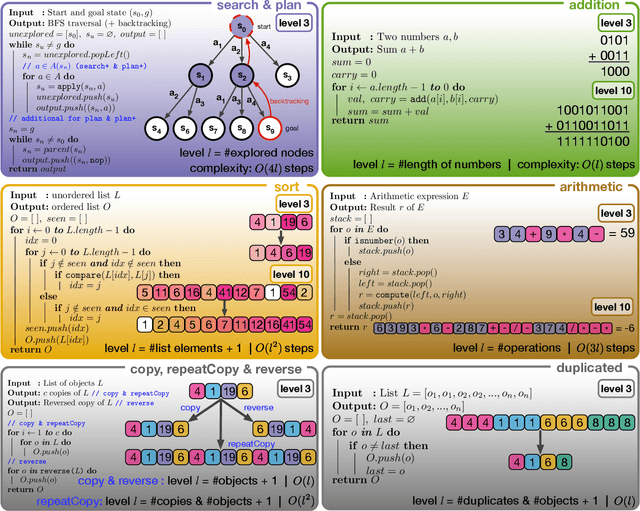
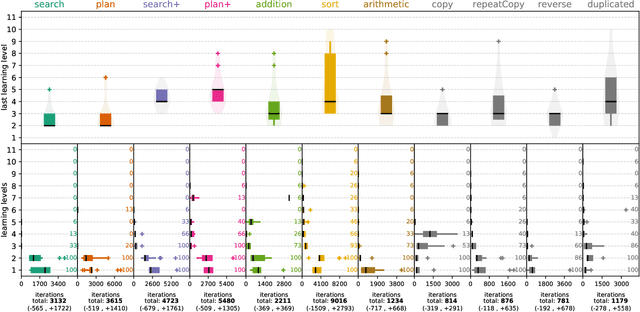
A key feature of intelligent behaviour is the ability to learn abstract strategies that scale and transfer to unfamiliar problems. An abstract strategy solves every sample from a problem class, no matter its representation or complexity -- like algorithms in computer science. Neural networks are powerful models for processing sensory data, discovering hidden patterns, and learning complex functions, but they struggle to learn such iterative, sequential or hierarchical algorithmic strategies. Extending neural networks with external memories has increased their capacities in learning such strategies, but they are still prone to data variations, struggle to learn scalable and transferable solutions, and require massive training data. We present the Neural Harvard Computer (NHC), a memory-augmented network based architecture, that employs abstraction by decoupling algorithmic operations from data manipulations, realized by splitting the information flow and separated modules. This abstraction mechanism and evolutionary training enable the learning of robust and scalable algorithmic solutions. On a diverse set of 11 algorithms with varying complexities, we show that the NHC reliably learns algorithmic solutions with strong generalization and abstraction: perfect generalization and scaling to arbitrary task configurations and complexities far beyond seen during training, and being independent of the data representation and the task domain.
* Nature Machine Intelligence
Stochastic Control through Approximate Bayesian Input Inference
May 17, 2021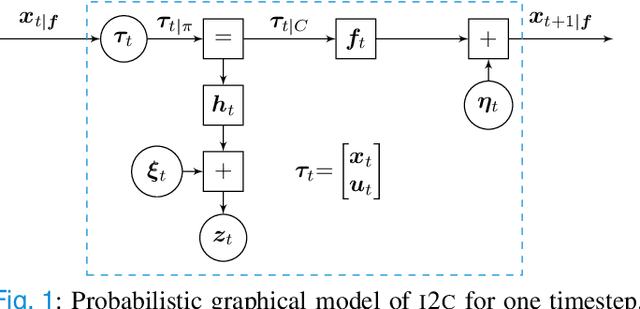
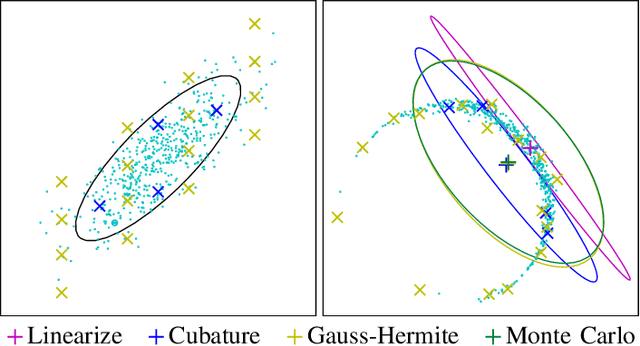
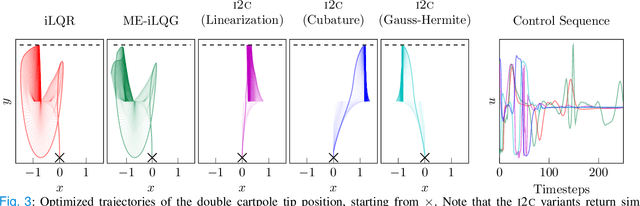
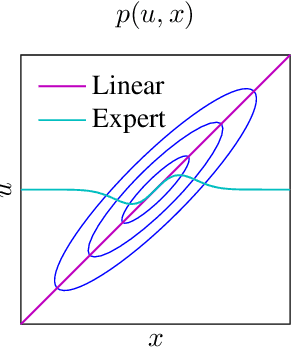
Optimal control under uncertainty is a prevailing challenge in control, due to the difficulty in producing tractable solutions for the stochastic optimization problem. By framing the control problem as one of input estimation, advanced approximate inference techniques can be used to handle the statistical approximations in a principled and practical manner. Analyzing the Gaussian setting, we present a solver capable of several stochastic control methods, and was found to be superior to popular baselines on nonlinear simulated tasks. We draw connections that relate this inference formulation to previous approaches for stochastic optimal control, and outline several advantages that this inference view brings due to its statistical nature.
Composable Energy Policies for Reactive Motion Generation and Reinforcement Learning
May 11, 2021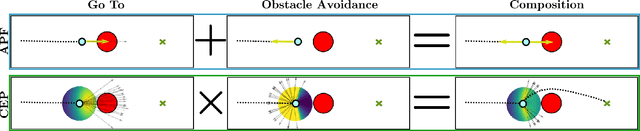
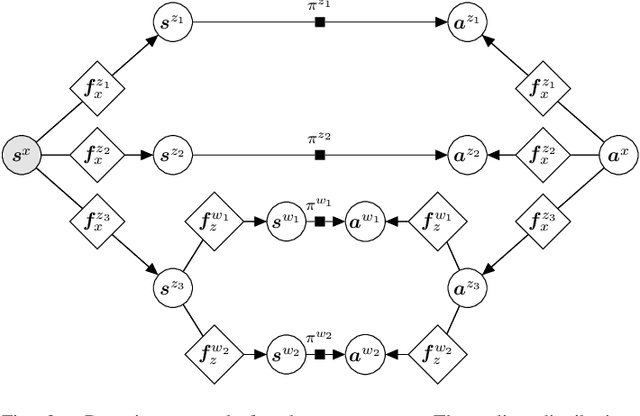
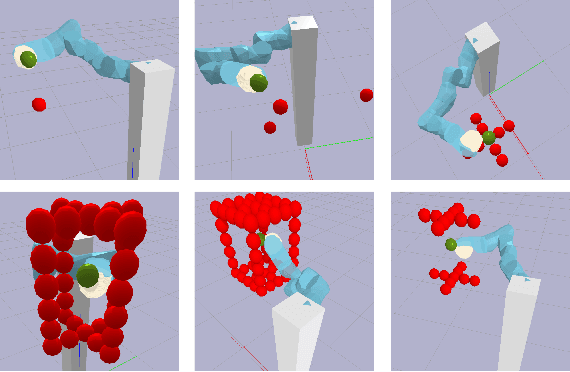
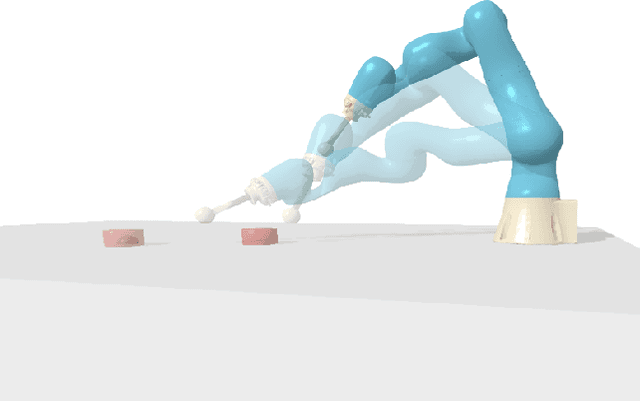
Reactive motion generation problems are usually solved by computing actions as a sum of policies. However, these policies are independent of each other and thus, they can have conflicting behaviors when summing their contributions together. We introduce Composable Energy Policies (CEP), a novel framework for modular reactive motion generation. CEP computes the control action by optimization over the product of a set of stochastic policies. This product of policies will provide a high probability to those actions that satisfy all the components and low probability to the others. Optimizing over the product of the policies avoids the detrimental effect of conflicting behaviors between policies choosing an action that satisfies all the objectives. Besides, we show that CEP naturally adapts to the Reinforcement Learning problem allowing us to integrate, in a hierarchical fashion, any distribution as prior, from multimodal distributions to non-smooth distributions and learn a new policy given them.