 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDexYCB: A Benchmark for Capturing Hand Grasping of Objects
Apr 09, 2021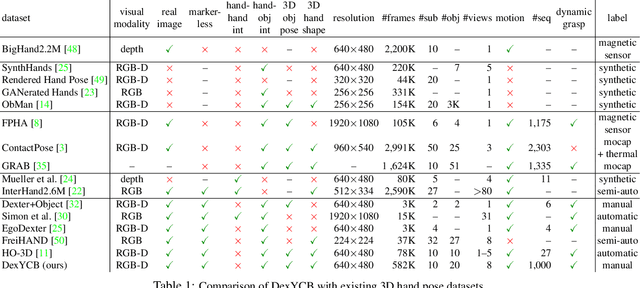

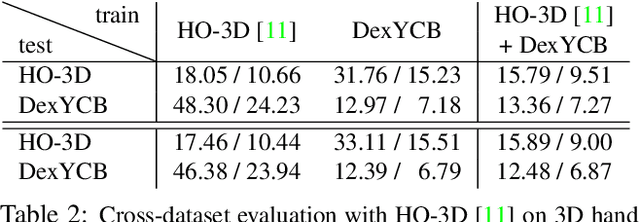

We introduce DexYCB, a new dataset for capturing hand grasping of objects. We first compare DexYCB with a related one through cross-dataset evaluation. We then present a thorough benchmark of state-of-the-art approaches on three relevant tasks: 2D object and keypoint detection, 6D object pose estimation, and 3D hand pose estimation. Finally, we evaluate a new robotics-relevant task: generating safe robot grasps in human-to-robot object handover. Dataset and code are available at https://dex-ycb.github.io.
Learning to Track Instances without Video Annotations
Apr 01, 2021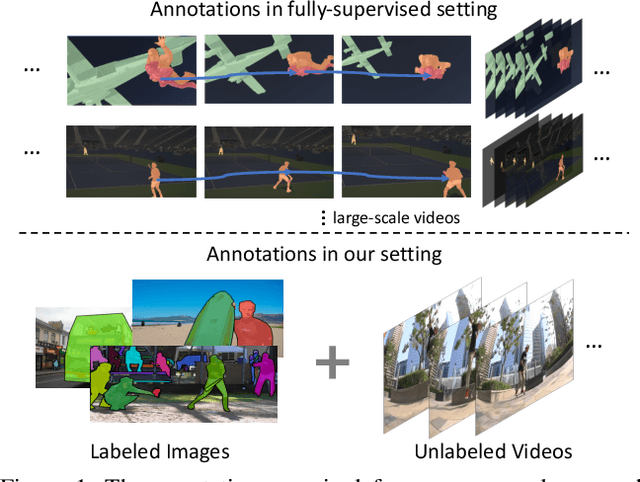

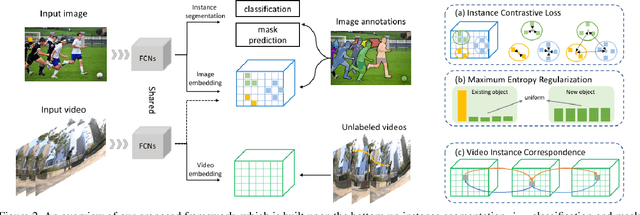

Tracking segmentation masks of multiple instances has been intensively studied, but still faces two fundamental challenges: 1) the requirement of large-scale, frame-wise annotation, and 2) the complexity of two-stage approaches. To resolve these challenges, we introduce a novel semi-supervised framework by learning instance tracking networks with only a labeled image dataset and unlabeled video sequences. With an instance contrastive objective, we learn an embedding to discriminate each instance from the others. We show that even when only trained with images, the learned feature representation is robust to instance appearance variations, and is thus able to track objects steadily across frames. We further enhance the tracking capability of the embedding by learning correspondence from unlabeled videos in a self-supervised manner. In addition, we integrate this module into single-stage instance segmentation and pose estimation frameworks, which significantly reduce the computational complexity of tracking compared to two-stage networks. We conduct experiments on the YouTube-VIS and PoseTrack datasets. Without any video annotation efforts, our proposed method can achieve comparable or even better performance than most fully-supervised methods.
Neural 3D Clothes Retargeting from a Single Image
Jan 29, 2021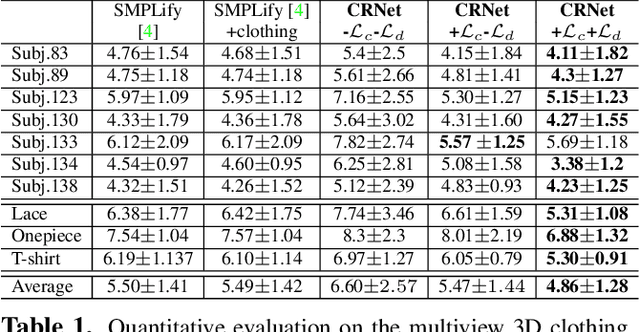

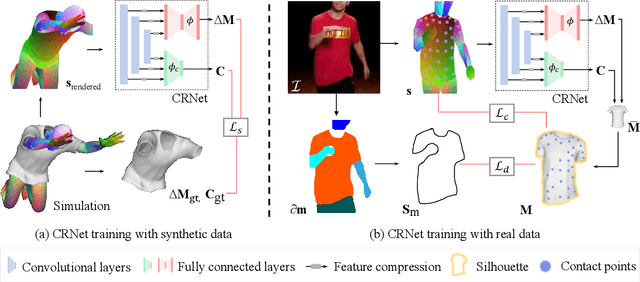
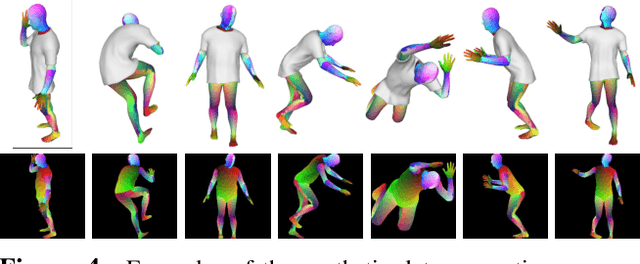
In this paper, we present a method of clothes retargeting; generating the potential poses and deformations of a given 3D clothing template model to fit onto a person in a single RGB image. The problem is fundamentally ill-posed as attaining the ground truth data is impossible, i.e., images of people wearing the different 3D clothing template model at exact same pose. We address this challenge by utilizing large-scale synthetic data generated from physical simulation, allowing us to map 2D dense body pose to 3D clothing deformation. With the simulated data, we propose a semi-supervised learning framework that validates the physical plausibility of the 3D deformation by matching with the prescribed body-to-cloth contact points and clothing silhouette to fit onto the unlabeled real images. A new neural clothes retargeting network (CRNet) is designed to integrate the semi-supervised retargeting task in an end-to-end fashion. In our evaluation, we show that our method can predict the realistic 3D pose and deformation field needed for retargeting clothes models in real-world examples.
Binary TTC: A Temporal Geofence for Autonomous Navigation
Jan 12, 2021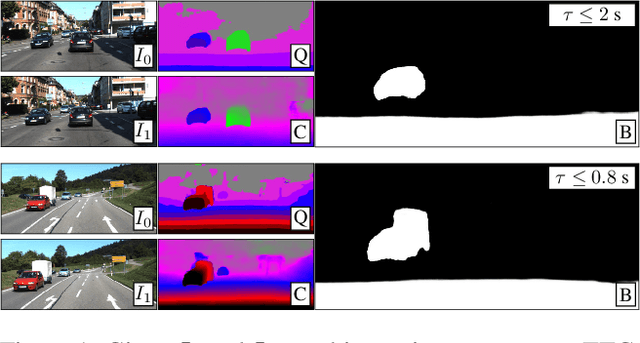
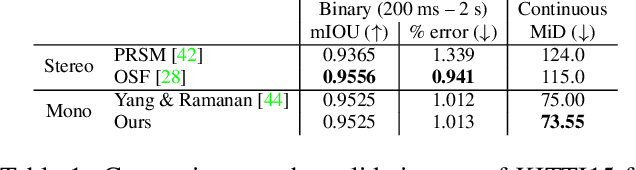

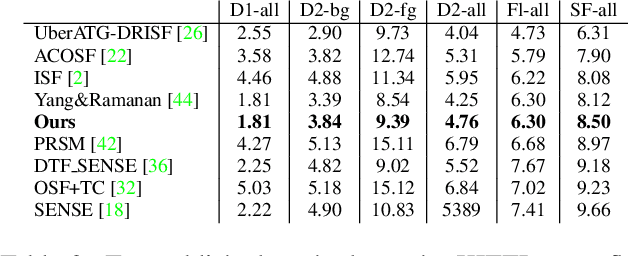
Time-to-contact (TTC), the time for an object to collide with the observer's plane, is a powerful tool for path planning: it is potentially more informative than the depth, velocity, and acceleration of objects in the scene -- even for humans. TTC presents several advantages, including requiring only a monocular, uncalibrated camera. However, regressing TTC for each pixel is not straightforward, and most existing methods make over-simplifying assumptions about the scene. We address this challenge by estimating TTC via a series of simpler, binary classifications. We predict with low latency whether the observer will collide with an obstacle within a certain time, which is often more critical than knowing exact, per-pixel TTC. For such scenarios, our method offers a temporal geofence in 6.4 ms -- over 25x faster than existing methods. Our approach can also estimate per-pixel TTC with arbitrarily fine quantization (including continuous values), when the computational budget allows for it. To the best of our knowledge, our method is the first to offer TTC information (binary or coarsely quantized) at sufficiently high frame-rates for practical use.
Parameter Efficient Multimodal Transformers for Video Representation Learning
Dec 08, 2020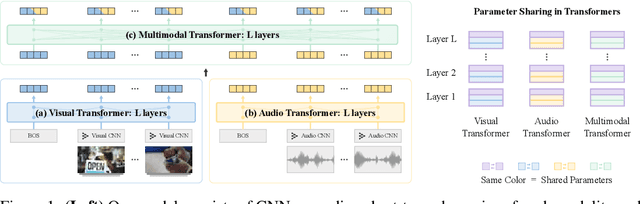


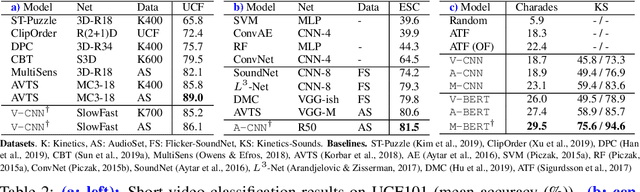
The recent success of Transformers in the language domain has motivated adapting it to a multimodal setting, where a new visual model is trained in tandem with an already pretrained language model. However, due to the excessive memory requirements from Transformers, existing work typically fixes the language model and train only the vision module, which limits its ability to learn cross-modal information in an end-to-end manner. In this work, we focus on reducing the parameters of multimodal Transformers in the context of audio-visual video representation learning. We alleviate the high memory requirement by sharing the weights of Transformers across layers and modalities; we decompose the Transformer into modality-specific and modality-shared parts so that the model learns the dynamics of each modality both individually and together, and propose a novel parameter sharing scheme based on low-rank approximation. We show that our approach reduces parameters up to 80$\%$, allowing us to train our model end-to-end from scratch. We also propose a negative sampling approach based on an instance similarity measured on the CNN embedding space that our model learns with the Transformers. To demonstrate our approach, we pretrain our model on 30-second clips from Kinetics-700 and transfer it to audio-visual classification tasks.
Online Adaptation for Consistent Mesh Reconstruction in the Wild
Dec 06, 2020

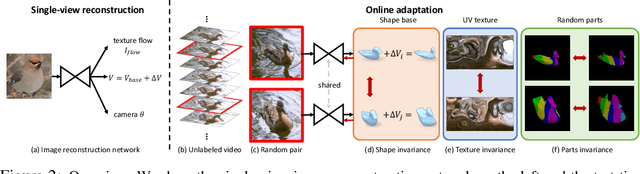
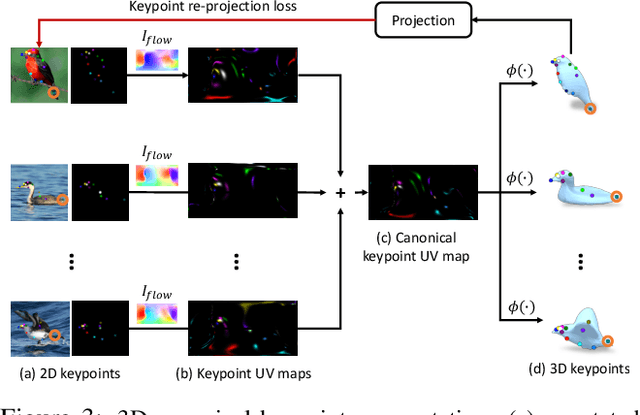
This paper presents an algorithm to reconstruct temporally consistent 3D meshes of deformable object instances from videos in the wild. Without requiring annotations of 3D mesh, 2D keypoints, or camera pose for each video frame, we pose video-based reconstruction as a self-supervised online adaptation problem applied to any incoming test video. We first learn a category-specific 3D reconstruction model from a collection of single-view images of the same category that jointly predicts the shape, texture, and camera pose of an image. Then, at inference time, we adapt the model to a test video over time using self-supervised regularization terms that exploit temporal consistency of an object instance to enforce that all reconstructed meshes share a common texture map, a base shape, as well as parts. We demonstrate that our algorithm recovers temporally consistent and reliable 3D structures from videos of non-rigid objects including those of animals captured in the wild -- an extremely challenging task rarely addressed before.
Displacement-Invariant Cost Computation for Efficient Stereo Matching
Dec 01, 2020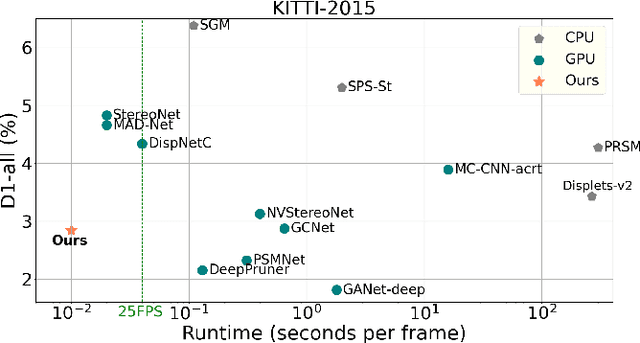

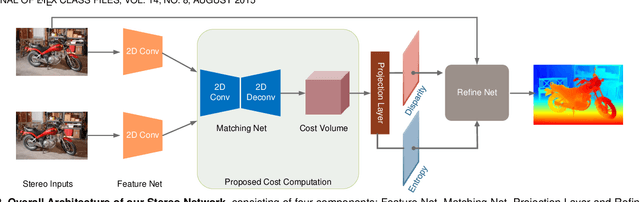
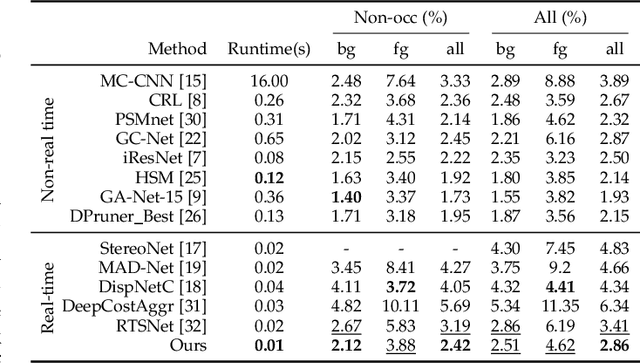
Although deep learning-based methods have dominated stereo matching leaderboards by yielding unprecedented disparity accuracy, their inference time is typically slow, on the order of seconds for a pair of 540p images. The main reason is that the leading methods employ time-consuming 3D convolutions applied to a 4D feature volume. A common way to speed up the computation is to downsample the feature volume, but this loses high-frequency details. To overcome these challenges, we propose a \emph{displacement-invariant cost computation module} to compute the matching costs without needing a 4D feature volume. Rather, costs are computed by applying the same 2D convolution network on each disparity-shifted feature map pair independently. Unlike previous 2D convolution-based methods that simply perform context mapping between inputs and disparity maps, our proposed approach learns to match features between the two images. We also propose an entropy-based refinement strategy to refine the computed disparity map, which further improves speed by avoiding the need to compute a second disparity map on the right image. Extensive experiments on standard datasets (SceneFlow, KITTI, ETH3D, and Middlebury) demonstrate that our method achieves competitive accuracy with much less inference time. On typical image sizes, our method processes over 100 FPS on a desktop GPU, making our method suitable for time-critical applications such as autonomous driving. We also show that our approach generalizes well to unseen datasets, outperforming 4D-volumetric methods.
UFO$^2$: A Unified Framework towards Omni-supervised Object Detection
Oct 21, 2020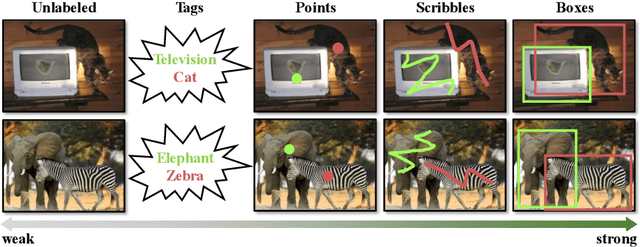


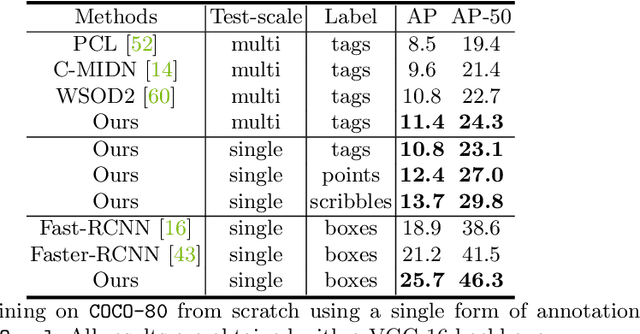
Existing work on object detection often relies on a single form of annotation: the model is trained using either accurate yet costly bounding boxes or cheaper but less expressive image-level tags. However, real-world annotations are often diverse in form, which challenges these existing works. In this paper, we present UFO$^2$, a unified object detection framework that can handle different forms of supervision simultaneously. Specifically, UFO$^2$ incorporates strong supervision (e.g., boxes), various forms of partial supervision (e.g., class tags, points, and scribbles), and unlabeled data. Through rigorous evaluations, we demonstrate that each form of label can be utilized to either train a model from scratch or to further improve a pre-trained model. We also use UFO$^2$ to investigate budget-aware omni-supervised learning, i.e., various annotation policies are studied under a fixed annotation budget: we show that competitive performance needs no strong labels for all data. Finally, we demonstrate the generalization of UFO$^2$, detecting more than 1,000 different objects without bounding box annotations.
NCP-VAE: Variational Autoencoders with Noise Contrastive Priors
Oct 06, 2020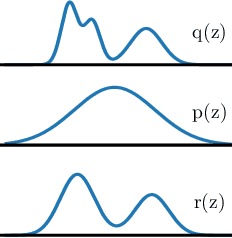
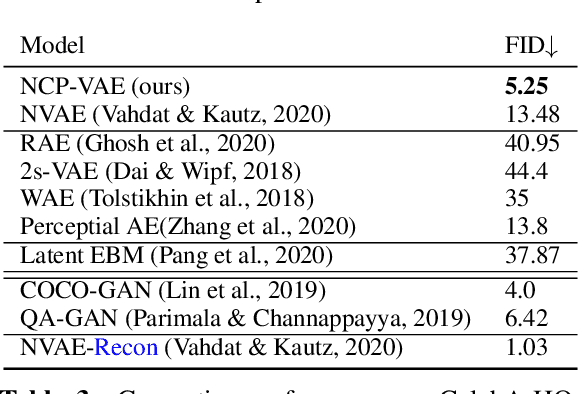
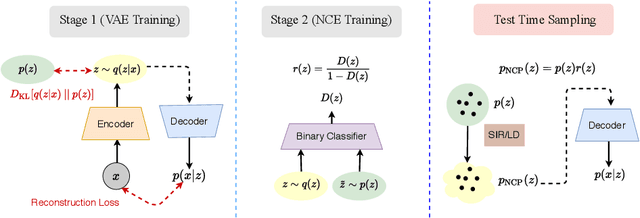

Variational autoencoders (VAEs) are one of the powerful likelihood-based generative models with applications in various domains. However, they struggle to generate high-quality images, especially when samples are obtained from the prior without any tempering. One explanation for VAEs' poor generative quality is the prior hole problem: the prior distribution fails to match the aggregate approximate posterior. Due to this mismatch, there exist areas in the latent space with high density under the prior that do not correspond to any encoded image. Samples from those areas are decoded to corrupted images. To tackle this issue, we propose an energy-based prior defined by the product of a base prior distribution and a reweighting factor, designed to bring the base closer to the aggregate posterior. We train the reweighting factor by noise contrastive estimation, and we generalize it to hierarchical VAEs with many latent variable groups. Our experiments confirm that the proposed noise contrastive priors improve the generative performance of state-of-the-art VAEs by a large margin on the MNIST, CIFAR-10, CelebA 64, and CelebA HQ 256 datasets.
VAEBM: A Symbiosis between Variational Autoencoders and Energy-based Models
Oct 01, 2020
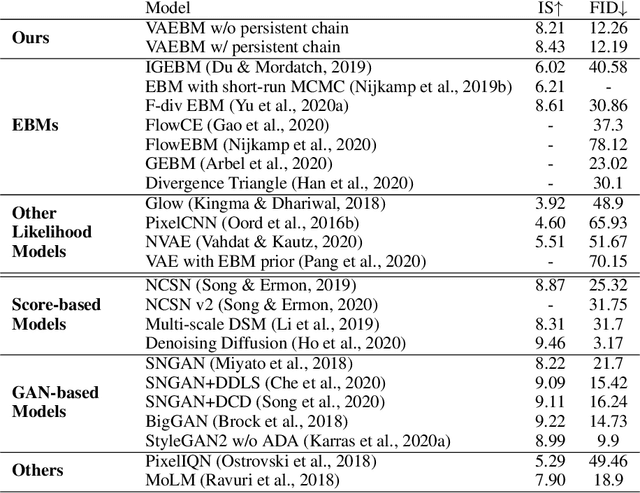


Energy-based models (EBMs) have recently been successful in representing complex distributions of small images. However, sampling from them requires expensive Markov chain Monte Carlo (MCMC) iterations that mix slowly in high dimensional pixel space. Unlike EBMs, variational autoencoders (VAEs) generate samples quickly and are equipped with a latent space that enables fast traversal of the data manifold. However, VAEs tend to assign high probability density to regions in data space outside the actual data distribution and often fail at generating sharp images. In this paper, we propose VAEBM, a symbiotic composition of a VAE and an EBM that offers the best of both worlds. VAEBM captures the overall mode structure of the data distribution using a state-of-the-art VAE and it relies on its EBM component to explicitly exclude non-data-like regions from the model and refine the image samples. Moreover, the VAE component in VAEBM allows us to speed up MCMC updates by reparameterizing them in the VAE's latent space. Our experimental results show that VAEBM outperforms state-of-the-art VAEs and EBMs in generative quality on several benchmark image datasets by a large margin. It can generate high-quality images as large as 256$\times$256 pixels with short MCMC chains. We also demonstrate that VAEBM provides complete mode coverage and performs well in out-of-distribution detection.