 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePressureVision: Estimating Hand Pressure from a Single RGB Image
Mar 19, 2022
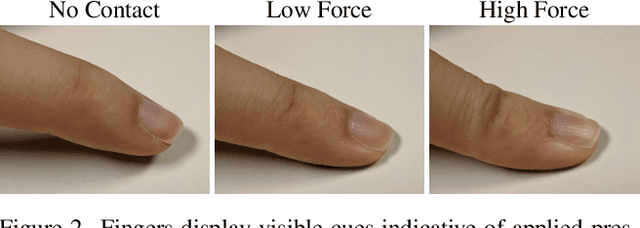
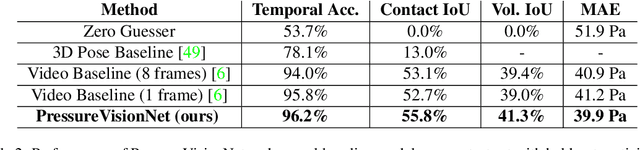
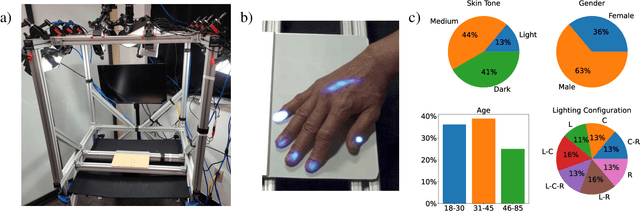
People often interact with their surroundings by applying pressure with their hands. Machine perception of hand pressure has been limited by the challenges of placing sensors between the hand and the contact surface. We explore the possibility of using a conventional RGB camera to infer hand pressure. The central insight is that the application of pressure by a hand results in informative appearance changes. Hands share biomechanical properties that result in similar observable phenomena, such as soft-tissue deformation, blood distribution, hand pose, and cast shadows. We collected videos of 36 participants with diverse skin tone applying pressure to an instrumented planar surface. We then trained a deep model (PressureVisionNet) to infer a pressure image from a single RGB image. Our model infers pressure for participants outside of the training data and outperforms baselines. We also show that the output of our model depends on the appearance of the hand and cast shadows near contact regions. Overall, our results suggest the appearance of a previously unobserved human hand can be used to accurately infer applied pressure.
CoGS: Controllable Generation and Search from Sketch and Style
Mar 17, 2022



We present CoGS, a novel method for the style-conditioned, sketch-driven synthesis of images. CoGS enables exploration of diverse appearance possibilities for a given sketched object, enabling decoupled control over the structure and the appearance of the output. Coarse-grained control over object structure and appearance are enabled via an input sketch and an exemplar "style" conditioning image to a transformer-based sketch and style encoder to generate a discrete codebook representation. We map the codebook representation into a metric space, enabling fine-grained control over selection and interpolation between multiple synthesis options for a given image before generating the image via a vector quantized GAN (VQGAN) decoder. Our framework thereby unifies search and synthesis tasks, in that a sketch and style pair may be used to run an initial synthesis which may be refined via combination with similar results in a search corpus to produce an image more closely matching the user's intent. We show that our model, trained on the 125 object classes of our newly created Pseudosketches dataset, is capable of producing a diverse gamut of semantic content and appearance styles.
MSeg: A Composite Dataset for Multi-domain Semantic Segmentation
Dec 27, 2021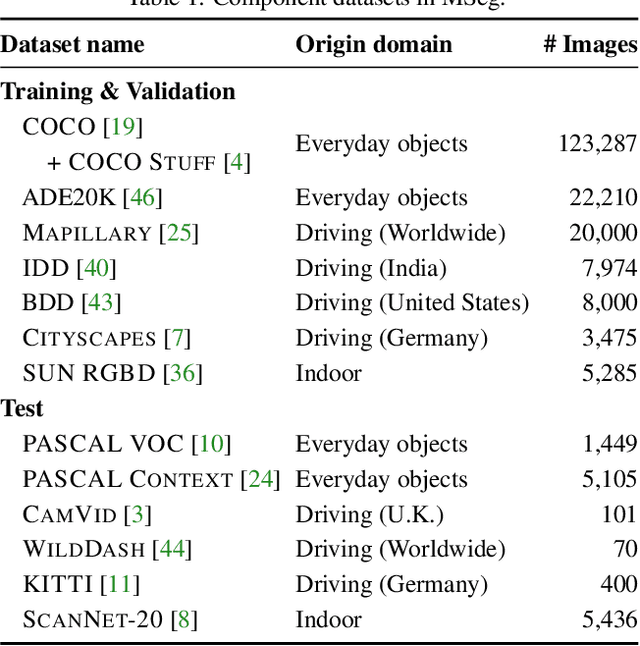
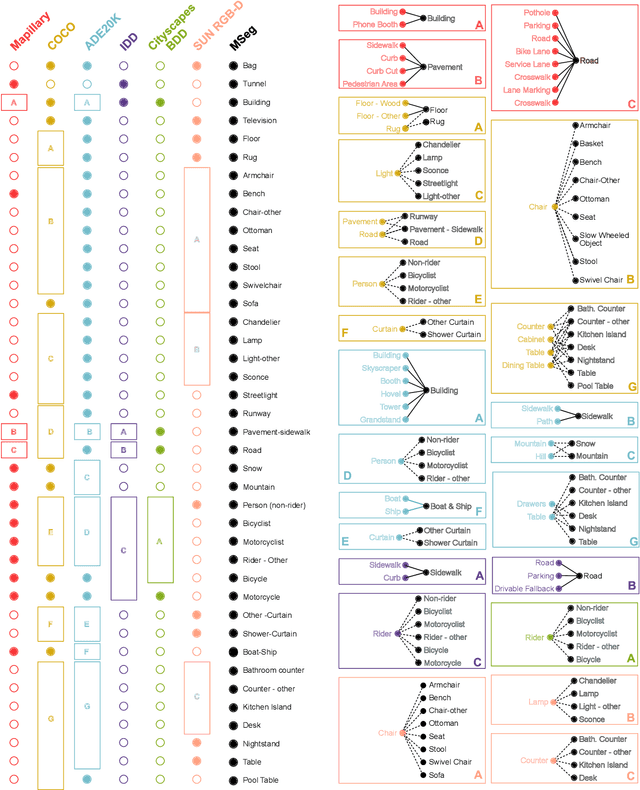
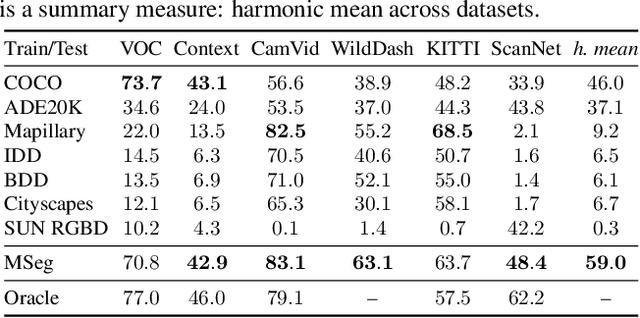
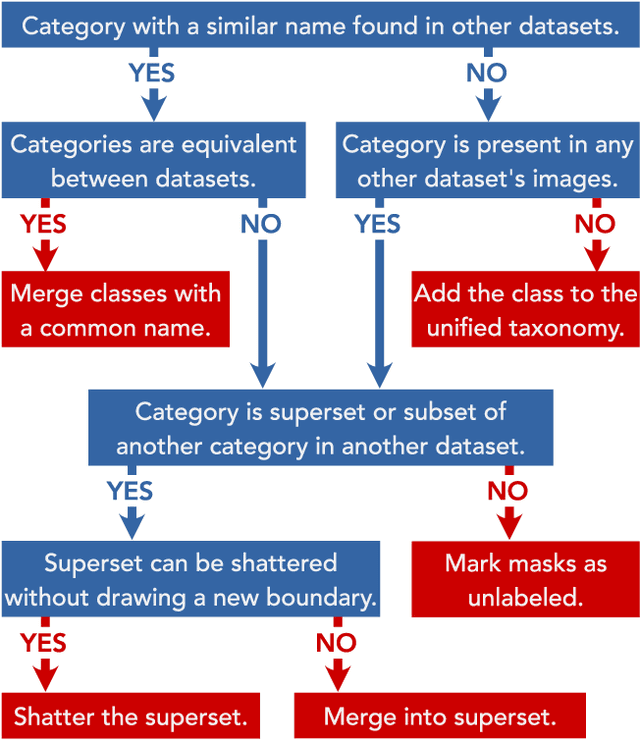
We present MSeg, a composite dataset that unifies semantic segmentation datasets from different domains. A naive merge of the constituent datasets yields poor performance due to inconsistent taxonomies and annotation practices. We reconcile the taxonomies and bring the pixel-level annotations into alignment by relabeling more than 220,000 object masks in more than 80,000 images, requiring more than 1.34 years of collective annotator effort. The resulting composite dataset enables training a single semantic segmentation model that functions effectively across domains and generalizes to datasets that were not seen during training. We adopt zero-shot cross-dataset transfer as a benchmark to systematically evaluate a model's robustness and show that MSeg training yields substantially more robust models in comparison to training on individual datasets or naive mixing of datasets without the presented contributions. A model trained on MSeg ranks first on the WildDash-v1 leaderboard for robust semantic segmentation, with no exposure to WildDash data during training. We evaluate our models in the 2020 Robust Vision Challenge (RVC) as an extreme generalization experiment. MSeg training sets include only three of the seven datasets in the RVC; more importantly, the evaluation taxonomy of RVC is different and more detailed. Surprisingly, our model shows competitive performance and ranks second. To evaluate how close we are to the grand aim of robust, efficient, and complete scene understanding, we go beyond semantic segmentation by training instance segmentation and panoptic segmentation models using our dataset. Moreover, we also evaluate various engineering design decisions and metrics, including resolution and computational efficiency. Although our models are far from this grand aim, our comprehensive evaluation is crucial for progress. We share all the models and code with the community.
PVA: Pixel-aligned Volumetric Avatars
Jan 07, 2021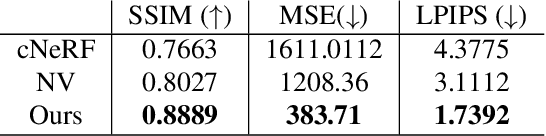
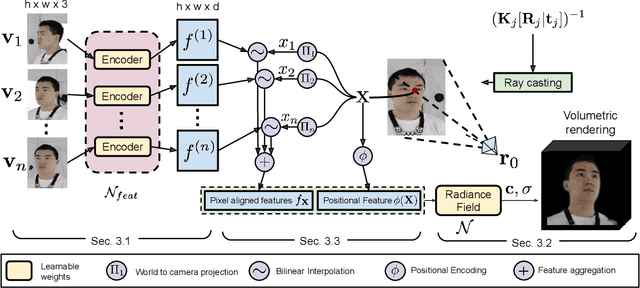


Acquisition and rendering of photo-realistic human heads is a highly challenging research problem of particular importance for virtual telepresence. Currently, the highest quality is achieved by volumetric approaches trained in a person specific manner on multi-view data. These models better represent fine structure, such as hair, compared to simpler mesh-based models. Volumetric models typically employ a global code to represent facial expressions, such that they can be driven by a small set of animation parameters. While such architectures achieve impressive rendering quality, they can not easily be extended to the multi-identity setting. In this paper, we devise a novel approach for predicting volumetric avatars of the human head given just a small number of inputs. We enable generalization across identities by a novel parameterization that combines neural radiance fields with local, pixel-aligned features extracted directly from the inputs, thus sidestepping the need for very deep or complex networks. Our approach is trained in an end-to-end manner solely based on a photometric re-rendering loss without requiring explicit 3D supervision.We demonstrate that our approach outperforms the existing state of the art in terms of quality and is able to generate faithful facial expressions in a multi-identity setting.
ANR: Articulated Neural Rendering for Virtual Avatars
Dec 23, 2020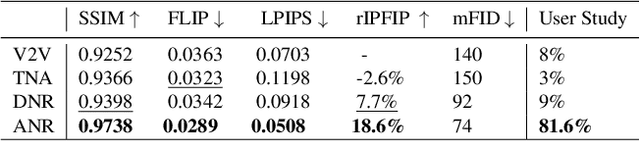
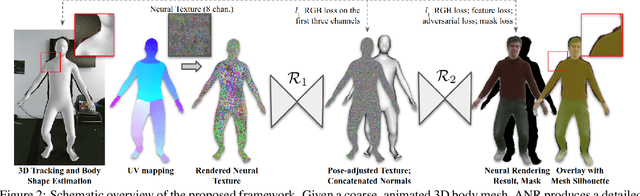
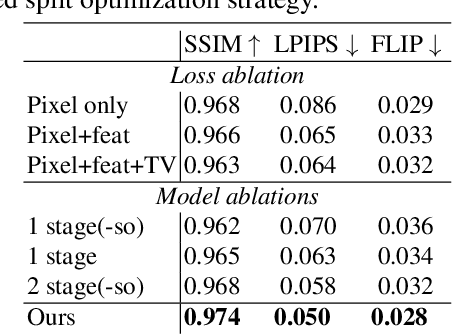
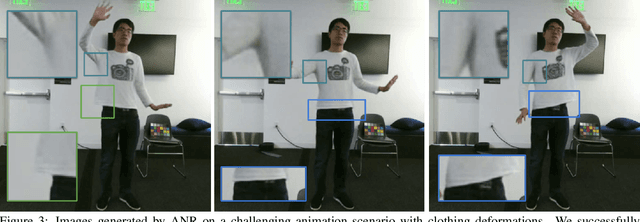
The combination of traditional rendering with neural networks in Deferred Neural Rendering (DNR) provides a compelling balance between computational complexity and realism of the resulting images. Using skinned meshes for rendering articulating objects is a natural extension for the DNR framework and would open it up to a plethora of applications. However, in this case the neural shading step must account for deformations that are possibly not captured in the mesh, as well as alignment inaccuracies and dynamics -- which can confound the DNR pipeline. We present Articulated Neural Rendering (ANR), a novel framework based on DNR which explicitly addresses its limitations for virtual human avatars. We show the superiority of ANR not only with respect to DNR but also with methods specialized for avatar creation and animation. In two user studies, we observe a clear preference for our avatar model and we demonstrate state-of-the-art performance on quantitative evaluation metrics. Perceptually, we observe better temporal stability, level of detail and plausibility.
Scene Flow from Point Clouds with or without Learning
Oct 31, 2020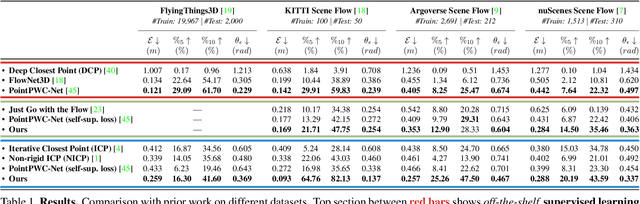
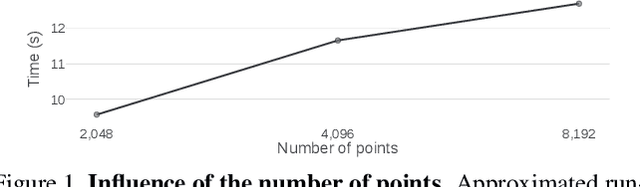
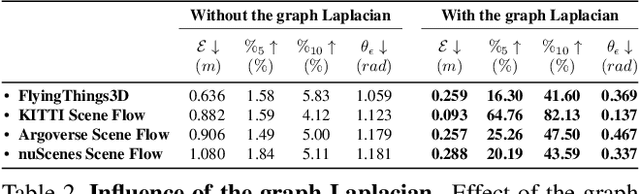
Scene flow is the three-dimensional (3D) motion field of a scene. It provides information about the spatial arrangement and rate of change of objects in dynamic environments. Current learning-based approaches seek to estimate the scene flow directly from point clouds and have achieved state-of-the-art performance. However, supervised learning methods are inherently domain specific and require a large amount of labeled data. Annotation of scene flow on real-world point clouds is expensive and challenging, and the lack of such datasets has recently sparked interest in self-supervised learning methods. How to accurately and robustly learn scene flow representations without labeled real-world data is still an open problem. Here we present a simple and interpretable objective function to recover the scene flow from point clouds. We use the graph Laplacian of a point cloud to regularize the scene flow to be "as-rigid-as-possible". Our proposed objective function can be used with or without learning---as a self-supervisory signal to learn scene flow representations, or as a non-learning-based method in which the scene flow is optimized during runtime. Our approach outperforms related works in many datasets. We also show the immediate applications of our proposed method for two applications: motion segmentation and point cloud densification.
TIDE: A General Toolbox for Identifying Object Detection Errors
Aug 31, 2020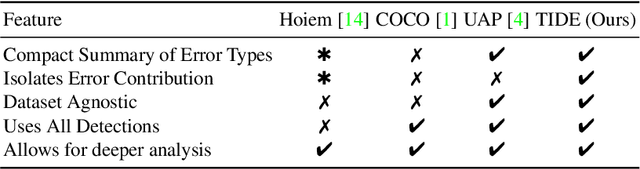
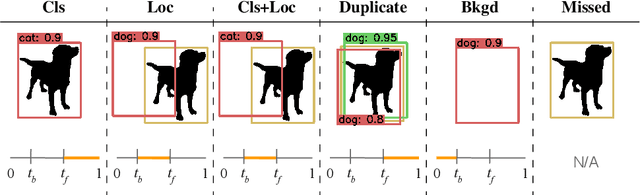
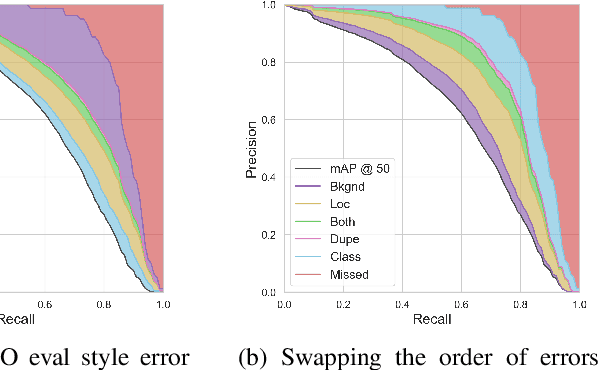
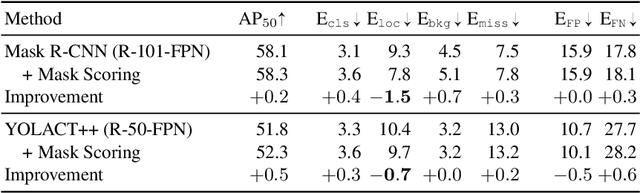
We introduce TIDE, a framework and associated toolbox for analyzing the sources of error in object detection and instance segmentation algorithms. Importantly, our framework is applicable across datasets and can be applied directly to output prediction files without required knowledge of the underlying prediction system. Thus, our framework can be used as a drop-in replacement for the standard mAP computation while providing a comprehensive analysis of each model's strengths and weaknesses. We segment errors into six types and, crucially, are the first to introduce a technique for measuring the contribution of each error in a way that isolates its effect on overall performance. We show that such a representation is critical for drawing accurate, comprehensive conclusions through in-depth analysis across 4 datasets and 7 recognition models. Available at https://dbolya.github.io/tide/
3D for Free: Crossmodal Transfer Learning using HD Maps
Aug 24, 2020
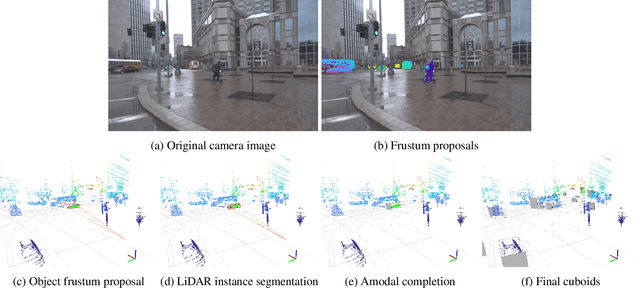

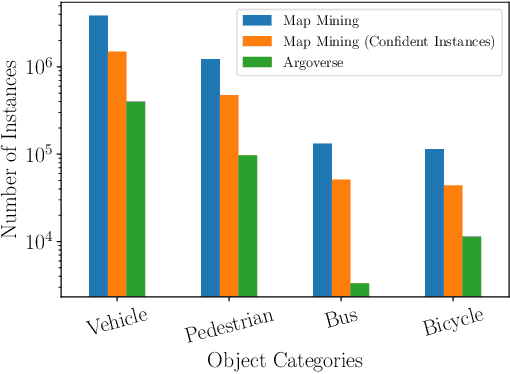
3D object detection is a core perceptual challenge for robotics and autonomous driving. However, the class-taxonomies in modern autonomous driving datasets are significantly smaller than many influential 2D detection datasets. In this work, we address the long-tail problem by leveraging both the large class-taxonomies of modern 2D datasets and the robustness of state-of-the-art 2D detection methods. We proceed to mine a large, unlabeled dataset of images and LiDAR, and estimate 3D object bounding cuboids, seeded from an off-the-shelf 2D instance segmentation model. Critically, we constrain this ill-posed 2D-to-3D mapping by using high-definition maps and object size priors. The result of the mining process is 3D cuboids with varying confidence. This mining process is itself a 3D object detector, although not especially accurate when evaluated as such. However, we then train a 3D object detection model on these cuboids, consistent with other recent observations in the deep learning literature, we find that the resulting model is fairly robust to the noisy supervision that our mining process provides. We mine a collection of 1151 unlabeled, multimodal driving logs from an autonomous vehicle and use the discovered objects to train a LiDAR-based object detector. We show that detector performance increases as we mine more unlabeled data. With our full, unlabeled dataset, our method performs competitively with fully supervised methods, even exceeding the performance for certain object categories, without any human 3D annotations.
ContactPose: A Dataset of Grasps with Object Contact and Hand Pose
Jul 19, 2020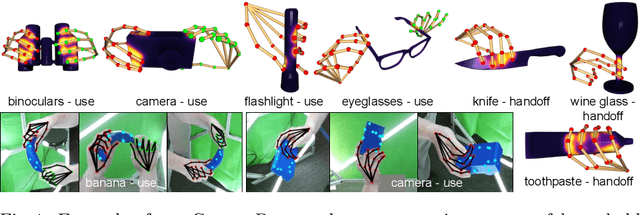
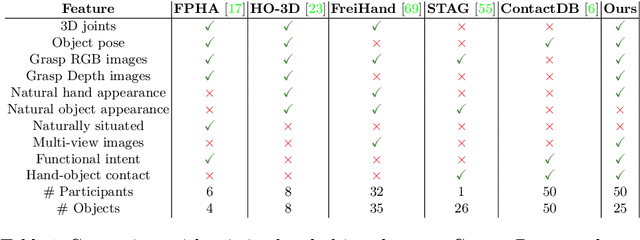
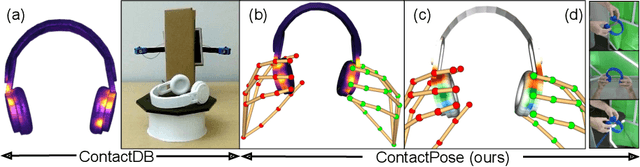
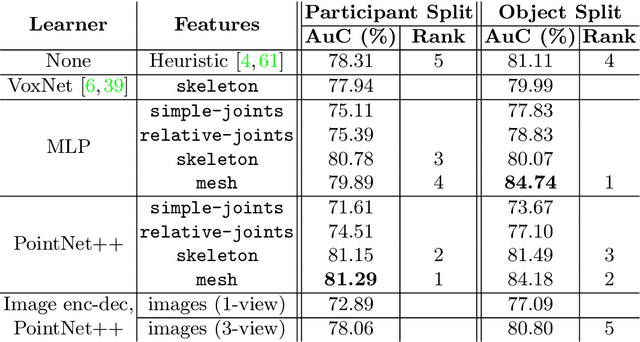
Grasping is natural for humans. However, it involves complex hand configurations and soft tissue deformation that can result in complicated regions of contact between the hand and the object. Understanding and modeling this contact can potentially improve hand models, AR/VR experiences, and robotic grasping. Yet, we currently lack datasets of hand-object contact paired with other data modalities, which is crucial for developing and evaluating contact modeling techniques. We introduce ContactPose, the first dataset of hand-object contact paired with hand pose, object pose, and RGB-D images. ContactPose has 2306 unique grasps of 25 household objects grasped with 2 functional intents by 50 participants, and more than 2.9 M RGB-D grasp images. Analysis of ContactPose data reveals interesting relationships between hand pose and contact. We use this data to rigorously evaluate various data representations, heuristics from the literature, and learning methods for contact modeling. Data, code, and trained models are available at https://contactpose.cc.gatech.edu.
Argoverse: 3D Tracking and Forecasting with Rich Maps
Nov 06, 2019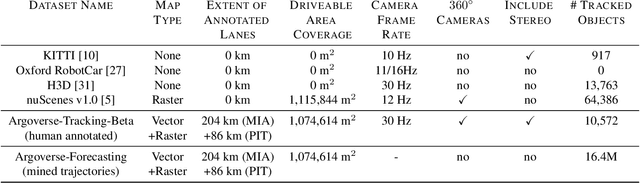

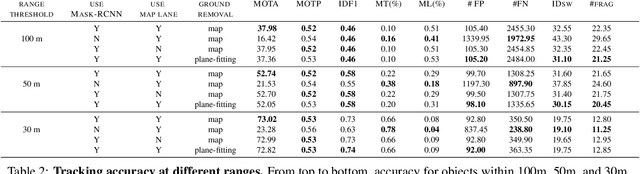
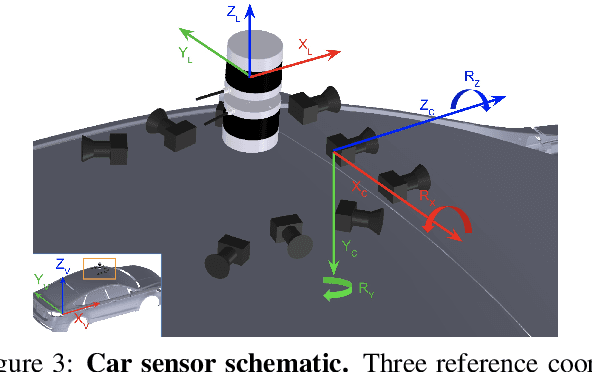
We present Argoverse -- two datasets designed to support autonomous vehicle machine learning tasks such as 3D tracking and motion forecasting. Argoverse was collected by a fleet of autonomous vehicles in Pittsburgh and Miami. The Argoverse 3D Tracking dataset includes 360 degree images from 7 cameras with overlapping fields of view, 3D point clouds from long range LiDAR, 6-DOF pose, and 3D track annotations. Notably, it is the only modern AV dataset that provides forward-facing stereo imagery. The Argoverse Motion Forecasting dataset includes more than 300,000 5-second tracked scenarios with a particular vehicle identified for trajectory forecasting. Argoverse is the first autonomous vehicle dataset to include "HD maps" with 290 km of mapped lanes with geometric and semantic metadata. All data is released under a Creative Commons license at www.argoverse.org. In our baseline experiments, we illustrate how detailed map information such as lane direction, driveable area, and ground height improves the accuracy of 3D object tracking and motion forecasting. Our tracking and forecasting experiments represent only an initial exploration of the use of rich maps in robotic perception. We hope that Argoverse will enable the research community to explore these problems in greater depth.