 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Approach to Simultaneous Acquisition of Real-Time MRI Video, EEG, and Surface EMG for Articulatory, Brain, and Muscle Activity During Speech Production
Mar 05, 2026Speech production is a complex process spanning neural planning, motor control, muscle activation, and articulatory kinematics. While the acoustic speech signal is the most accessible product of the speech production act, it does not directly reveal its causal neurophysiological substrates. We present the first simultaneous acquisition of real-time (dynamic) MRI, EEG, and surface EMG, capturing several key aspects of the speech production chain: brain signals, muscle activations, and articulatory movements. This multimodal acquisition paradigm presents substantial technical challenges, including MRI-induced electromagnetic interference and myogenic artifacts. To mitigate these, we introduce an artifact suppression pipeline tailored to this tri-modal setting. Once fully developed, this framework is poised to offer an unprecedented window into speech neuroscience and insights leading to brain-computer interface advances.
Interpretable Modeling of Articulatory Temporal Dynamics from real-time MRI for Phoneme Recognition
Sep 19, 2025



Real-time Magnetic Resonance Imaging (rtMRI) visualizes vocal tract action, offering a comprehensive window into speech articulation. However, its signals are high dimensional and noisy, hindering interpretation. We investigate compact representations of spatiotemporal articulatory dynamics for phoneme recognition from midsagittal vocal tract rtMRI videos. We compare three feature types: (1) raw video, (2) optical flow, and (3) six linguistically-relevant regions of interest (ROIs) for articulator movements. We evaluate models trained independently on each representation, as well as multi-feature combinations. Results show that multi-feature models consistently outperform single-feature baselines, with the lowest phoneme error rate (PER) of 0.34 obtained by combining ROI and raw video. Temporal fidelity experiments demonstrate a reliance on fine-grained articulatory dynamics, while ROI ablation studies reveal strong contributions from tongue and lips. Our findings highlight how rtMRI-derived features provide accuracy and interpretability, and establish strategies for leveraging articulatory data in speech processing.
Towards disentangling the contributions of articulation and acoustics in multimodal phoneme recognition
May 29, 2025Although many previous studies have carried out multimodal learning with real-time MRI data that captures the audio-visual kinematics of the vocal tract during speech, these studies have been limited by their reliance on multi-speaker corpora. This prevents such models from learning a detailed relationship between acoustics and articulation due to considerable cross-speaker variability. In this study, we develop unimodal audio and video models as well as multimodal models for phoneme recognition using a long-form single-speaker MRI corpus, with the goal of disentangling and interpreting the contributions of each modality. Audio and multimodal models show similar performance on different phonetic manner classes but diverge on places of articulation. Interpretation of the models' latent space shows similar encoding of the phonetic space across audio and multimodal models, while the models' attention weights highlight differences in acoustic and articulatory timing for certain phonemes.
TIDE: A General Toolbox for Identifying Object Detection Errors
Aug 31, 2020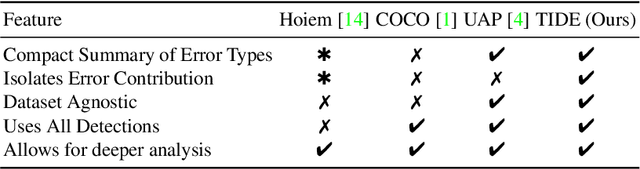
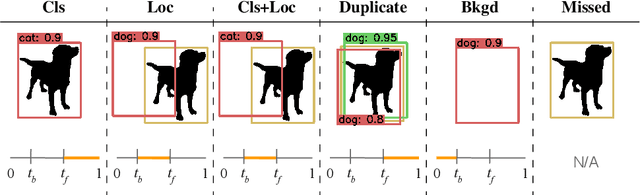
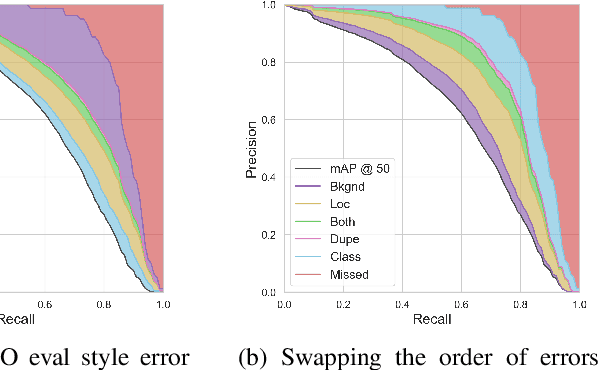
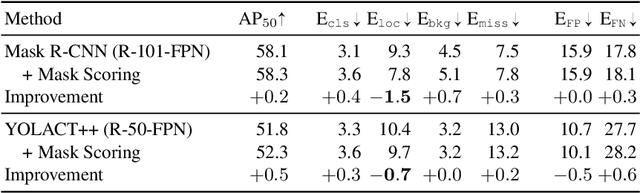
We introduce TIDE, a framework and associated toolbox for analyzing the sources of error in object detection and instance segmentation algorithms. Importantly, our framework is applicable across datasets and can be applied directly to output prediction files without required knowledge of the underlying prediction system. Thus, our framework can be used as a drop-in replacement for the standard mAP computation while providing a comprehensive analysis of each model's strengths and weaknesses. We segment errors into six types and, crucially, are the first to introduce a technique for measuring the contribution of each error in a way that isolates its effect on overall performance. We show that such a representation is critical for drawing accurate, comprehensive conclusions through in-depth analysis across 4 datasets and 7 recognition models. Available at https://dbolya.github.io/tide/