 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoordinated Heterogeneous Distributed Perception based on Latent Space Representation
Sep 12, 2018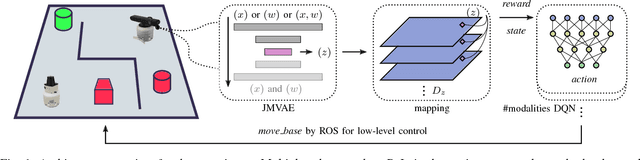
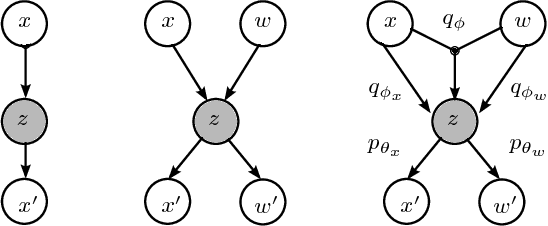
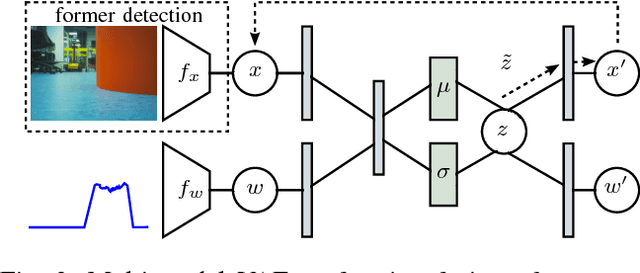
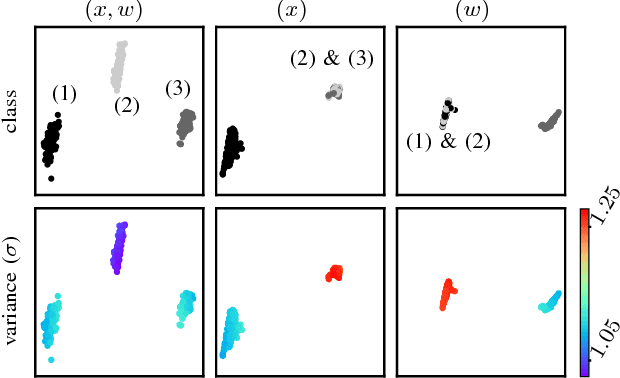
We investigate a reinforcement approach for distributed sensing based on the latent space derived from multi-modal deep generative models. Our contribution provides insights to the following benefits: Detections can be exchanged effectively between robots equipped with uni-modal sensors due to a shared latent representation of information that is trained by a Variational Auto Encoder (VAE). Sensor-fusion can be applied asynchronously due to the generative feature of the VAE. Deep Q-Networks (DQNs) are trained to minimize uncertainty in latent space by coordinating robots to a Point-of-Interest (PoI) where their sensor modality can provide beneficial information about the PoI. Additionally, we show that the decrease in uncertainty can be defined as the direct reward signal for training the DQN.
Adversarial Discriminative Sim-to-real Transfer of Visuo-motor Policies
May 31, 2018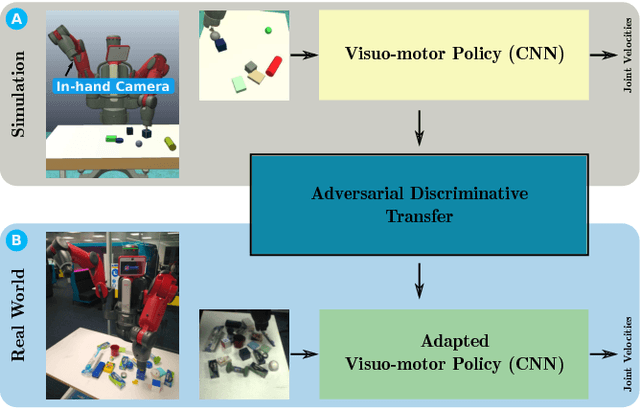

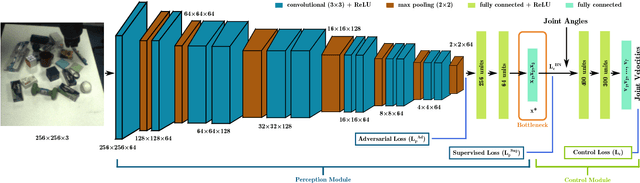
Various approaches have been proposed to learn visuo-motor policies for real-world robotic applications. One solution is first learning in simulation then transferring to the real world. In the transfer, most existing approaches need real-world images with labels. However, the labelling process is often expensive or even impractical in many robotic applications. In this paper, we propose an adversarial discriminative sim-to-real transfer approach to reduce the cost of labelling real data. The effectiveness of the approach is demonstrated with modular networks in a table-top object reaching task where a 7 DoF arm is controlled in velocity mode to reach a blue cuboid in clutter through visual observations. The adversarial transfer approach reduced the labelled real data requirement by 50%. Policies can be transferred to real environments with only 93 labelled and 186 unlabelled real images. The transferred visuo-motor policies are robust to novel (not seen in training) objects in clutter and even a moving target, achieving a 97.8% success rate and 1.8 cm control accuracy.
Closing the Loop for Robotic Grasping: A Real-time, Generative Grasp Synthesis Approach
May 15, 2018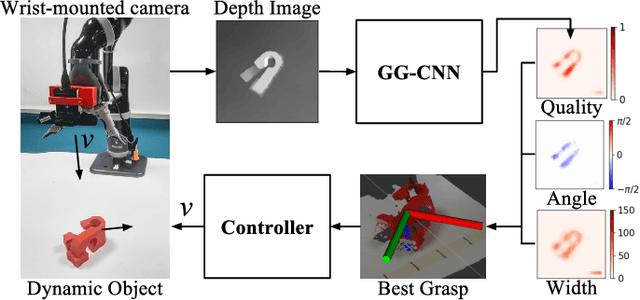
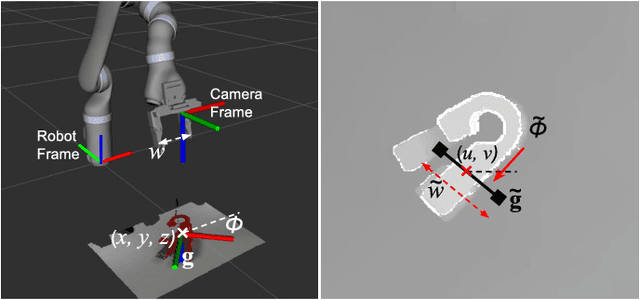
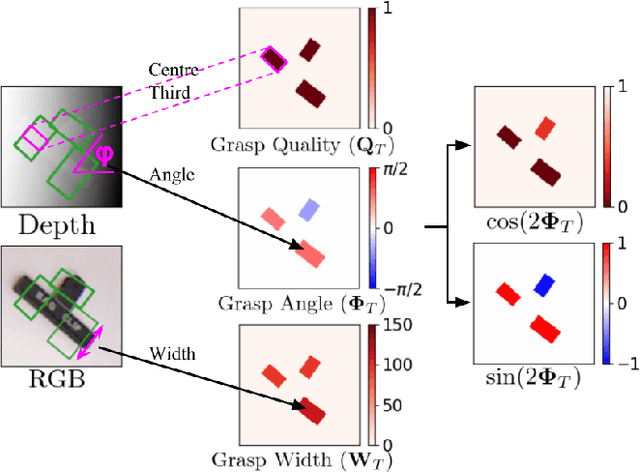
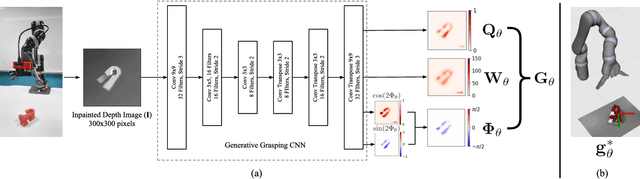
This paper presents a real-time, object-independent grasp synthesis method which can be used for closed-loop grasping. Our proposed Generative Grasping Convolutional Neural Network (GG-CNN) predicts the quality and pose of grasps at every pixel. This one-to-one mapping from a depth image overcomes limitations of current deep-learning grasping techniques by avoiding discrete sampling of grasp candidates and long computation times. Additionally, our GG-CNN is orders of magnitude smaller while detecting stable grasps with equivalent performance to current state-of-the-art techniques. The light-weight and single-pass generative nature of our GG-CNN allows for closed-loop control at up to 50Hz, enabling accurate grasping in non-static environments where objects move and in the presence of robot control inaccuracies. In our real-world tests, we achieve an 83% grasp success rate on a set of previously unseen objects with adversarial geometry and 88% on a set of household objects that are moved during the grasp attempt. We also achieve 81% accuracy when grasping in dynamic clutter.
The Limits and Potentials of Deep Learning for Robotics
Apr 18, 2018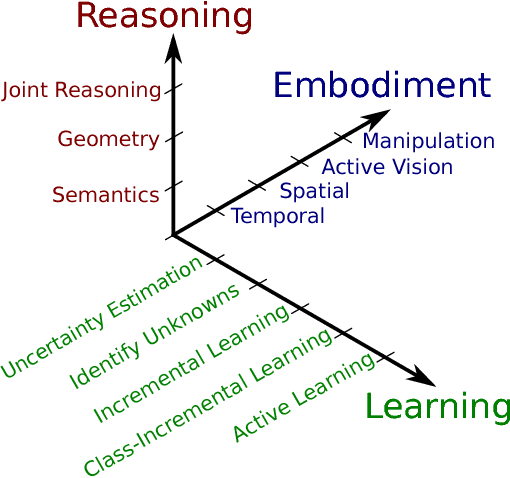

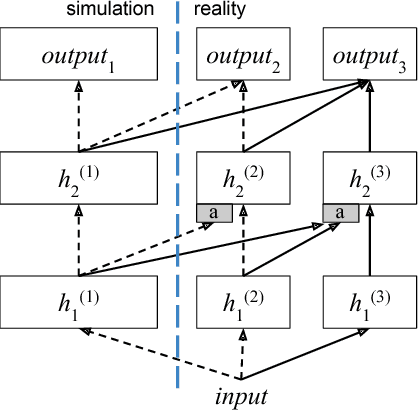

The application of deep learning in robotics leads to very specific problems and research questions that are typically not addressed by the computer vision and machine learning communities. In this paper we discuss a number of robotics-specific learning, reasoning, and embodiment challenges for deep learning. We explain the need for better evaluation metrics, highlight the importance and unique challenges for deep robotic learning in simulation, and explore the spectrum between purely data-driven and model-driven approaches. We hope this paper provides a motivating overview of important research directions to overcome the current limitations, and help fulfill the promising potentials of deep learning in robotics.
Modular Deep Q Networks for Sim-to-real Transfer of Visuo-motor Policies
Dec 19, 2017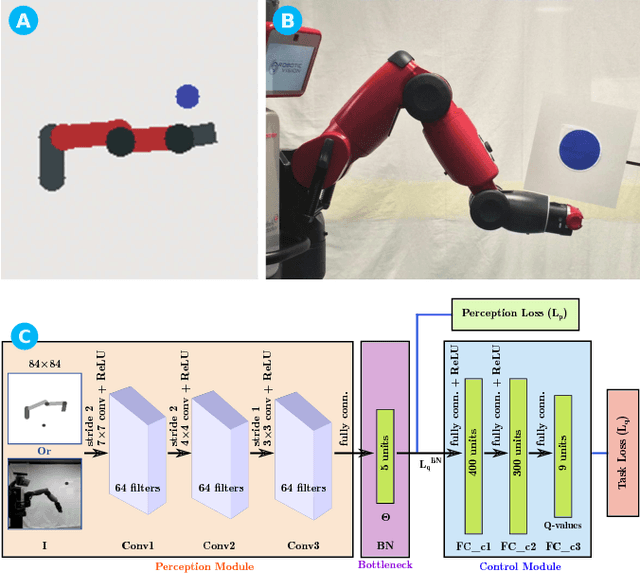
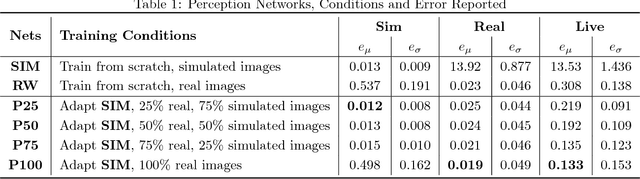


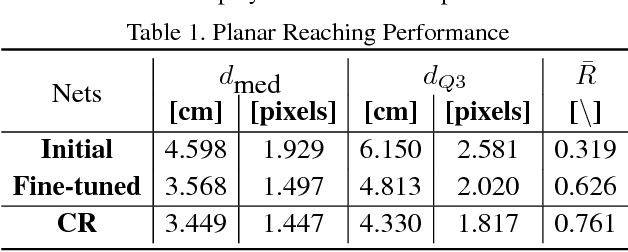
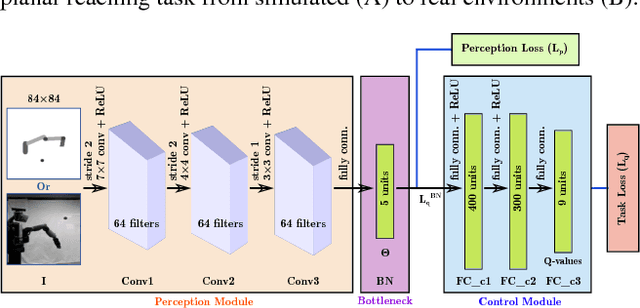
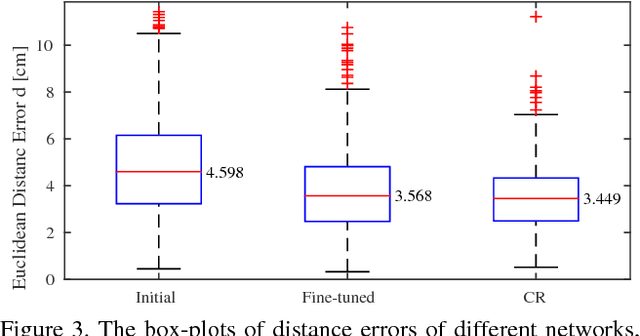
While deep learning has had significant successes in computer vision thanks to the abundance of visual data, collecting sufficiently large real-world datasets for robot learning can be costly. To increase the practicality of these techniques on real robots, we propose a modular deep reinforcement learning method capable of transferring models trained in simulation to a real-world robotic task. We introduce a bottleneck between perception and control, enabling the networks to be trained independently, but then merged and fine-tuned in an end-to-end manner to further improve hand-eye coordination. On a canonical, planar visually-guided robot reaching task a fine-tuned accuracy of 1.6 pixels is achieved, a significant improvement over naive transfer (17.5 pixels), showing the potential for more complicated and broader applications. Our method provides a technique for more efficient learning and transfer of visuo-motor policies for real robotic systems without relying entirely on large real-world robot datasets.
* Australasian Conference on Robotics and Automation (ACRA) 2017, Student Paper Award Finalist
Visual Servoing from Deep Neural Networks
Jun 07, 2017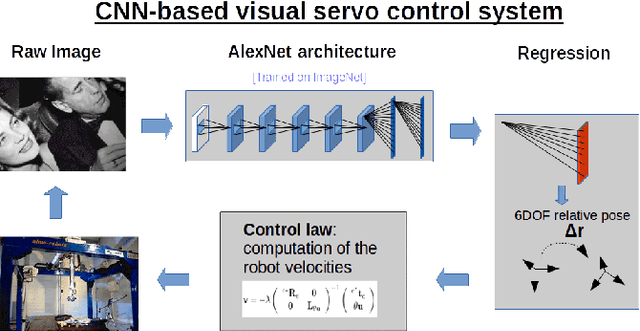
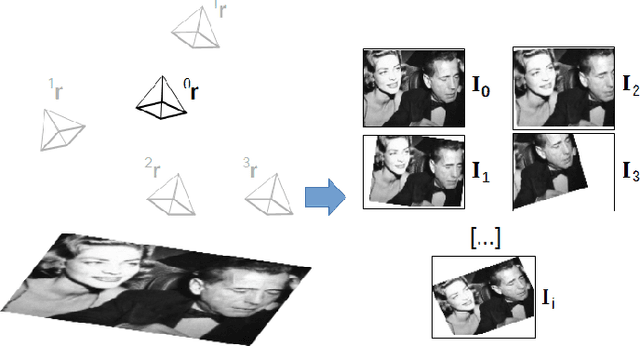

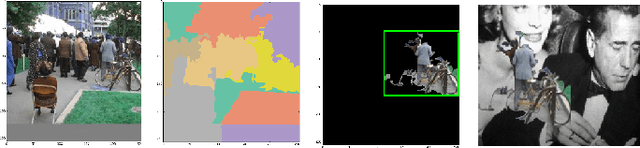
We present a deep neural network-based method to perform high-precision, robust and real-time 6 DOF visual servoing. The paper describes how to create a dataset simulating various perturbations (occlusions and lighting conditions) from a single real-world image of the scene. A convolutional neural network is fine-tuned using this dataset to estimate the relative pose between two images of the same scene. The output of the network is then employed in a visual servoing control scheme. The method converges robustly even in difficult real-world settings with strong lighting variations and occlusions.A positioning error of less than one millimeter is obtained in experiments with a 6 DOF robot.
Richardson-Lucy Deblurring for Moving Light Field Cameras
May 19, 2017
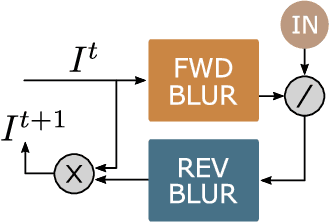


We generalize Richardson-Lucy (RL) deblurring to 4-D light fields by replacing the convolution steps with light field rendering of motion blur. The method deals correctly with blur caused by 6-degree-of-freedom camera motion in complex 3-D scenes, without performing depth estimation. We introduce a novel regularization term that maintains parallax information in the light field while reducing noise and ringing. We demonstrate the method operating effectively on rendered scenes and scenes captured using an off-the-shelf light field camera. An industrial robot arm provides repeatable and known trajectories, allowing us to establish quantitative performance in complex 3-D scenes. Qualitative and quantitative results confirm the effectiveness of the method, including commonly occurring cases for which previously published methods fail. We include mathematical proof that the algorithm converges to the maximum-likelihood estimate of the unblurred scene under Poisson noise. We expect extension to blind methods to be possible following the generalization of 2-D Richardson-Lucy to blind deconvolution.
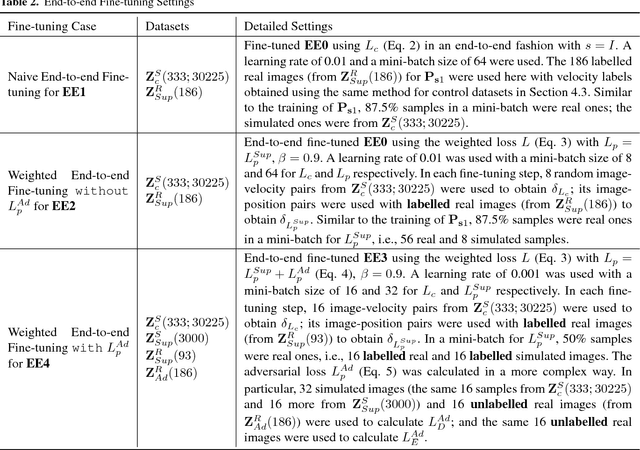
Tuning Modular Networks with Weighted Losses for Hand-Eye Coordination
May 15, 2017
This paper introduces an end-to-end fine-tuning method to improve hand-eye coordination in modular deep visuo-motor policies (modular networks) where each module is trained independently. Benefiting from weighted losses, the fine-tuning method significantly improves the performance of the policies for a robotic planar reaching task.
What Would You Do? Acting by Learning to Predict
Mar 08, 2017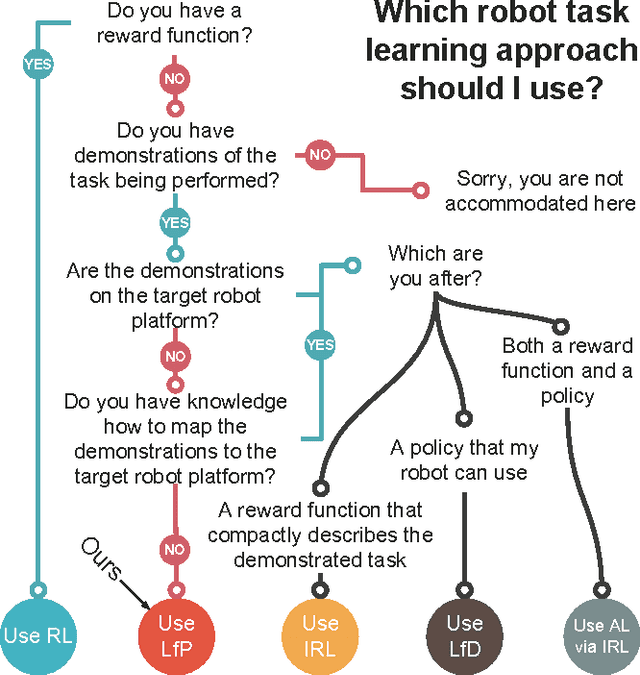

We propose to learn tasks directly from visual demonstrations by learning to predict the outcome of human and robot actions on an environment. We enable a robot to physically perform a human demonstrated task without knowledge of the thought processes or actions of the human, only their visually observable state transitions. We evaluate our approach on two table-top, object manipulation tasks and demonstrate generalisation to previously unseen states. Our approach reduces the priors required to implement a robot task learning system compared with the existing approaches of Learning from Demonstration, Reinforcement Learning and Inverse Reinforcement Learning.
The ACRV Picking Benchmark : A Robotic Shelf Picking Benchmark to Foster Reproducible Research
Dec 14, 2016



Robotic challenges like the Amazon Picking Challenge (APC) or the DARPA Challenges are an established and important way to drive scientific progress. They make research comparable on a well-defined benchmark with equal test conditions for all participants. However, such challenge events occur only occasionally, are limited to a small number of contestants, and the test conditions are very difficult to replicate after the main event. We present a new physical benchmark challenge for robotic picking: the ACRV Picking Benchmark (APB). Designed to be reproducible, it consists of a set of 42 common objects, a widely available shelf, and exact guidelines for object arrangement using stencils. A well-defined evaluation protocol enables the comparison of \emph{complete} robotic systems -- including perception and manipulation -- instead of sub-systems only. Our paper also describes and reports results achieved by an open baseline system based on a Baxter robot.