 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutonomous Sweet Pepper Harvesting for Protected Cropping Systems
Jun 07, 2017
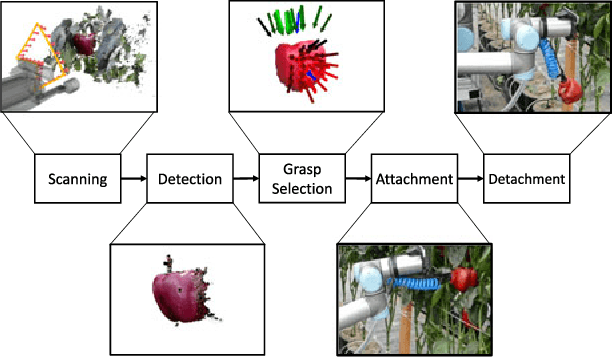
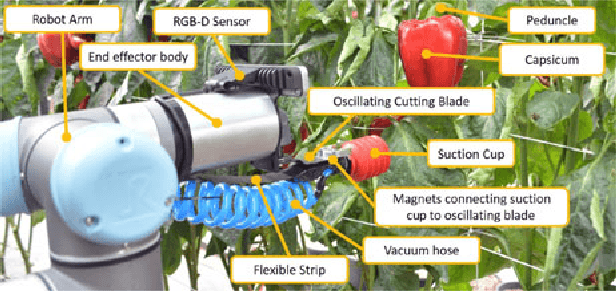
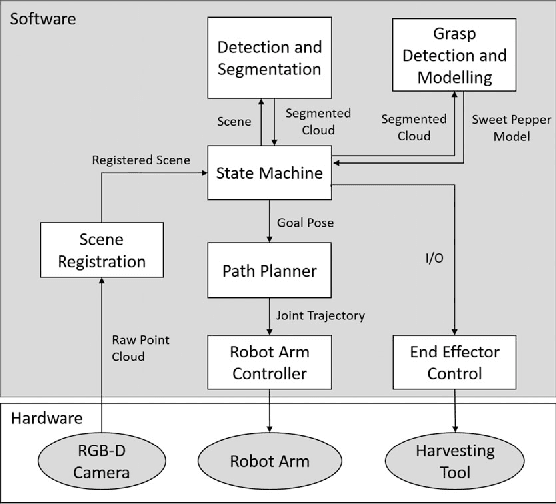
In this letter, we present a new robotic harvester (Harvey) that can autonomously harvest sweet pepper in protected cropping environments. Our approach combines effective vision algorithms with a novel end-effector design to enable successful harvesting of sweet peppers. Initial field trials in protected cropping environments, with two cultivar, demonstrate the efficacy of this approach achieving a 46% success rate for unmodified crop, and 58% for modified crop. Furthermore, for the more favourable cultivar we were also able to detach 90% of sweet peppers, indicating that improvements in the grasping success rate would result in greatly improved harvesting performance.
What Would You Do? Acting by Learning to Predict
Mar 08, 2017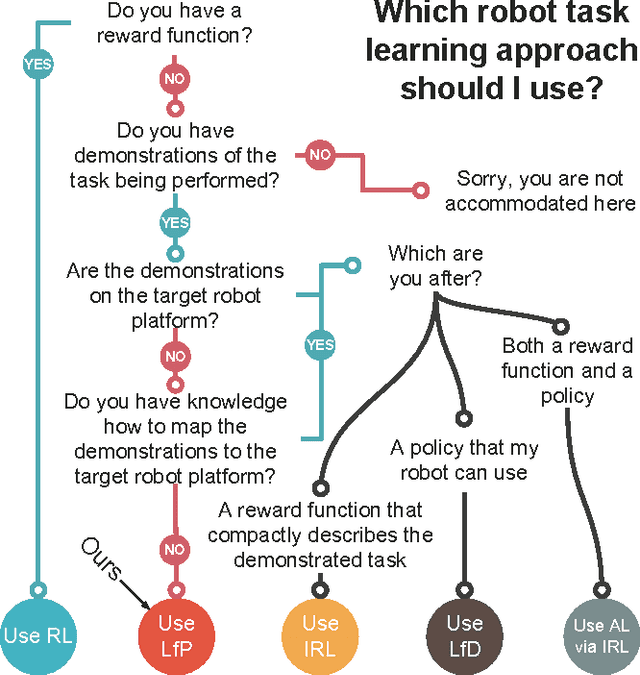

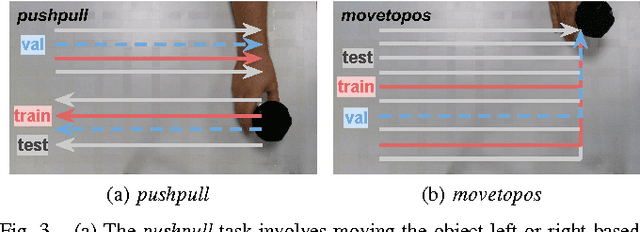
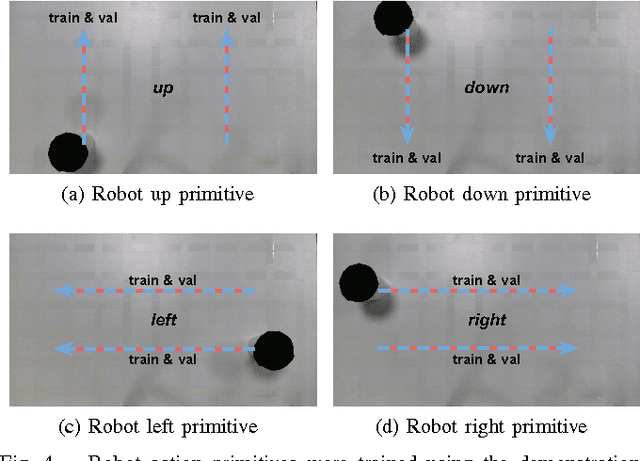
We propose to learn tasks directly from visual demonstrations by learning to predict the outcome of human and robot actions on an environment. We enable a robot to physically perform a human demonstrated task without knowledge of the thought processes or actions of the human, only their visually observable state transitions. We evaluate our approach on two table-top, object manipulation tasks and demonstrate generalisation to previously unseen states. Our approach reduces the priors required to implement a robot task learning system compared with the existing approaches of Learning from Demonstration, Reinforcement Learning and Inverse Reinforcement Learning.